理解Transformer和注意力机制基本原理
简单理解Transformer和注意力机制基本原理
论文下载地址:
Attention Is All You Need
1. Transformer为什么这么强?
完全摆脱 RNN/CNN,只依赖注意力机制(Attention)来建模序列中的依赖关系。
1.1 注意力机制让模型能捕捉任意距离的依赖
- 传统 RNN:词间距离越远,信息越难传递
- Transformer:一步通过 Attention 就能让“第一个词”关注到“最后一个词”
1.2 完全并行化,更快
- RNN 必须按顺序处理:t1 → t2 → t3 → …
- Transformer 全部输入一次性计算,所以可以大规模并行(特别适合 GPU/TPU)。
1.3 多头注意力让模型表达能力极强
多个注意力头 = 多个不同的理解视角,让模型更加丰富多样。
2. 编码器和解码器/Encoder-Decoder架构
Transformer由两部分组成:
- 编码器
- 解码器(GPT就是纯解码器)
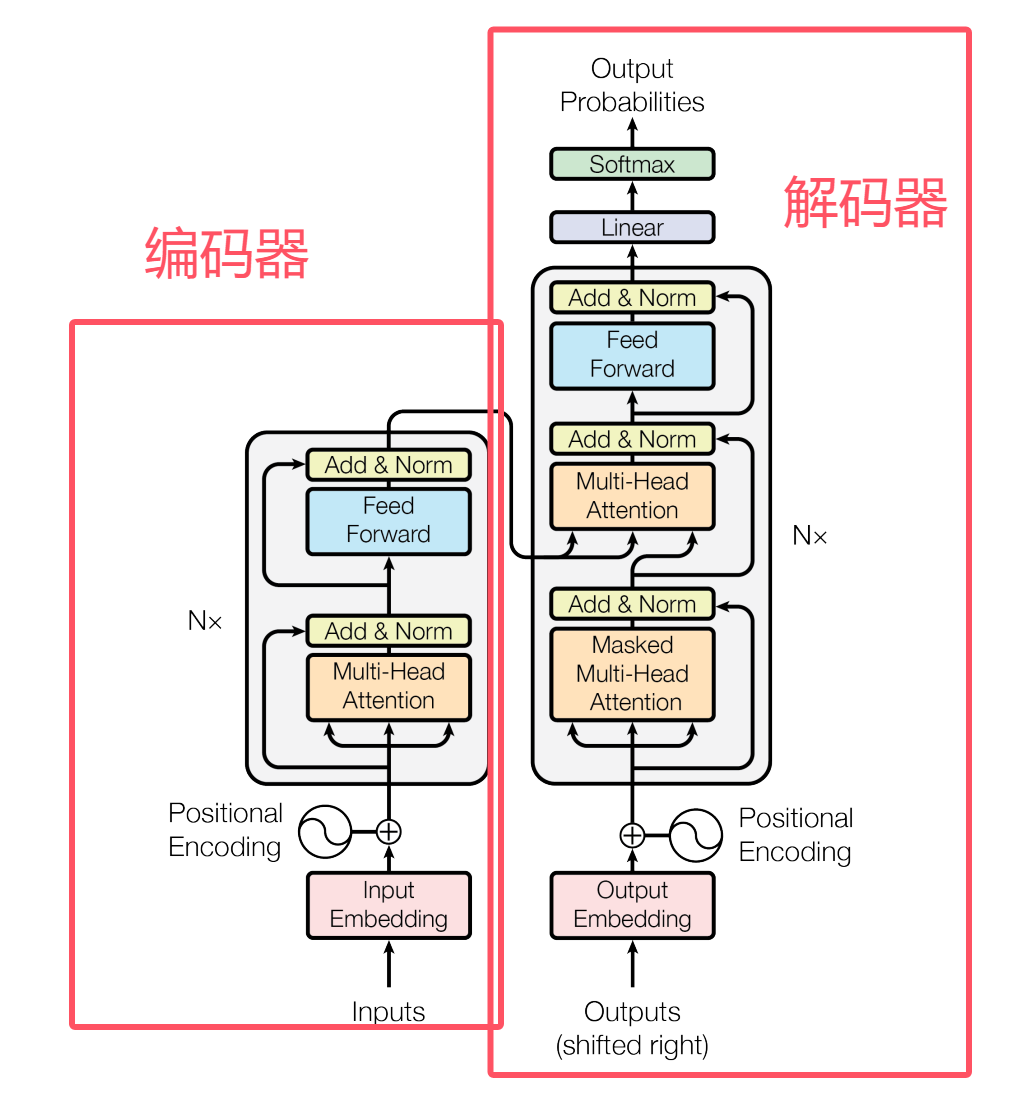
2.1 Encoder —— 负责“把输入句子变成深层语义表示”
编码器的工作是:
通过多层Self-Attention,把一句话从“表层的词”转换为“深层语义向量表示”。
A. Self-Attention —— 学习词与词之间的关系
例如输入:
1 | |
Self-Attention 会计算:
- “小明”与“踢”的关系
- “踢”与“给”的关系
- “球”在句子中属于宾语
- “小红”是接收者
也就是让模型理解谁对谁重要。
B. Multi-Head Attention —— 不同角度的语义抽取
多个注意力头像多个“理解维度”:
- 一个头关注语法
- 一个头关注指代
- 一个头关注动作
- 一个头关注对象
然后把这些不同理解拼接起来。
C. Feed Forward Network(前馈网络)
每一层 Encoder 都在 Attention 后加上 FFN,用来:
- 增强非线性表达
- 提炼信息
- 提高模型的抽象能力
再加上:
- 残差连接(Residual)——避免梯度消失
- LayerNorm——稳定训练
- 位置编码——补充顺序信息
所以 Encoder 的最终结果是:
- 把整句输入变成一串蕴含丰富上下文关系的语义向量(Contextual Embeddings)。
2️.2 Decoder —— 负责“根据语义向量逐步生成输出”
A. Masked Self-Attention(掩码自注意力) —— 不能偷看未来词
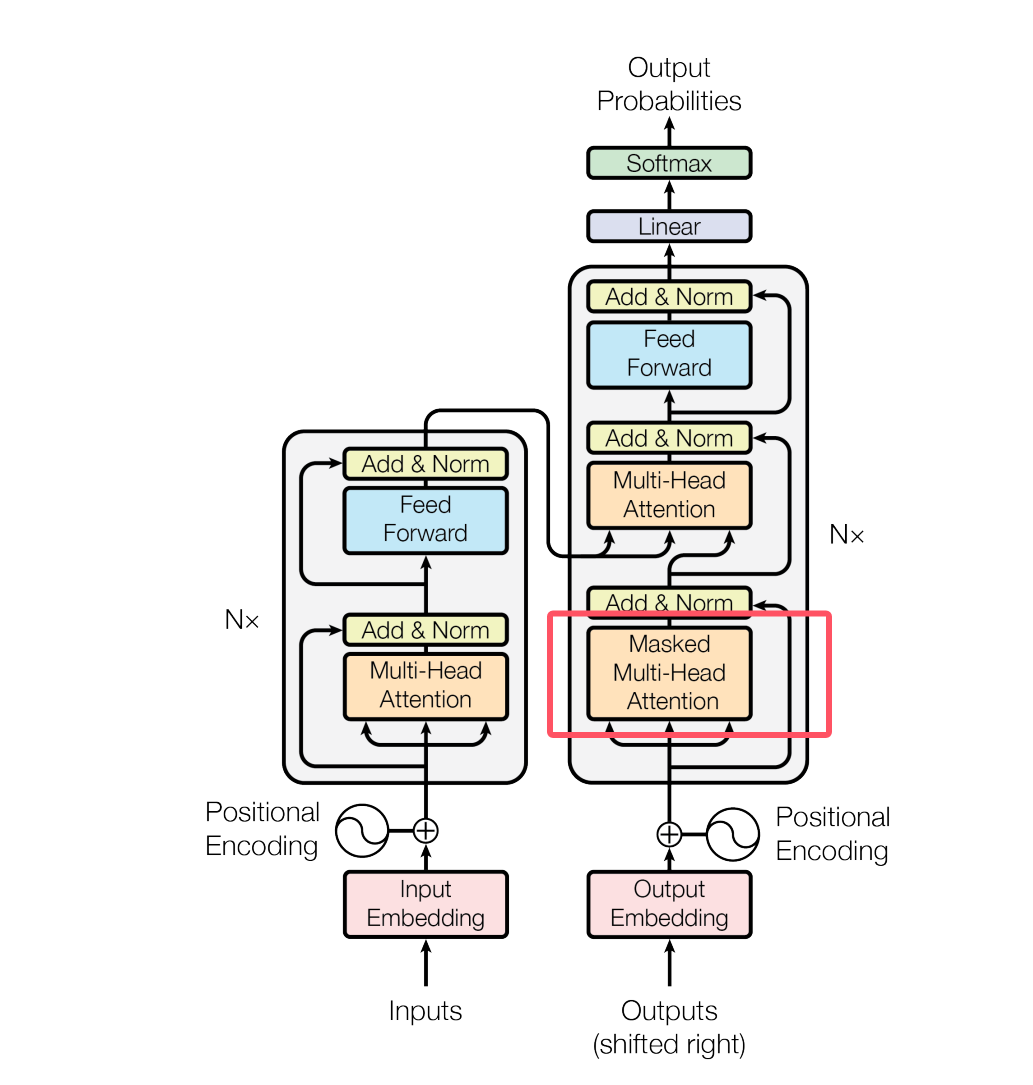
Decoder 在生成句子时:
第一个词 → 第二个词 → 第三个词 …
每一步都只能依赖已生成内容,而不能看到未来词。
这叫:Masked Multi-Head Self-Attention
它保证模型生成时符合“从左到右”的逻辑。
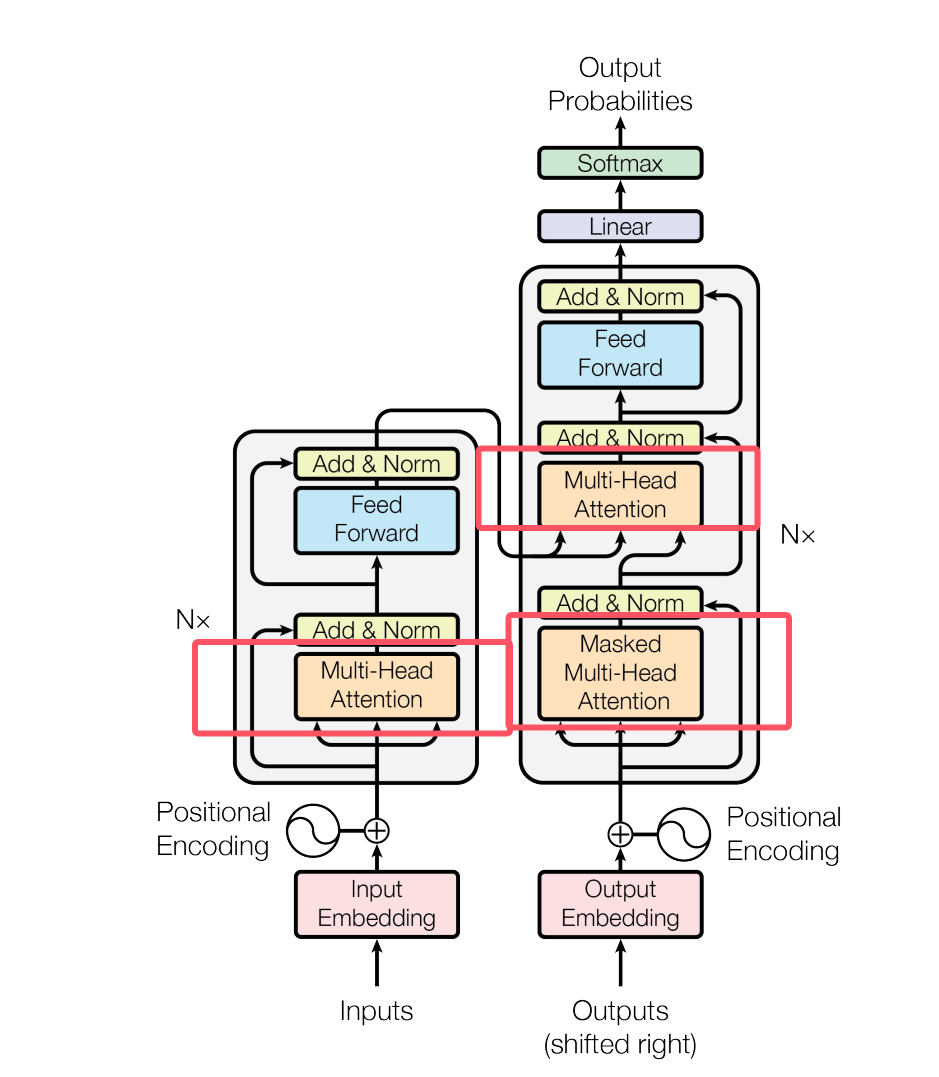
B. Cross-Attention —— 对 Encoder 的输出进行关注
在每一层 Decoder 中,注意力要分两类:
| Attention 类型 | 作用 |
|---|---|
| Masked Self-Attention | 看自己已经生成的部分 |
| Cross-Attention | 看 Encoder 输出的语义向量 |
Cross-Attention = Decoder 问 Encoder:
“你帮我理解的输入里,哪些部分与我现在要生成的内容最相关?”
比如翻译:
- Encoder 得到中文语义向量
- Decoder 生成英文句子
- 每生成一词,都需要关注输入语义中的不同部分
C. Feed Forward Network + 残差等结构
与 Encoder 一样,Decoder 也必须包含:
- FFN(增强抽象能力)
- 残差连接(防止梯度问题)
- LayerNorm(稳定训练)
2.3 总结
1 | |
3. Self-Attention(自注意力机制)
自注意力就是“一个词在理解自己时,会自动去找句子里哪些词和它有关,并根据相关程度给它们不同权重,再综合起来形成新的表达”
3.1 举例
例如输入句子:他 把 球 踢 给 了 小明
模型处理“他”时,会计算它与“球”“小明”“踢”等词的相关性权重。
每个词会对所有词打一个“重要性分数”,然后根据分数对信息加权求和。
3.2 原理
3.2.1 每个词都生成 3 个向量:Q、K、V
- Q(Query):我想知道自己要关注谁
- K(Key):我是什么,别人用这个来判断该不该关注我
- V(Value):我的实际内容(语义)
| 向量 | 类比 | 作用 |
|---|---|---|
| Q | 问题卡 | 你要找相关信息 |
| K | 身份卡 | 别人是否应该关注你 |
| V | 信息卡 | 你真正想提供的内容 |
3.2.2 用 Q 和 K 计算“相关性分数”
在处理词 A 时,词 B 对它有多重要?
- 公式:score = Q × K^T
例如:
- “踢” 对 “小明”的分数高
- “踢” 对 “了”的分数很低
3.2.3 用 Softmax 把分数变成权重
让所有权重加起来 = 1(类似概率分布)
| 词 | 权重 |
|---|---|
| 小明 | 0.45 |
| 球 | 0.30 |
| 小红 | 0.20 |
| 把 / 给 / 了 | 很低 |
3.2.4 把所有相关信息按重要程度加权求和,形成“踢”的新语义向量
这样“踢”就不再是一个孤立的词,而是一个:
- 结合了整个句子语境的词向量
4. Multi-Head Attention(多头注意力)
不是只算一次注意力,而是算多次、用多个“头”并行
每个 head 关注不同类型的信息:
- 一个 head 关注句法结
- 一个 head 关注主谓关系
- 一个 head 关注指代关系
最后把所有 head 拼接起来,表达能力更强。
5. 词嵌入Embedding
Embedding 的作用是把“离散的、无法直接计算的符号(如词、字、图片块)转换成连续的、带语义的向量表示,方便神经网络进行理解和推理。
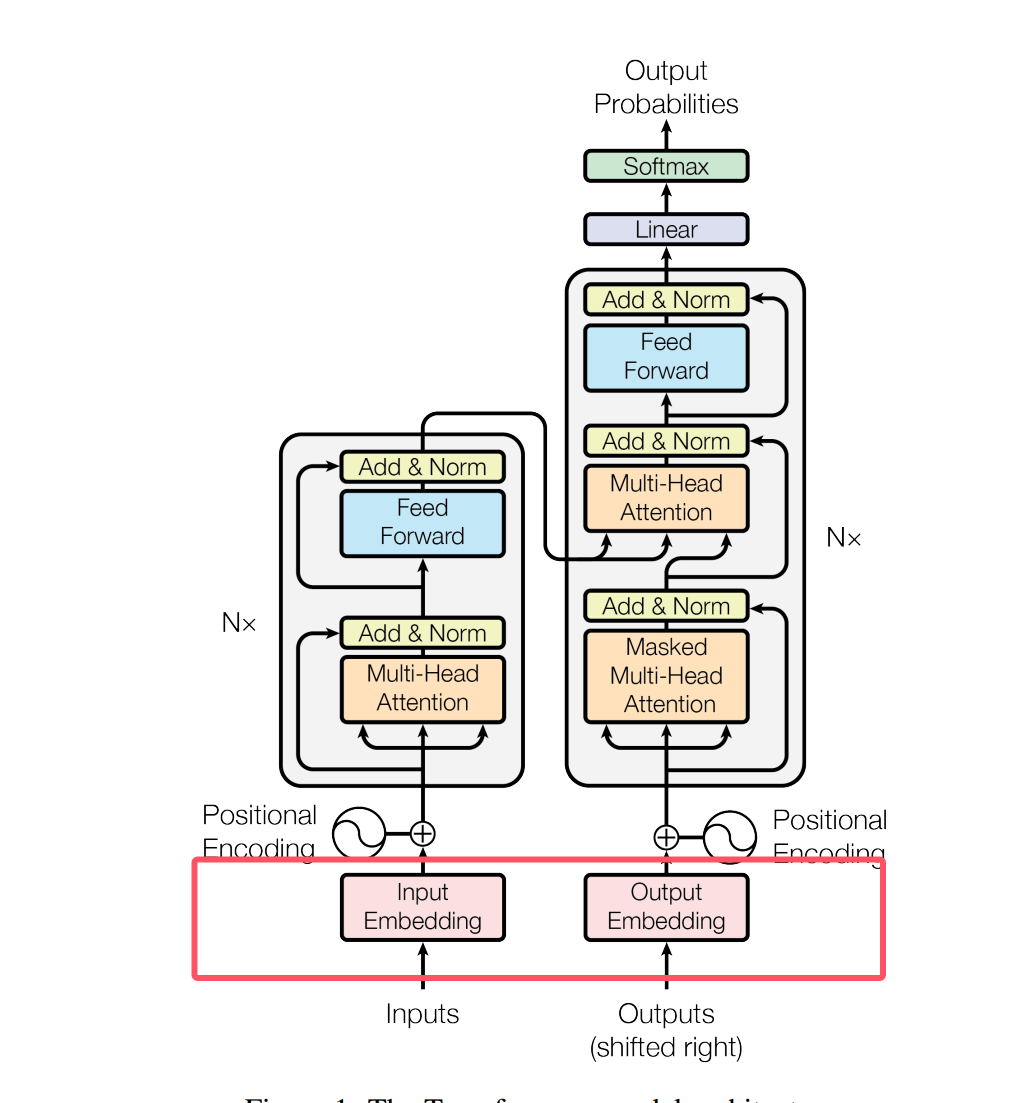
计算机不能理解“人”“苹果”“跑步”这些文字,它只懂数字。
- 所以需要一种方法把“符号”变成“向量”,并且这个向量要带有语义结构。
5.1 把离散符号转换成神经网络能处理的连续向量
Embedding 把每个 Token 映射到一个维度为 d 的向量,例如 768、1024、4096。
1 | |
这就让 Transformer 可以进行:
- 点积运算(计算相似度)
- 其他运算
5.2 表达语义上的相似与差异
向量空间中“距离 + 方向”能表达语义关系。
例如:
1 | |
1 | |
- 语义相似 → 向量相近
- 语义不同 → 向量分离
6. Positional Encoding(位置编码)
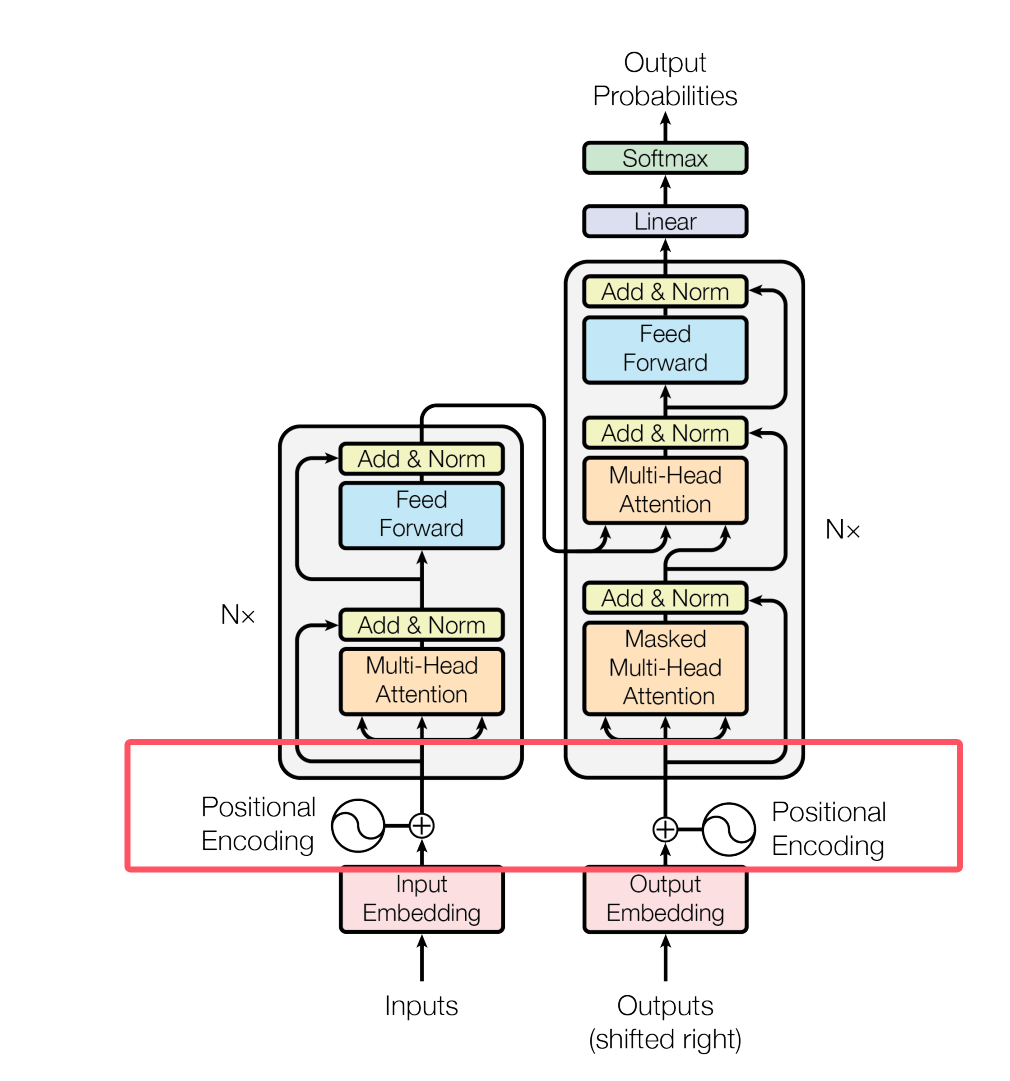
由于 Transformer 没有 RNN 的顺序结构,模型本身不知道词在句子里的顺序。
所以要额外加入位置信息:
- sin/cos位置编码(原论文)
- 或可学习位置编码
作用:
告诉模型:“今天 下雨 了”和“下雨 今天 了”位置不一样,含义不同。
7. Feed Forward Network(前馈神经网络)
每一层 Transformer 中都有一个位置独立的 FFN:
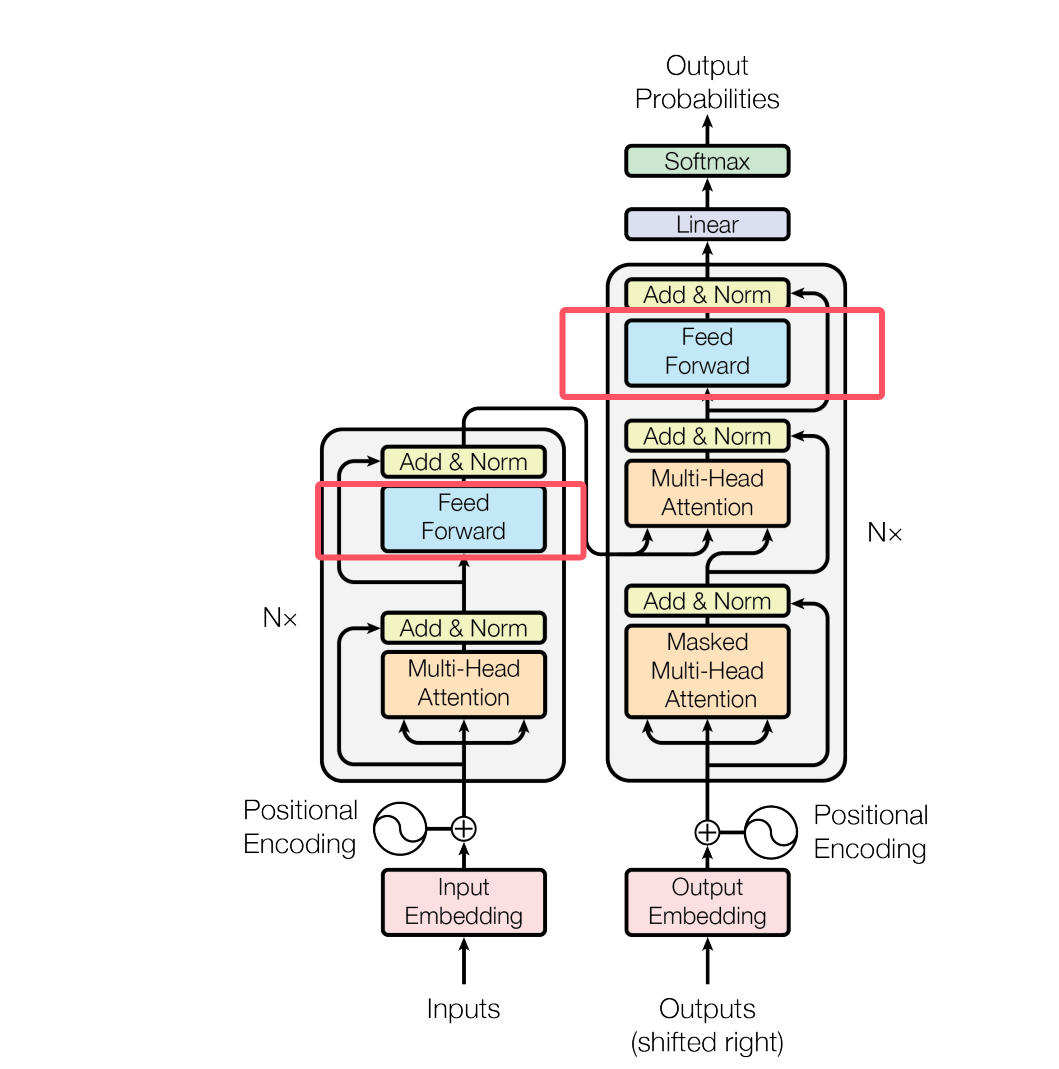
1 | |
作用:
- 提升非线性表达能力
- 提取更复杂的特征
并且每层都包含:
- 残差连接(Residual Connection)
- LayerNorm(层归一化)
来保证训练稳定性。