Redis学习笔记及面试问题分析
Redis学习笔记
一. Redis快速入门
1. 初识Redis
- Redis是一种键值型的NoSql数据库
- 全称是Remote Dictionary Server 远程词典服务器,是一个基于内存的键值型NoSQL数据库。
特征:
- 键值(key-value)型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性
- 低延迟,速度快(基于内存、IO多路复用、良好的编码)。
- 支持数据持久化
- 支持主从集群、分片集群
- 支持多语言客户端
2. Redis常见命令
Redis是典型的key-value数据库,key一般是字符串,而value包含很多不同的数据类型

2.1 Redis通用命令
都可以使用的指令,常见的有:
- KEYS:查看符合模板的所有key
- DEL:删除一个指定的key
- EXISTS:判断key是否存在
- EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除
- TTL:查看一个KEY的剩余有效期
2.2 String类型
其value是字符串,不过根据字符串的格式不同,又可以分为3类:
- string:普通字符串
- int:整数类型,可以做自增、自减操作
- float:浮点类型,可以做自增、自减操作
String的常见命令有:
- SET:添加或者修改已经存在的一个String类型的键值对
- GET:根据key获取String类型的value
- MSET:批量添加多个String类型的键值对
- MGET:根据多个key获取多个String类型的value
- INCR:让一个整型的key自增1
- INCRBY:让一个整型的key自增并指定步长,例如:incrby num 2 让num值自增2
- INCRBYFLOAT:让一个浮点类型的数字自增并指定步长
- SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行
- SETEX:添加一个String类型的键值对,并且指定有效期
2.3 Key结构
通过给key添加前缀加以区分,Redis的key允许有多个单词形成层级结构,多个单词之间用’:’隔开,格式如下:
1 | |
例如我们的项目名称叫 heima,有user和product两种不同类型的数据,我们可以这样定义key:
- user相关的key:heima:user:1
- product相关的key:heima:product:1
2.4 Hash类型
Hash类型,也叫散列,其value是一个无序字典,类似于Java中的HashMap结构。
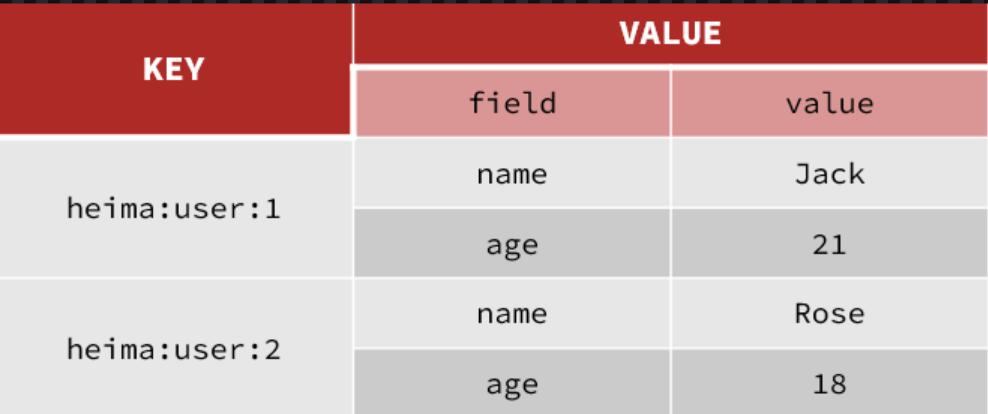
Hash的常见命令有:
- HSET key field value:添加或者修改hash类型key的field的值
- HGET key field:获取一个hash类型key的field的值
- HMSET:批量添加多个hash类型key的field的值
- HMGET:批量获取多个hash类型key的field的值
- HGETALL:获取一个hash类型的key中的所有的field和value
- HKEYS:获取一个hash类型的key中的所有的field
- HINCRBY:让一个hash类型key的字段值自增并指定步长
- HSETNX:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
2.5 List类型
Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构。既可以支持正向检索和也可以支持反向检索
特征也与LinkedList类似:
- 有序
- 元素可以重复
- 插入和删除快
- 查询速度一般
常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等。
List的常见命令有:
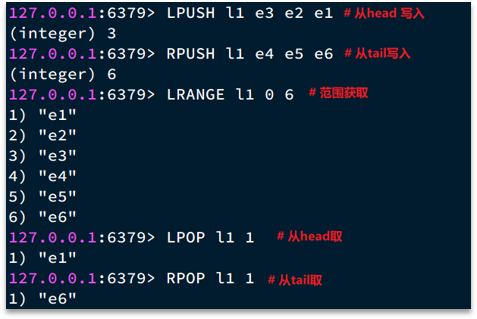
- LPUSH key element … :向列表左侧插入一个或多个元素
- LPOP key:移除并返回列表左侧的第一个元素,没有则返回nil
- RPUSH key element … :向列表右侧插入一个或多个元素
- RPOP key:移除并返回列表右侧的第一个元素
- LRANGE key star end:返回一段角标范围内的所有元素
- BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil
2.6 Set类型
Redis的Set结构与Java中的HashSet类似,可以看做是一个value为null的HashMap
Set的常见命令有:
- SADD key member … :向set中添加一个或多个元素
- SREM key member … : 移除set中的指定元素
- SCARD key: 返回set中元素的个数
- SISMEMBER key member:判断一个元素是否存在于set中
- SMEMBERS:获取set中的所有元素
- SINTER key1 key2 … :求key1与key2的交集
2.7 SortedSet类型
Redis的SortedSet是一个可排序的set集合
SortedSet具备下列特性:
- 可排序
- 元素不重复
- 查询速度快
因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能。
SortedSet的常见命令有:
- ZADD key score member:添加一个或多个元素到sorted set ,如果已经存在则更新其score值
- ZREM key member:删除sorted set中的一个指定元素
- ZSCORE key member : 获取sorted set中的指定元素的score值
- ZRANK key member:获取sorted set 中的指定元素的排名
- ZCARD key:获取sorted set中的元素个数
- ZCOUNT key min max:统计score值在给定范围内的所有元素的个数
- ZINCRBY key increment member:让sorted set中的指定元素自增,步长为指定的increment值
- ZRANGE key min max:按照score排序后,获取指定排名范围内的元素
- ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素
- ZDIFF、ZINTER、ZUNION:求差集、交集、并集
注意:所有的排名默认都是升序,如果要降序则在命令的Z后面添加REV即可
3. Redis的Java客户端
- Jedis和Lettuce:这两个主要是提供了Redis命令对应的API,方便我们操作Redis,而SpringDataRedis又对这两种做了抽象和封装,因此我们后期会直接以SpringDataRedis来学习。
- Redisson:是在Redis基础上实现了分布式的可伸缩的java数据结构,例如Map、Queue等,而且支持跨进程的同步机制:Lock、Semaphore等待,比较适合用来实现特殊的功能需求。
3.1 Jedis客户端
3.1.1 快速入门
- 引入依赖:
1 | |
- 建立连接
新建一个单元测试类,内容如下:
1 | |
- 测试:
1 | |
- 释放资源
1 | |
3.1.2 连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此我们使用Jedis连接池代替Jedis的直连方式。
1 | |
3.2 SpringDataRedis客户端
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis
- 提供了对不同Redis客户端的整合(Lettuce和Jedis)
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK、JSON、字符串、Spring对象的数据序列化及反序列化
- 支持基于Redis的JDKCollection实现
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中:

3.2.1 快速入门
- 引入依赖
1 | |
- 配置Redis
1 | |
- 注入RedisTemplate
1 | |
- 编写测试
1 | |
3.2.2 自定义序列化
RedisTemplate可以接收任意Object作为值写入Redis:
只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化,得到的结果是序列化之后的字符串。可读性差,内存占用较大。
我们可以自定义RedisTemplate的序列化方式,代码如下:
1 | |
3.2.3 StringRedisTemplate
为了节省内存空间,我们可以不使用JSON序列化器来处理value,而是统一使用String序列化器,要求只能存储String类型的key和value。当需要存储Java对象时,手动完成对象的序列化和反序列化。

StringRedisTemplate,它的key和value的序列化方式默认就是String方式。
1 | |
二. 实战篇-黑马点评
1. 短信登录
1.1 基于Session实现登录流程
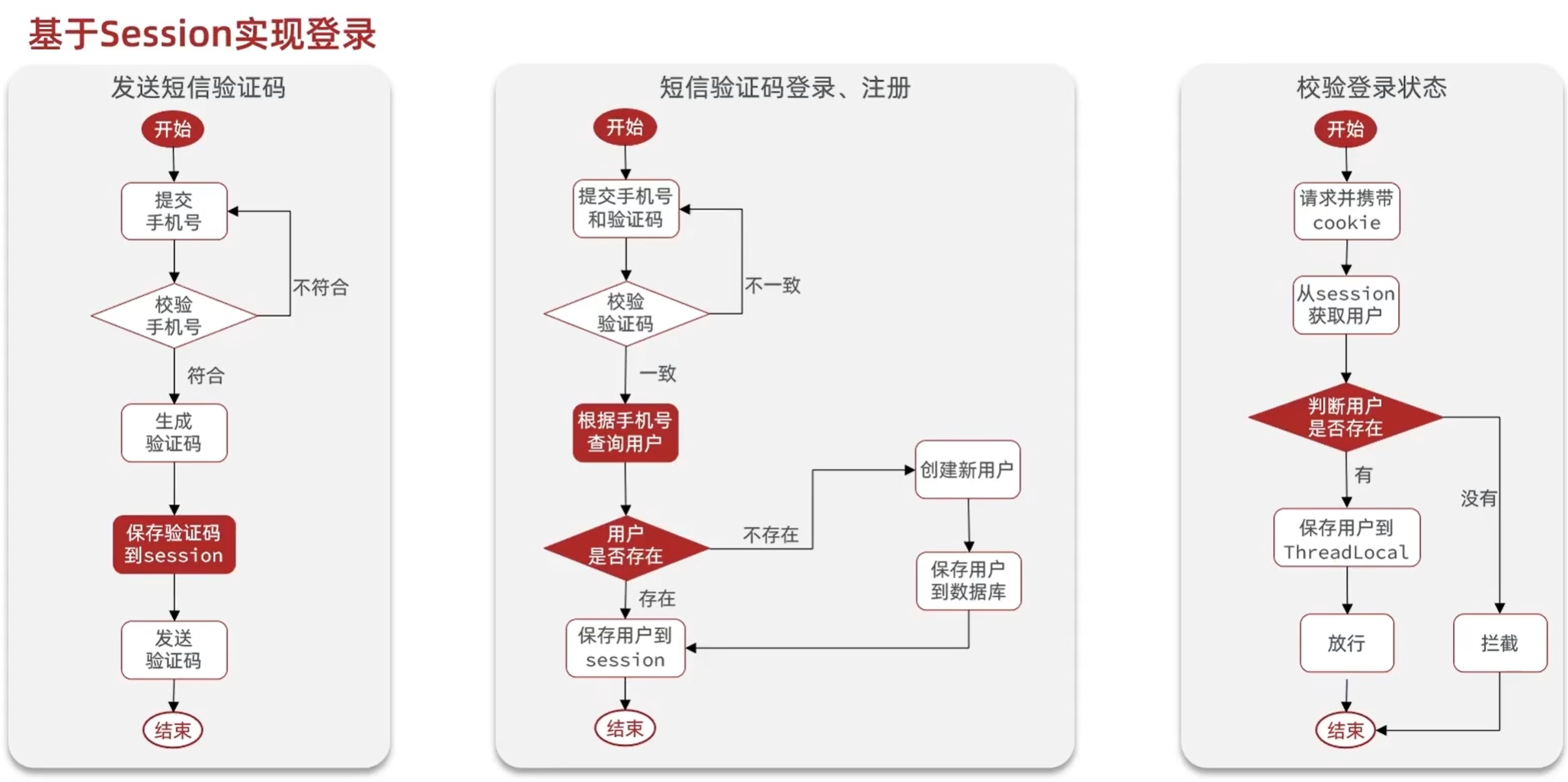
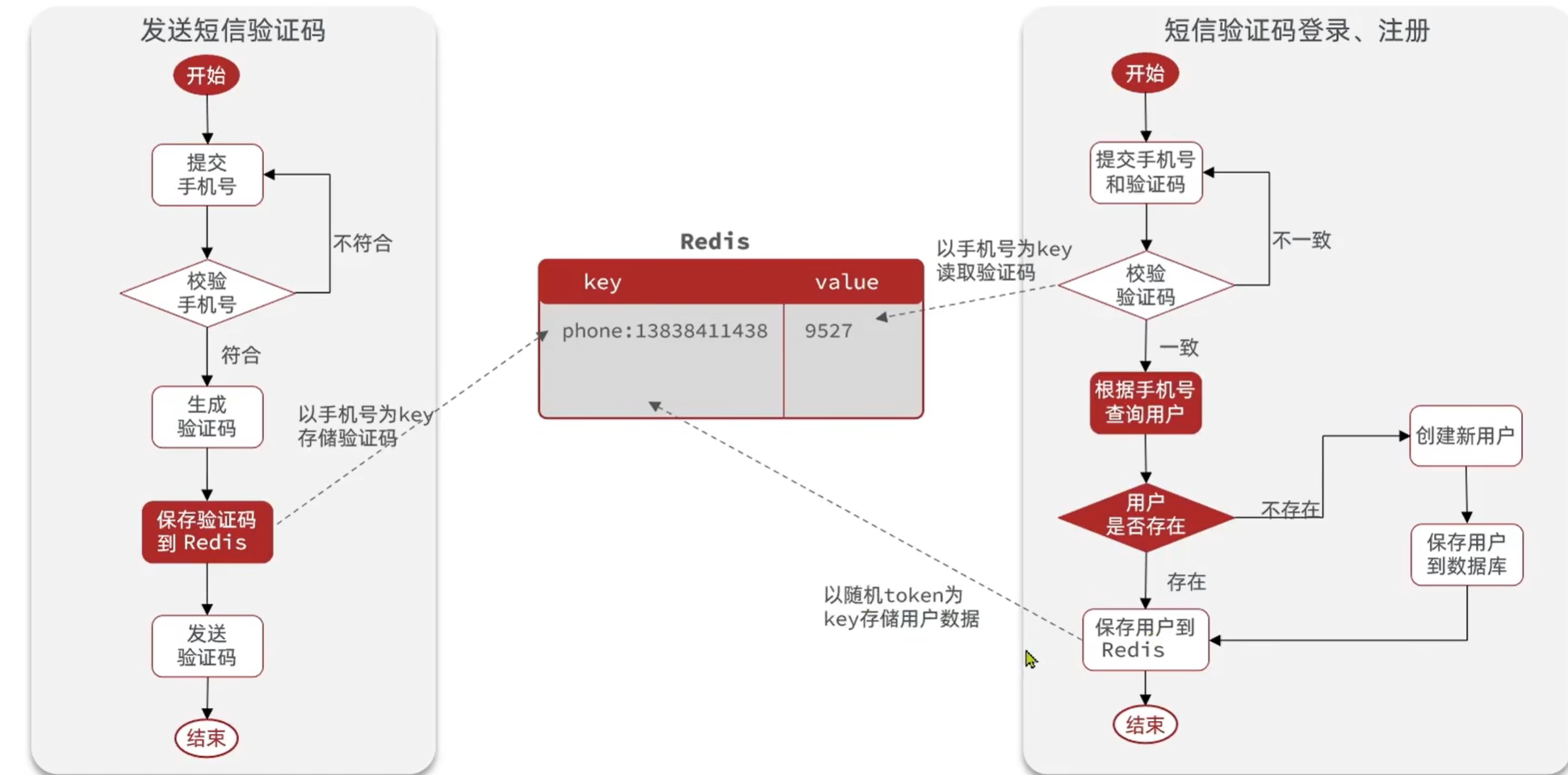
发送验证码:
用户在提交手机号后,会校验手机号是否合法,如果不合法,则要求用户重新输入手机号
如果手机号合法,后台此时生成对应的验证码,同时将验证码进行保存,然后再通过短信的方式将验证码发送给用户
短信验证码登录、注册:
用户将验证码和手机号进行输入,后台从session中拿到当前验证码,然后和用户输入的验证码进行校验,如果不一致,则无法通过校验,如果一致,则后台根据手机号查询用户,如果用户不存在,则为用户创建账号信息,保存到数据库,无论是否存在,都会将用户信息保存到session中,方便后续获得当前登录信息
校验登录状态:
用户在请求时候,会从cookie中携带者JsessionId到后台,后台通过JsessionId从session中拿到用户信息,如果没有session信息,则进行拦截,如果有session信息,则将用户信息保存到threadLocal中,并且放行
1.2 实现发送短信验证码功能
- 发送验证码
1 | |
- 登录
1 | |
1.3 实现登录拦截功能
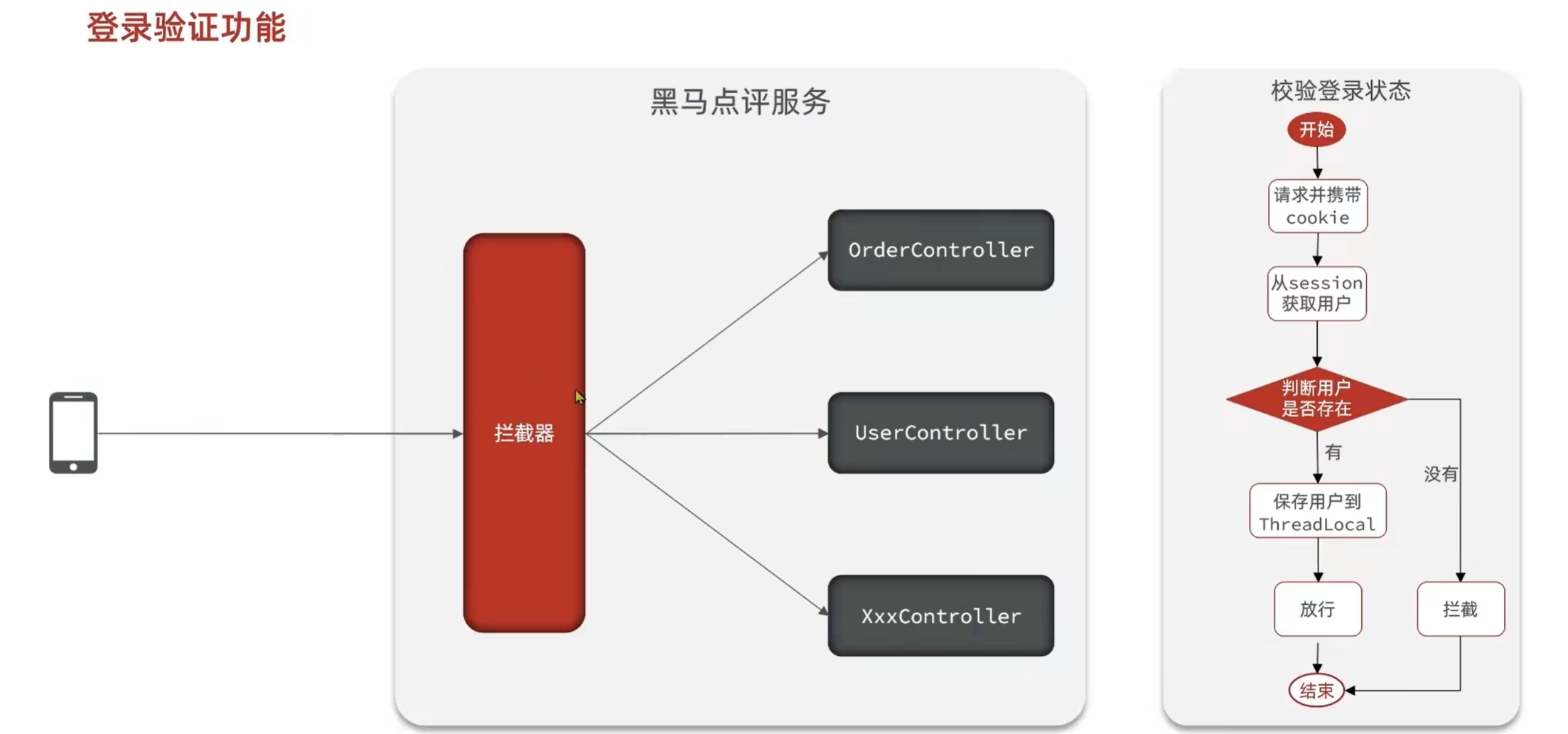
拦截器代码:
1 | |
让拦截器生效:
1 | |
1.4 隐藏用户敏感信息
我们通过浏览器观察到此时用户的全部信息都在,这样极为不靠谱,所以我们应当在返回用户信息之前,将用户的敏感信息进行隐藏,采用的核心思路就是书写一个UserDTO对象,这个UserDTO对象就没有敏感信息了,我们在返回前,将有用户敏感信息的User对象转化成没有敏感信息的UserDTO对象,那么就能够避免这个尴尬的问题了
1.5 session共享问题
session共享问题:多台Tomcat并不共享session存储空间,当请求切换到不同tomcat服务时导致数据丢失的问题
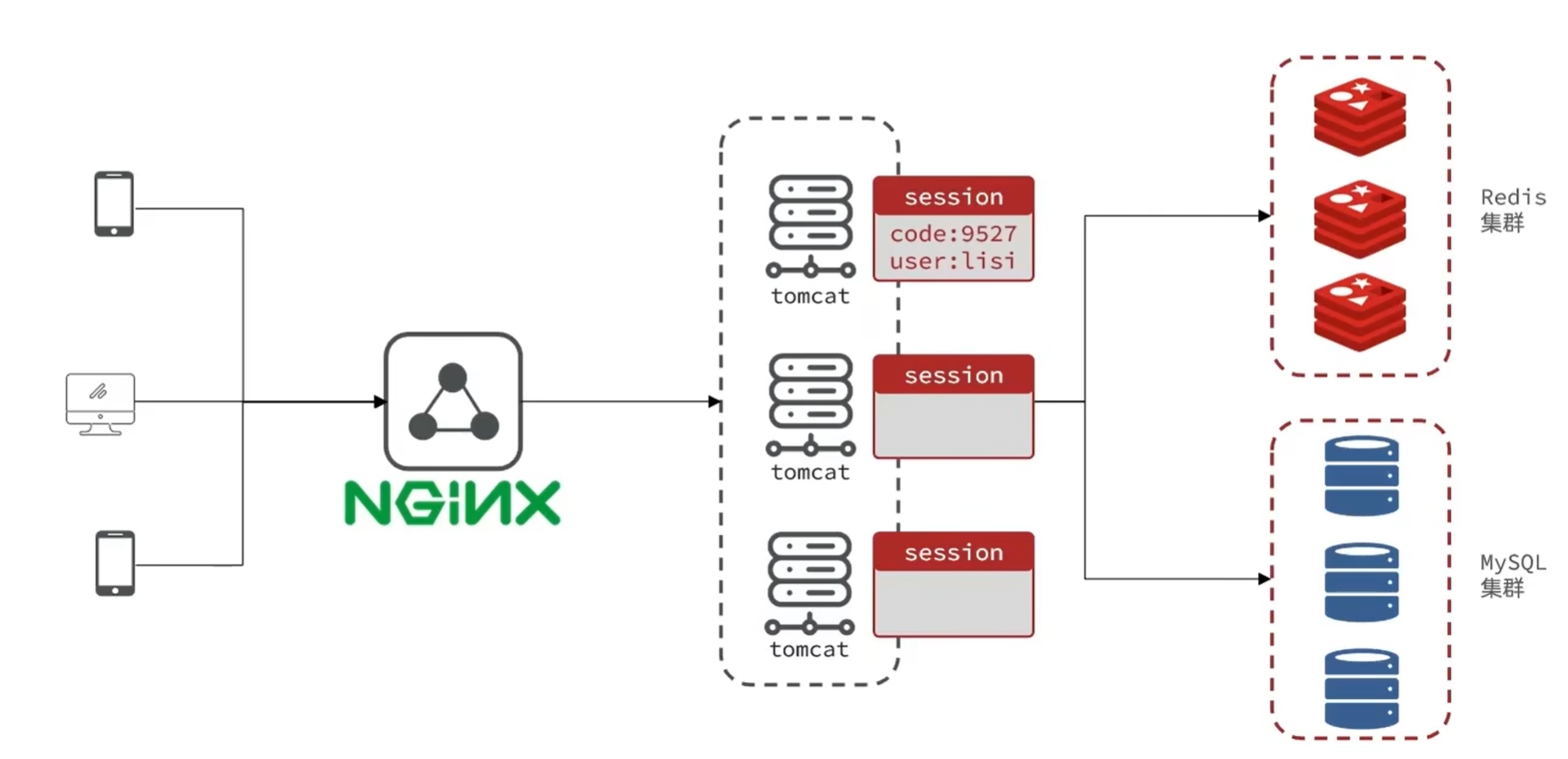
- 每个tomcat中都有一份属于自己的session
- 假设用户第一次访问第一台tomcat,并且把自己的信息存放到第一台服务器的session中
- 但是第二次这个用户访问到了第二台tomcat,那么在第二台服务器上,肯定没有第一台服务器存放的session
解决方法:
所以咱们后来采用的方案都是基于redis来完成,我们把session换成redis,redis数据本身就是共享的,就可以避免session共享的问题了
1.6 Redis代替session的业务流程
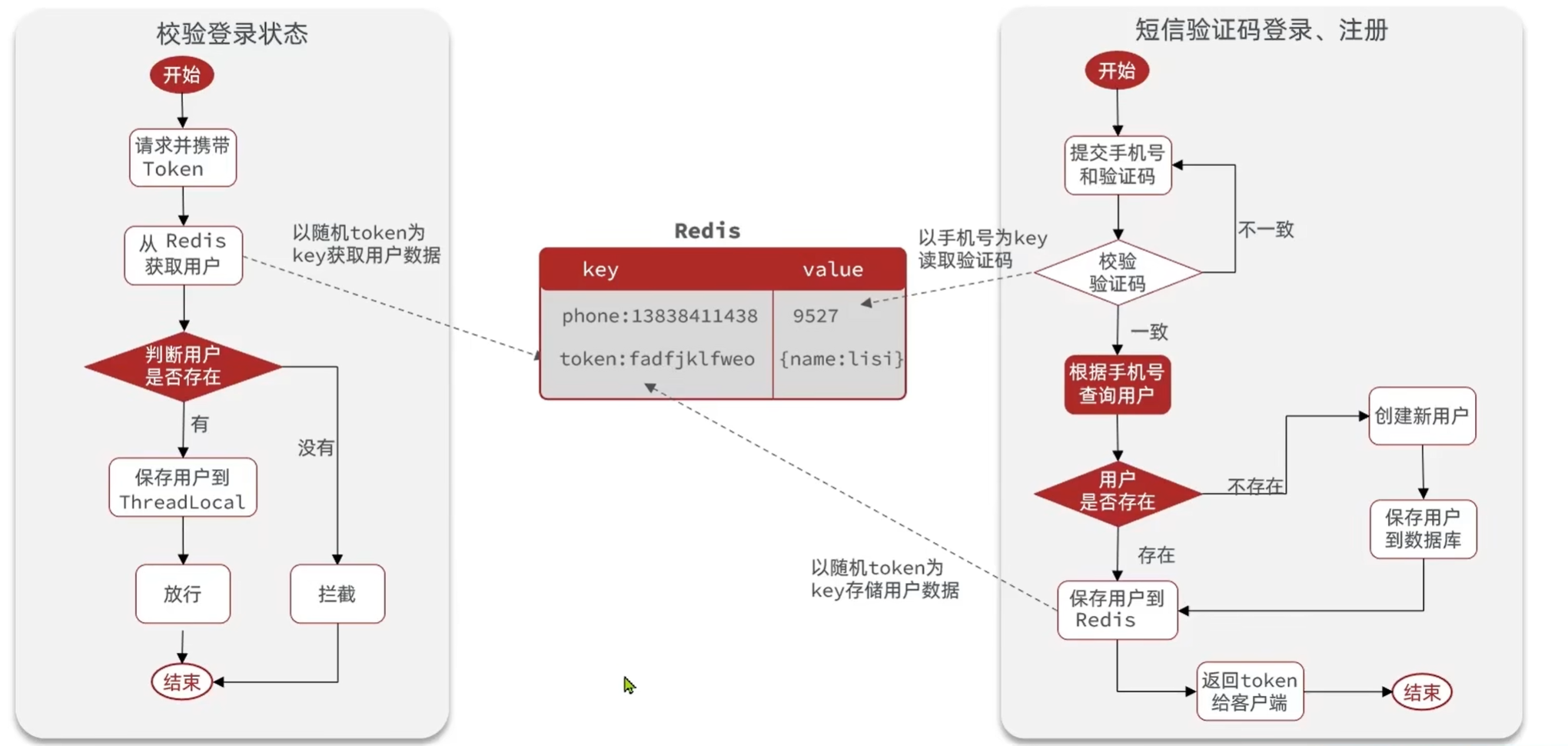
- 当注册完成后,用户去登录会去校验用户提交的手机号和验证码,是否一致,如果一致,则根据手机号查询用户信息,不存在则新建。最后将用户数据保存到redis,并且生成token作为redis的key
- 当我们校验用户是否登录时,会去携带着token进行访问,从redis中取出token对应的value,判断是否存在这个数据,如果没有则拦截,如果存在则将其保存到ThreadLocal中,并且放行。
1.7 基于Redis实现短信登录
UserServiceImpl代码
1 | |
1.8 解决状态登录刷新问题
- 原始拦截器确实可以使用对应路径的拦截,同时刷新登录token令牌的存活时间,但是现在这个拦截器他只是拦截需要被拦截的路径
- 假设当前用户访问了一些不需要拦截的路径,那么这个拦截器就不会生效,所以此时令牌刷新的动作实际上就不会执行
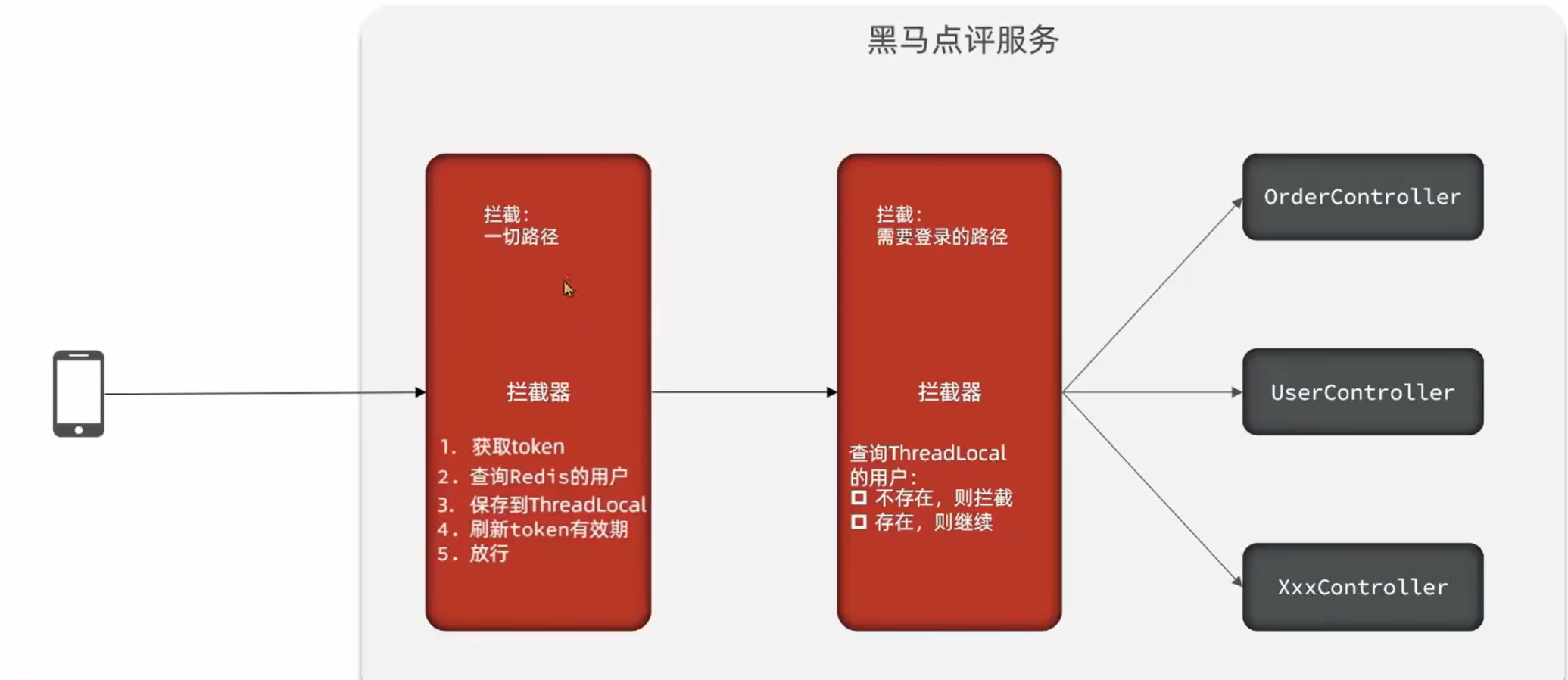
- 我们可以添加一个拦截器,在第一个拦截器中拦截所有的路径,把第二个拦截器做的事情放入到第一个拦截器中,同时刷新令牌,因为第一个拦截器有了threadLocal的数据,所以此时第二个拦截器只需要判断拦截器中的user对象是否存在即可,完成整体刷新功能。
RefreshTokenInterceptor:
1 | |
LoginInterceptor:
1 | |
MvcConfig:
1 | |
2. 商户查询缓存
2.1 什么是缓存?
缓存就是数据交换的缓冲区(称作Cache),是存贮数据的临时地方,一般读写性能较高。
缓存(Cache),就是数据交换的缓冲区,俗称的缓存就是缓冲区内的数据,一般从数据库中获取,存储于本地代码
为什么使用缓存?
- 速度快,好用
- 缓存数据存储于代码中,而代码运行在内存中,内存的读写性能远高于磁盘,缓存可以大大降低用户访问并发量带来的服务器读写压力
但是缓存也会增加代码复杂度和运营的成本
2.2 添加商户缓存
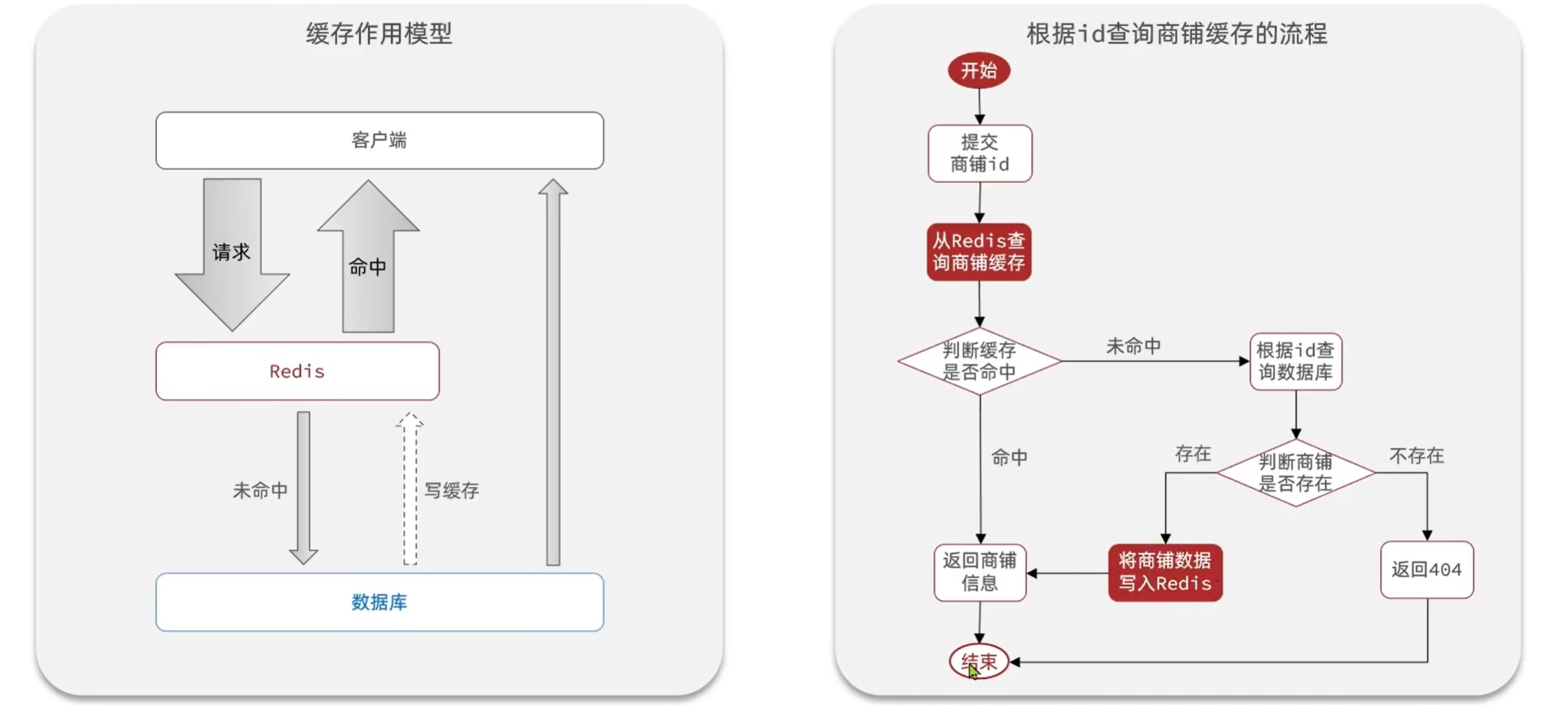
- 查询数据库之前先查询缓存,如果缓存数据存在,则直接从缓存中返回,如果缓存数据不存在,再查询数据库,然后将数据存入redis
ShopServiceImpl:
1 | |
2.3 缓存更新策略
redis会对部分数据进行更新,或者把他叫为淘汰
有以下三种更新策略:
| 内存淘汰 | 超时删除 | 主动更新 | |
|---|---|---|---|
| 说明 | 不用自己维护,利用Redis的内存淘汰机制,当内存不足时自动淘汰部分数据。下次查询时更新缓存。 | 给缓存数据添加TTL时间,到期后自动删除缓存。下次查询时更新缓存。 | 编写业务逻辑,在修改数据库的同时,更新缓存。 |
| 一致性 | 差 | 一般 | 好 |
| 维护成本 | 无 | 低 | 高 |
业务场景:
- 低一致性需求:使用内存淘汰机制。例如店铺类型的查询缓存
- 高一致性需求:主动更新,并以超时剔除作为兜底方案。例如店铺详情查询的缓存
数据库和缓存不一致采用什么方案?
人工编码方式:缓存调用者在更新完数据库后再去更新缓存,也称之为双写方案
删除缓存还是更新缓存?(选择删除缓存)
- 更新缓存:每次更新数据库都更新缓存,无效写操作较多
- 删除缓存:更新数据库时让缓存失效,查询时再更新缓存
如何保证缓存与数据库的操作的同时成功或失败?
- 单体系统,将缓存与数据库操作放在一个事务
- 分布式系统,利用TCC等分布式事务方案
先操作缓存还是先操作数据库?(先操作数据库,再删除缓存)
- 先删除缓存,再操作数据库
- 先操作数据库,再删除缓存
2.4 实现商铺和缓存与数据库双写一致
修改ShopController中的业务逻辑,满足下面的需求:
- 根据id查询店铺时,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间
- 根据id修改店铺时,先修改数据库,再删除缓存
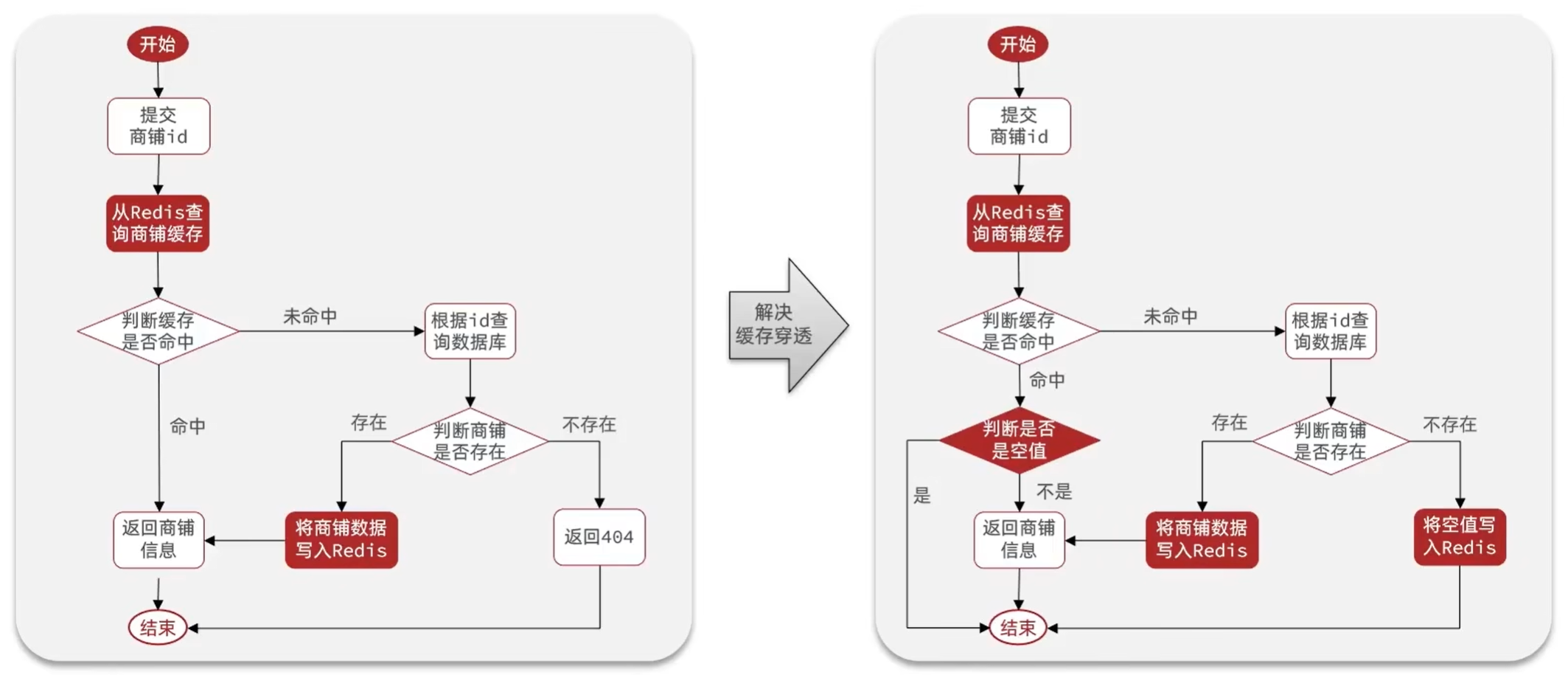
2.5 缓存穿透
缓存穿透 :缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
常见的解决方案有两种:
- 缓存空对象
- 优点:实现简单,维护方便
- 缺点:
- 额外的内存消耗
- 可能造成短期的不一致
- 布隆过滤
- 优点:内存占用较少,没有多余key
- 缺点:
- 实现复杂
- 存在误判可能
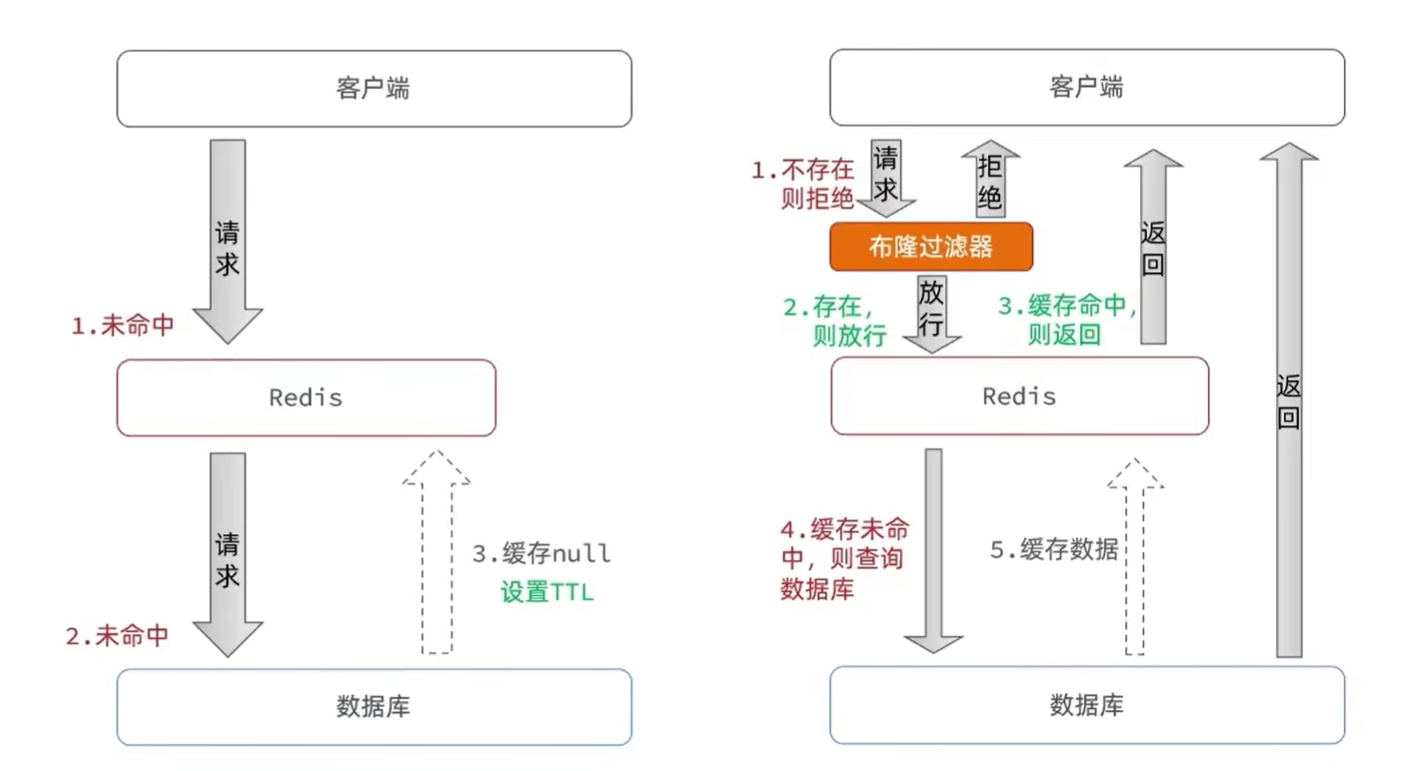
编码解决商品查询的缓存穿透问题:
- 原来的逻辑中,我们如果发现这个数据在mysql中不存在,直接就返回404了,这样是会存在缓存穿透问题的
- 现在的逻辑中:如果这个数据不存在,我们不会返回404
- 而是会把这个数据写入到Redis中,并且将value设置为空
- 当再次发起查询时,我们如果发现命中之后,判断这个value是否是null,如果是null,则是之前写入的数据,证明是缓存穿透数据,如果不是,则直接返回数据。
CacheClient:
1 | |
2.6 缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
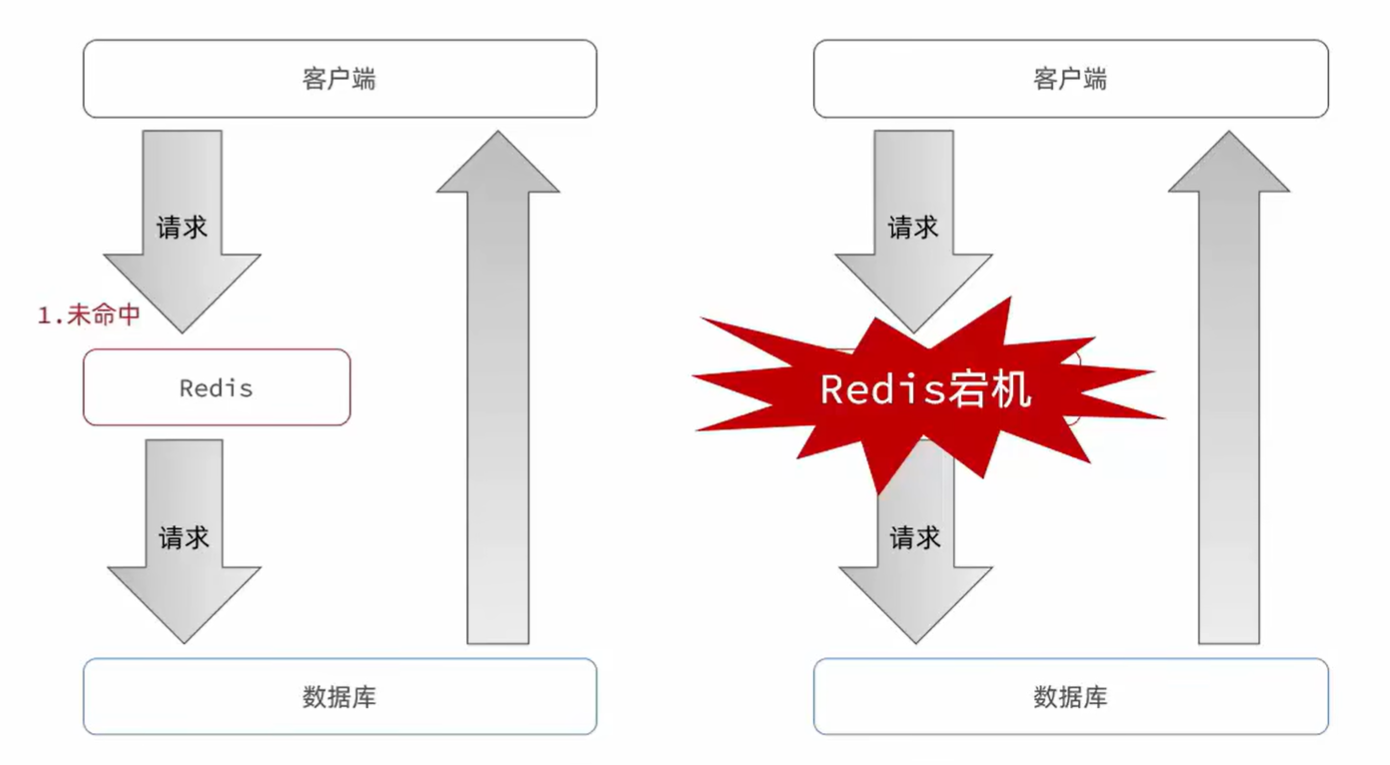
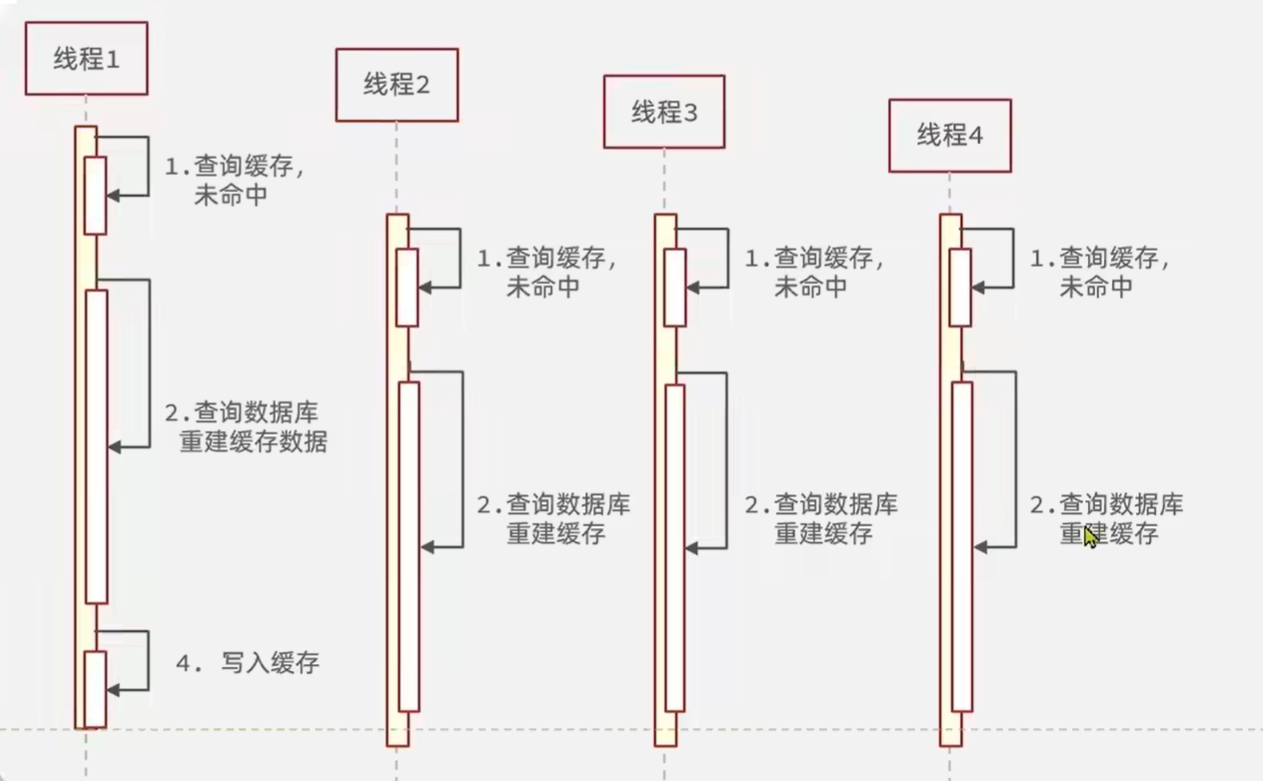
2.7 缓存击穿
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
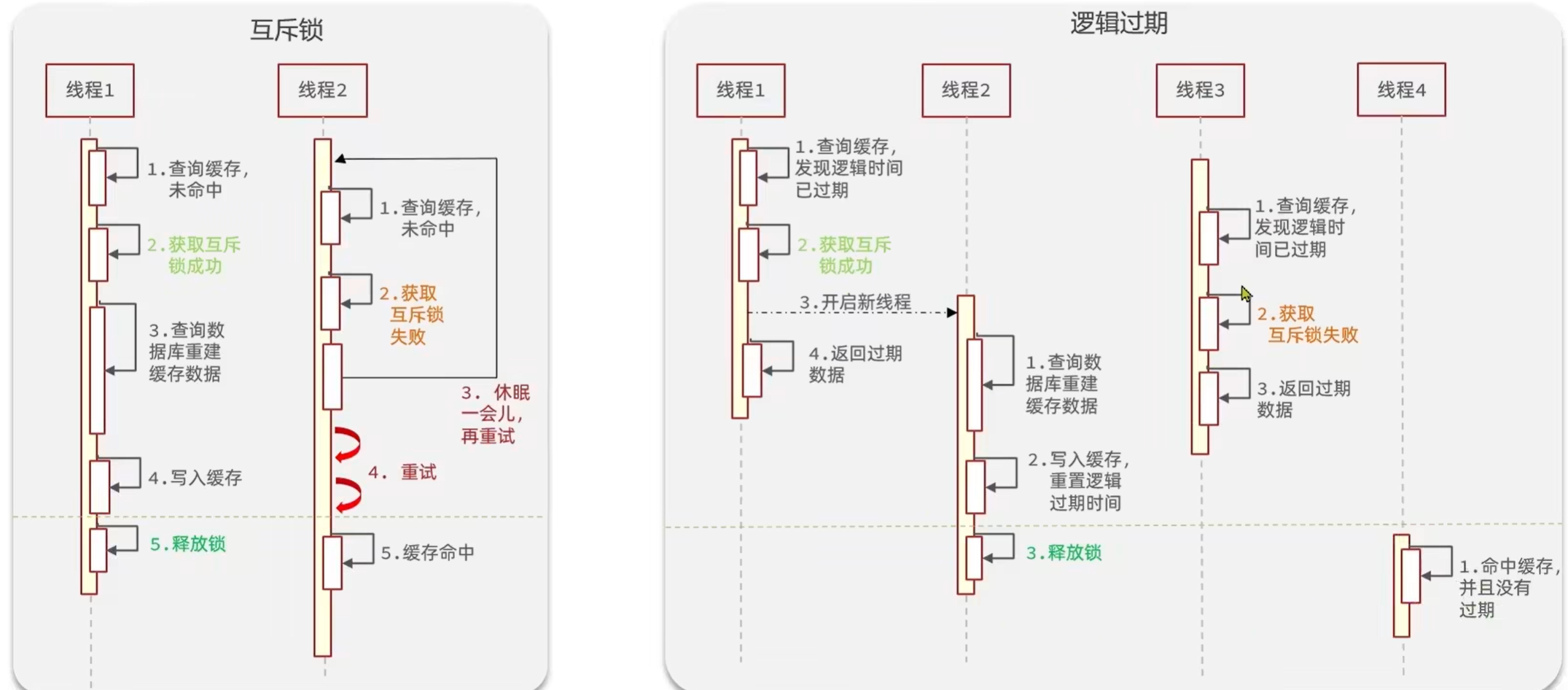
常见的解决方案有两种:
- 互斥锁
- 逻辑过期
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 互斥锁 | - 没有额外的内存消耗 - 保证一致性 - 实现简单 |
- 线程需要等待,性能受影响 - 可能有死锁风险 |
| 逻辑过期 | - 线程无需等待,性能较好 | - 不保证一致性 - 有额外内存消耗 - 实现复杂 |
2.7.1 利用互斥锁解决缓存击穿问题
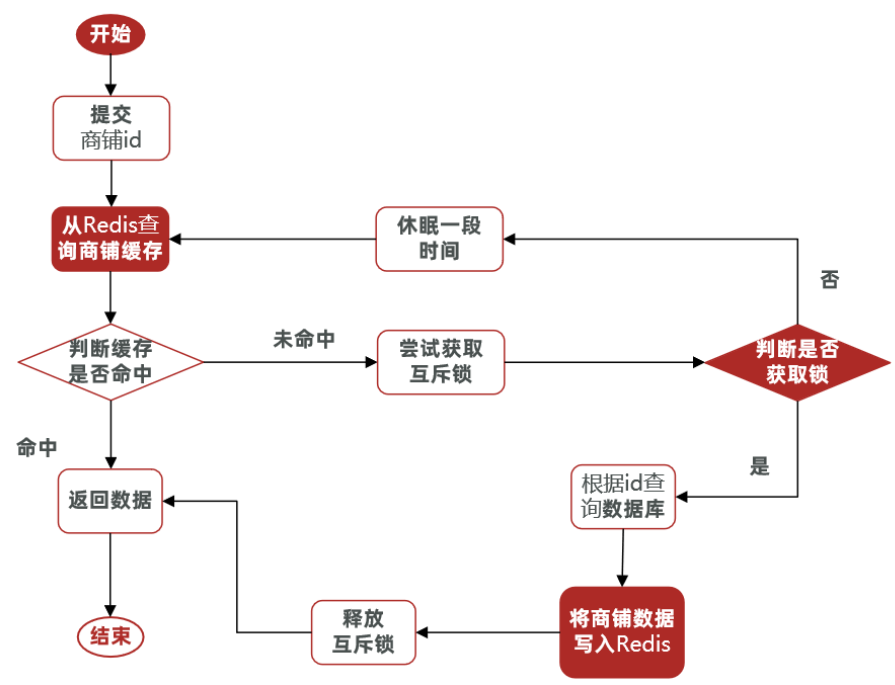
ShopServiceImpl:
1 | |
2.7.2 利用逻辑过期解决缓存击穿问题
修改根据id查询商铺的业务,基于逻辑过期方式来解决缓存击穿问题
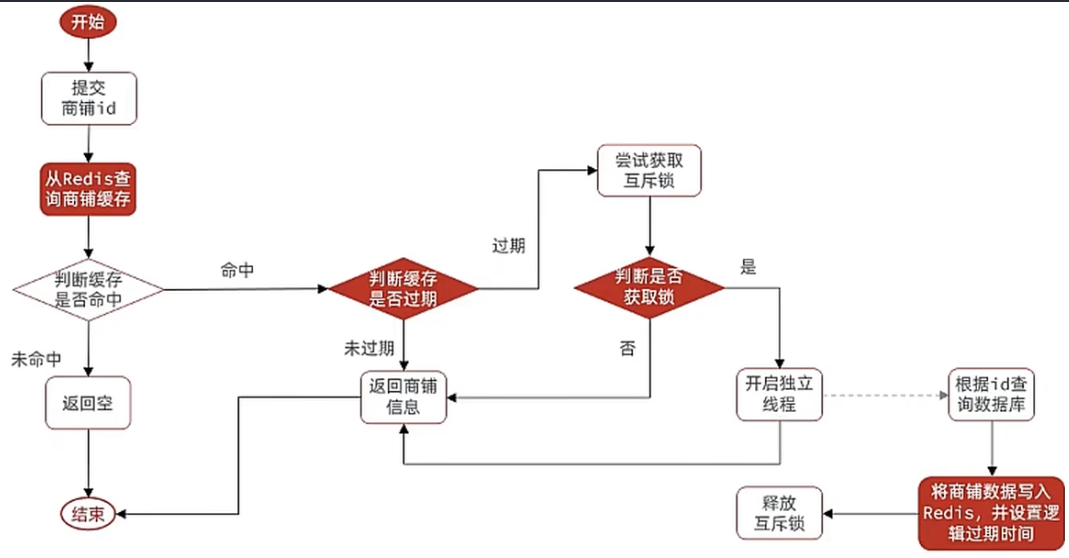
ShopServiceImpl:
1 | |
2.8 封装Redis工具类
基于StringRedisTemplate封装一个缓存工具类,满足下列需求:
- 方法1:将任意Java对象序列化为json并存储在string类型的key中,并且可以设置TTL过期时间
- 方法2:将任意Java对象序列化为json并存储在string类型的key中,并且可以设置逻辑过期时间,用于处理缓存击穿问题
- 方法3:根据指定的key查询缓存,并反序列化为指定类型,利用缓存空值的方式解决缓存穿透问题
- 方法4:根据指定的key查询缓存,并反序列化为指定类型,需要利用逻辑过期解决缓存击穿问题
封装成CacheClient类:
1 | |
3. 优惠券秒杀
3.1 全局唯一ID
当用户抢购时,就会生成订单并保存到tb_voucher_order这张表中,而订单表如果使用数据库自增ID就存在一些问题:
- id的规律性太明显
- 受单表数据量的限制
全局ID生成器,是一种在分布式系统下用来生成全局唯一ID的工具,一般要满足下列特性:
- 唯一性
- 高可用
- 高性能
- 递增性
- 安全性
- 为了增加ID的安全性,我们可以不直接使用Redis自增的数值,而是拼接一些其它信息:
- ID的组成部分:符号位:1bit,永远为0
- 时间戳:31bit,以秒为单位,可以使用69年
- 序列号:32bit,秒内的计数器,支持每秒产生2^32个不同ID

Redis实现全局唯一Id:
1 | |
3.2 添加优惠券&实现秒杀下单
每个店铺都可以发布优惠券,分为平价券和特价券。平价券可以任意购买,而特价券需要秒杀抢购:

实现秒杀下单:
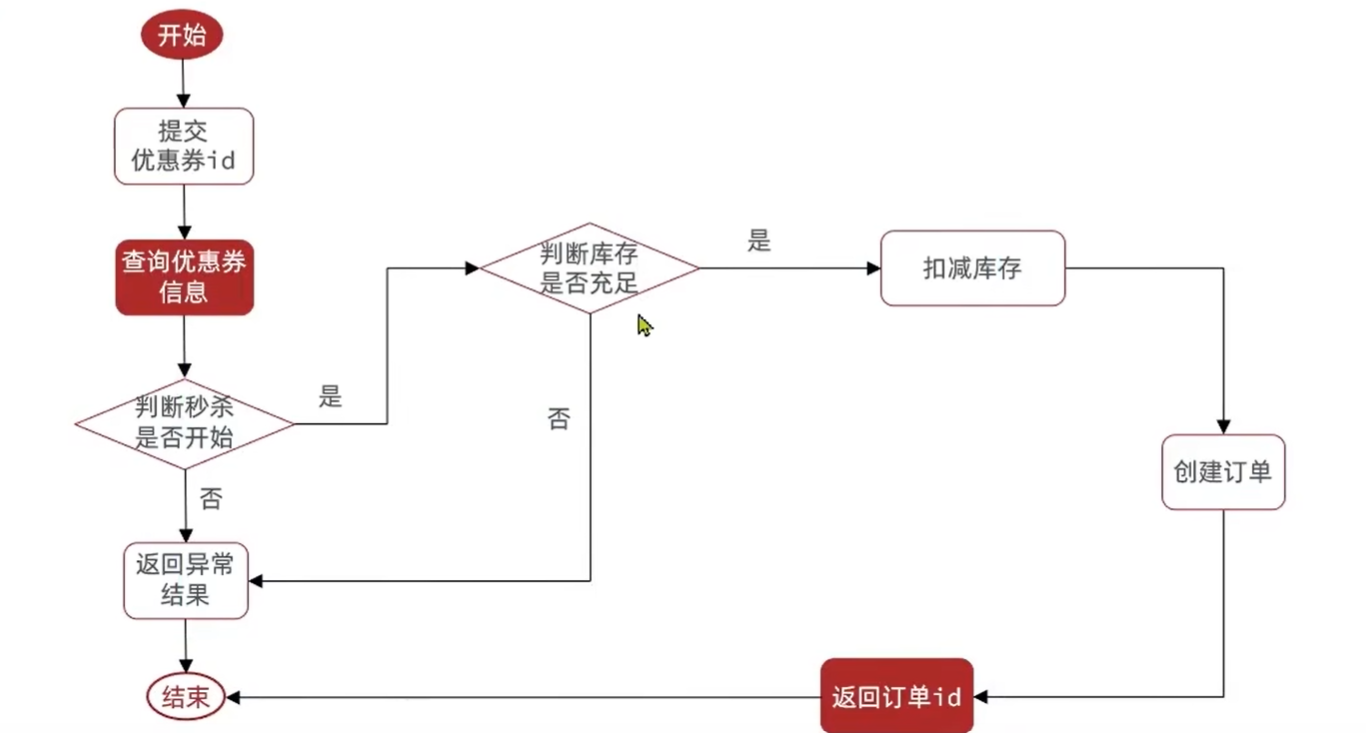
下单时需要判断两点:
- 秒杀是否开始或结束,如果尚未开始或已经结束则无法下单
- 库存是否充足,不足则无法下单
1 | |
3.3 库存超卖问题(多线程安全问题)
假设线程1过来查询库存,判断出来库存大于1,正准备去扣减库存,但是还没有来得及去扣减,此时线程2过来,线程2也去查询库存,发现这个数量一定也大于1,那么这两个线程都会去扣减库存,最终多个线程相当于一起去扣减库存,此时就会出现库存的超卖问题。
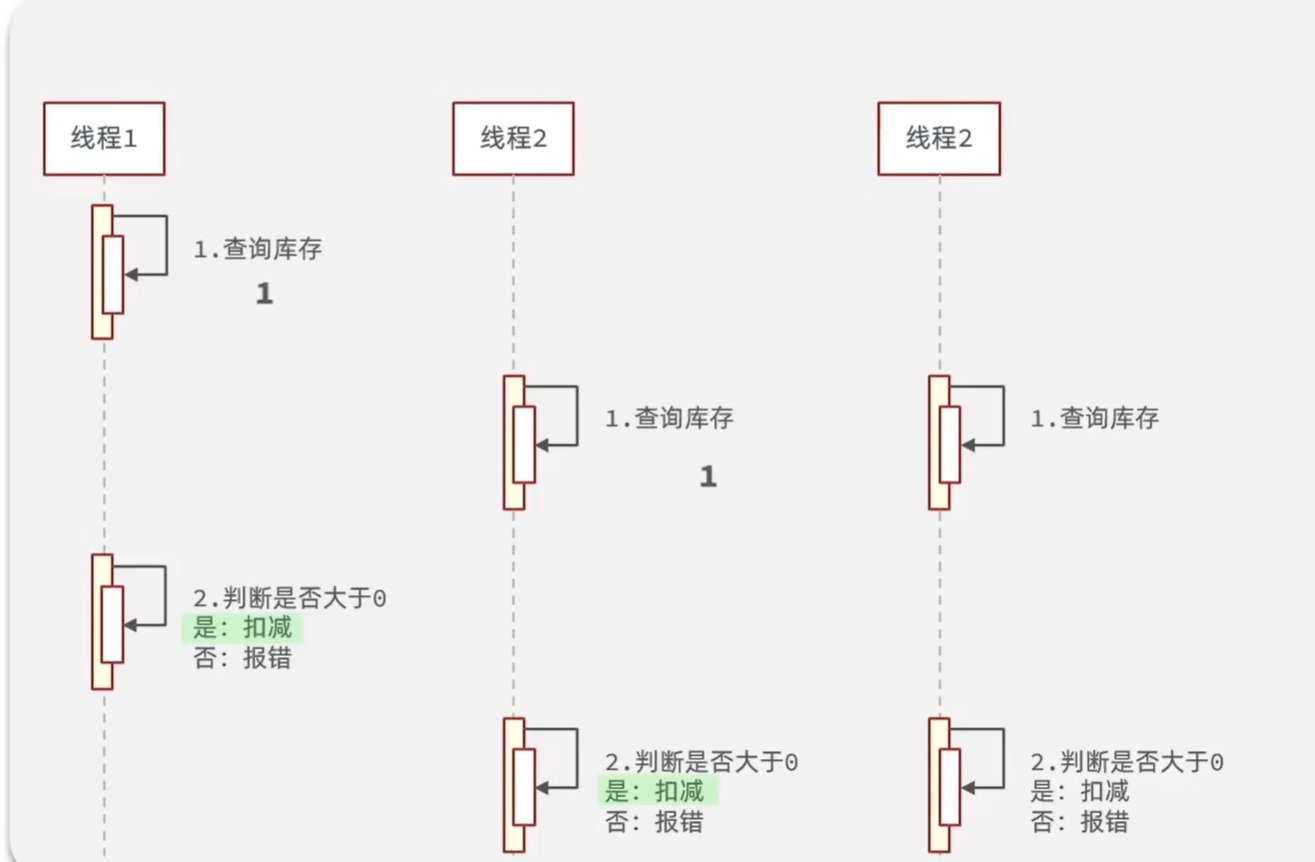
3.3.1 解决方案(加锁)
悲观锁:
- 认为线程安全问题一定会发生,因此在操作数据之前先获取锁,确保线程串行执行。
- 例如Synchronized、Lock都属于悲观锁
乐观锁:
- 认为线程安全问题不一定会发生,因此不加锁,只是在更新数据时去判断有没有其它线程对数据做了修改。
- 如果没有修改则认为是安全的,自己才更新数据。
- 如果已经被其它线程修改说明发生了安全问题,此时可以重试或异常
3.3.2 基于乐观锁(CAS)的解决方案
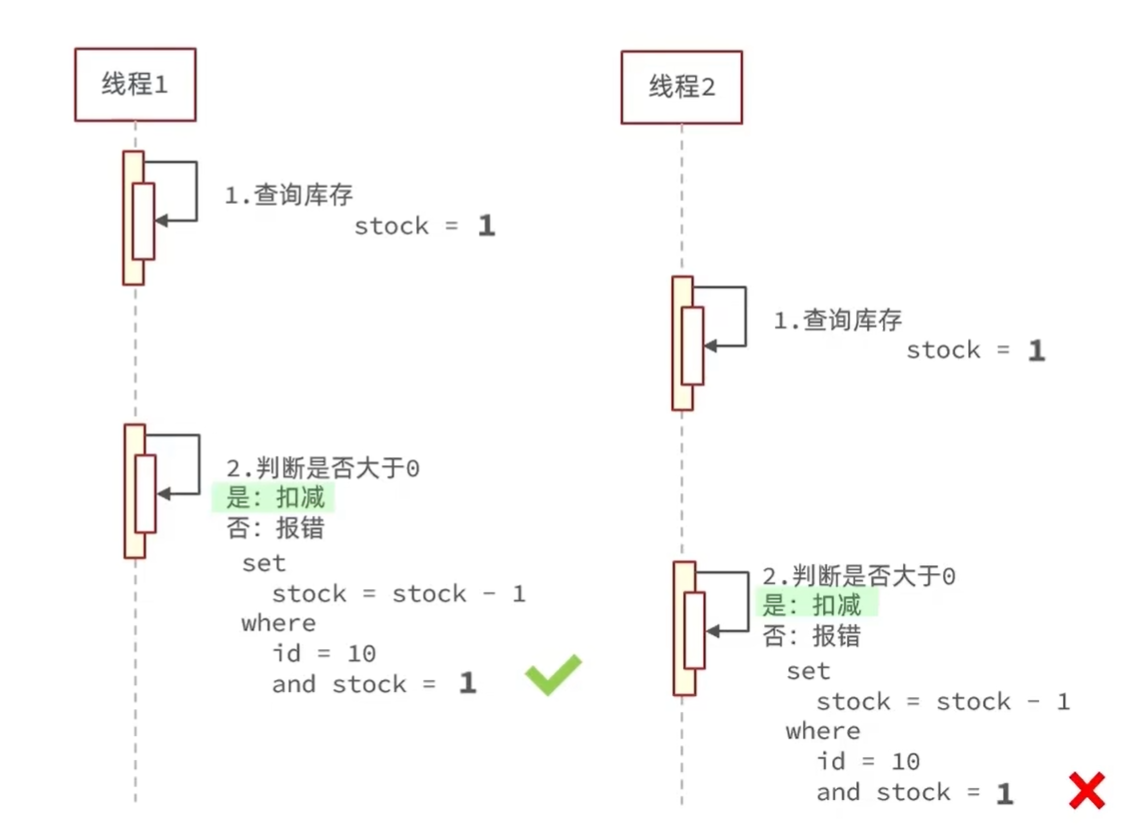
只要我扣减库存时的库存和之前我查询到的库存是一样的,就意味着没有人在中间修改过库存,那么此时就是安全的。我们的乐观锁需要变一下,改成stock大于0 即可
1 | |
3.3.3 总结
超卖这样的线程安全问题,解决方案有哪些?
- 悲观锁:添加同步锁,让线程串行执行
- 优点:简单粗暴
- 缺点:性能一般
- 乐观锁:不加锁,在更新时判断是否有其它线程在修改
- 优点:性能好
- 缺点:存在成功率低的问题
3.4 一人一单
修改秒杀业务,要求同一个优惠券,一个用户只能下一单
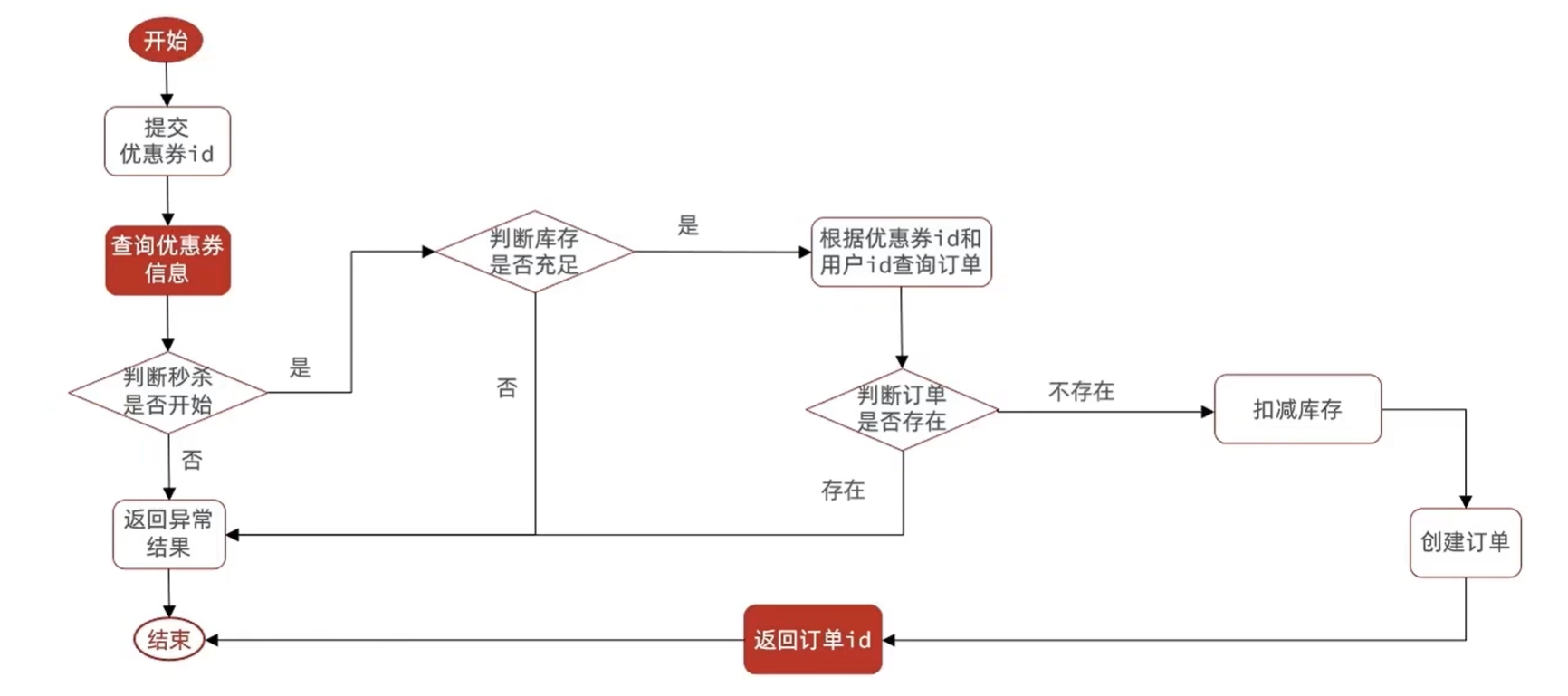
1 | |
为了确保线程安全,在方法上添加了一把synchronized 锁
1 | |
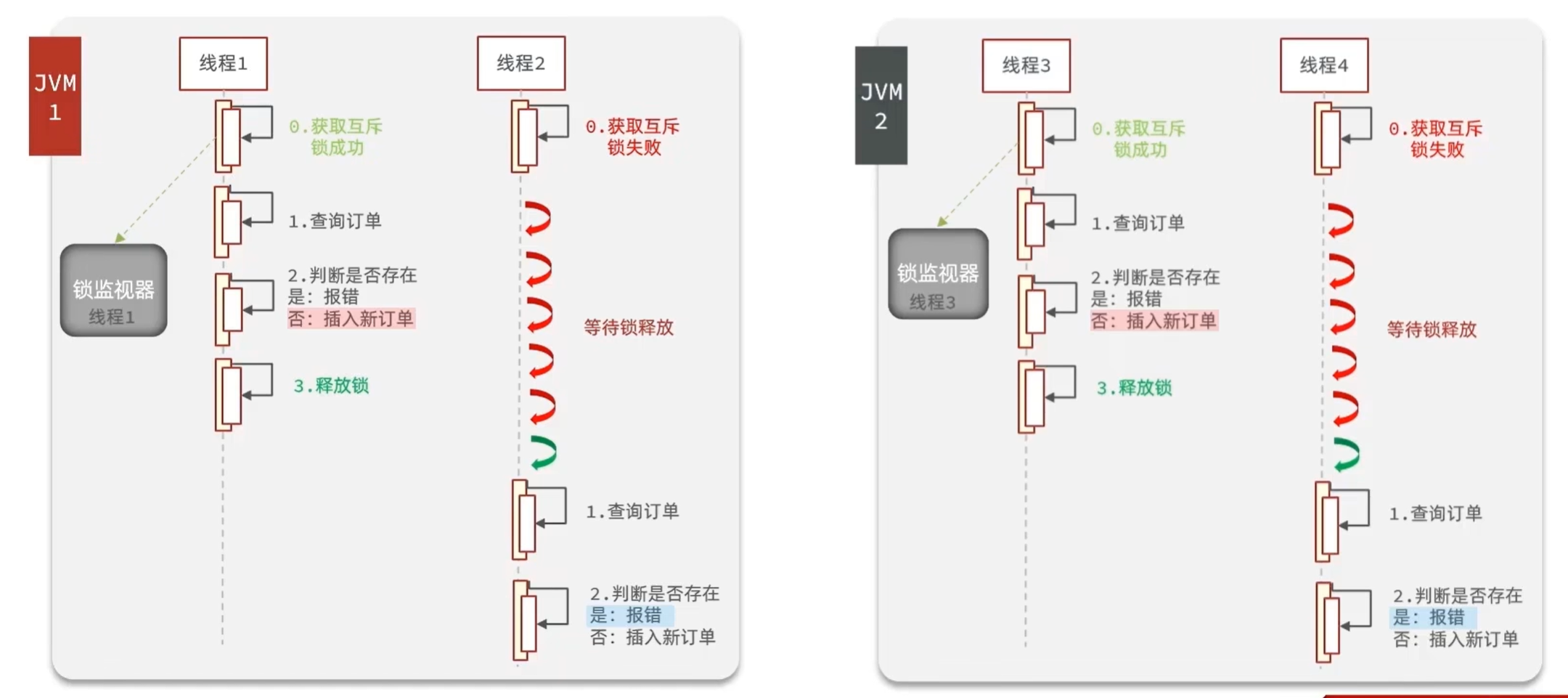
3.5 集群环境下一人一单的并发安全问题
通过加锁可以解决在单机情况下的一人一单安全问题,但是在集群模式下就不行了
由于现在我们部署了多个tomcat,每个tomcat都有一个属于自己的jvm,每个JVM都有各自的锁监视器,导致不同JVM的锁在不同的锁监视器中。那么假设在服务器A的tomcat内部,有两个线程,这两个线程由于使用的是同一份代码,那么他们的锁对象是同一个,是可以实现互斥的,但是如果现在是服务器B的tomcat内部,又有两个线程,但是他们的锁对象写的虽然和服务器A一样,但是锁对象却不是同一个,所以线程3和线程4可以实现互斥,但是却无法和线程1和线程2实现互斥,这就是 集群环境下,syn锁失效的原因,在这种情况下,我们就需要使用分布式锁来解决这个问题。
3.6 秒杀优化-异步秒杀
- 我们将耗时比较短的逻辑判断放入到redis中,比如是否库存足够,比如是否一人一单,这样的操作,只要这种逻辑可以完成,就意味着我们是一定可以下单完成的,我们只需要进行快速的逻辑判断,根本就不用等下单逻辑走完,我们直接给用户返回成功
- 再在后台开一个线程,后台线程慢慢的去执行queue里边的消息
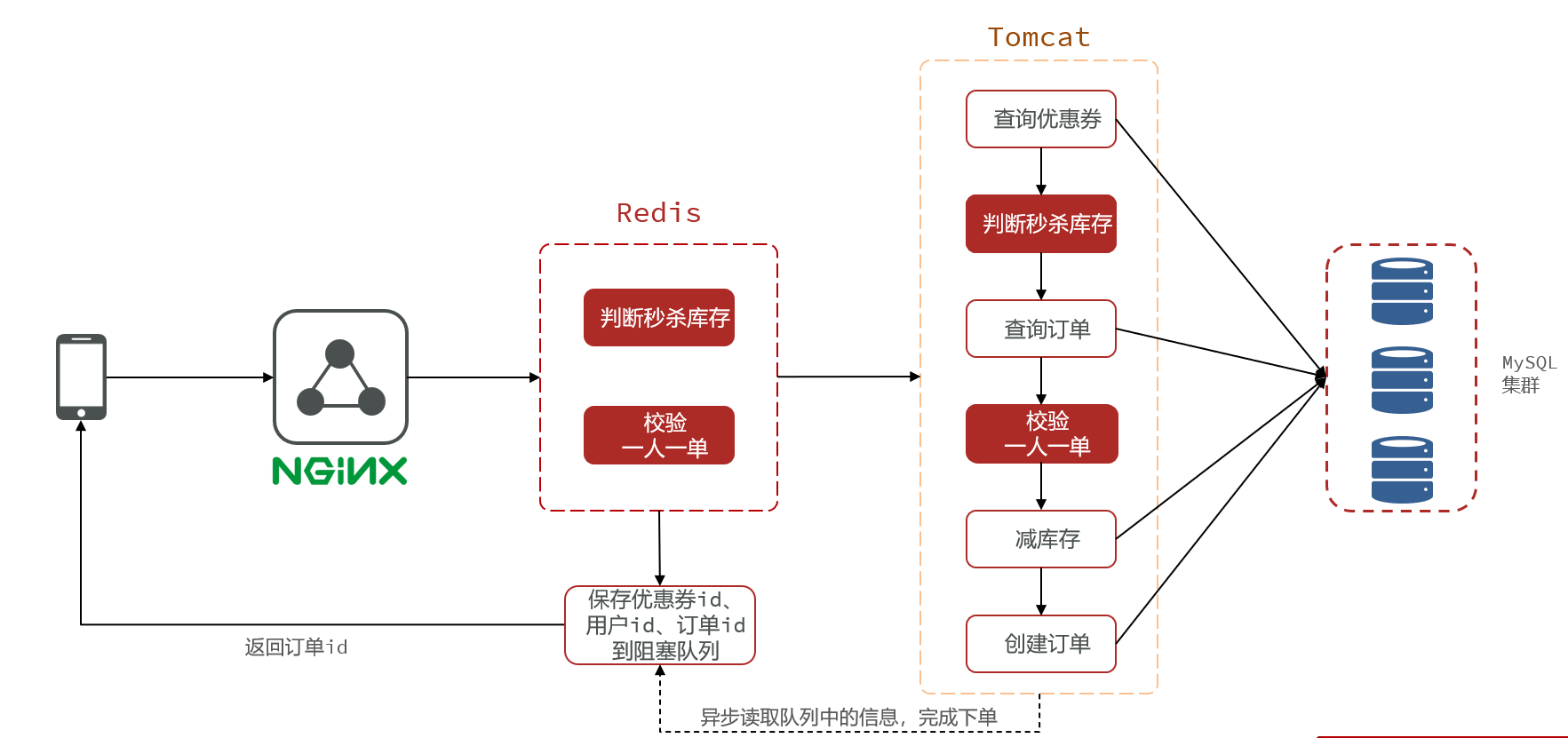
当用户下单之后,判断库存是否充足只需要导redis中去根据key找对应的value是否大于0即可,如果不充足,则直接结束,如果充足,继续在redis中判断用户是否可以下单,如果set集合中没有这条数据,说明他可以下单,如果set集合中没有这条记录,则将userId和优惠卷存入到redis中,并且返回0,整个过程需要保证是原子性的,我们可以使用lua来操作
当以上判断逻辑走完之后,我们可以判断当前redis中返回的结果是否是0 ,如果是0,则表示可以下单,则将之前说的信息存入到到queue中去,然后返回,然后再来个线程异步的下单,前端可以通过返回的订单id来判断是否下单成功。
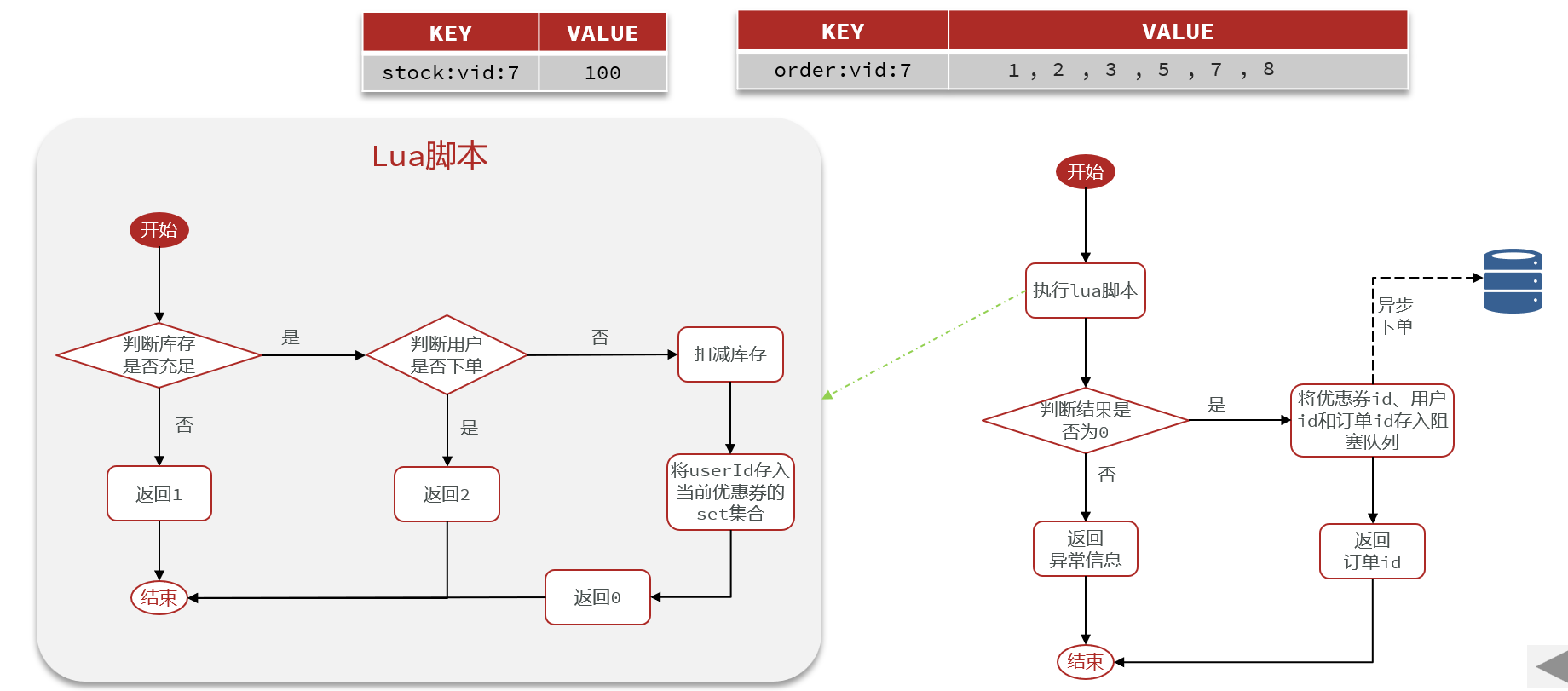
3.7 秒杀优化-Redis完成秒杀资格判断
需求:
新增秒杀优惠券的同时,将优惠券信息保存到Redis中
基于Lua脚本,判断秒杀库存、一人一单,决定用户是否抢购成功
如果抢购成功,将优惠券id和用户id封装后存入阻塞队列
开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能
新增秒杀优惠券的同时,将优惠券信息保存到Redis中
1 | |
- 基于Lua脚本,判断秒杀库存、一人一单,决定用户是否抢购成功
1 | |
VoucherOrderServiceImpl:
1 | |
3.8 秒杀优化-基于阻塞队列实现秒杀优化
- 如果抢购成功,将优惠券id和用户id封装后存入阻塞队列
- 开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能
修改下单动作,现在我们去下单时,是通过lua表达式去原子执行判断逻辑,如果判断我出来不为0 ,则要么是库存不足,要么是重复下单,返回错误信息,如果是0,则把下单的逻辑保存到队列中去,然后异步执行
1 | |
小总结:
秒杀业务的优化思路是什么?
- 先利用Redis完成库存余量、一人一单判断,完成抢单业务
- 再将下单业务放入阻塞队列,利用独立线程异步下单
- 基于阻塞队列的异步秒杀存在哪些问题?
- 内存限制问题
- 数据安全问题
4. 分布式锁
4.1 基本原理和实现方式对比
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁。
分布式锁的核心思想就是让大家都使用同一把锁,只要大家使用的是同一把锁,那么我们就能锁住线程,不让线程进行,让程序串行执行,这就是分布式锁的核心思路
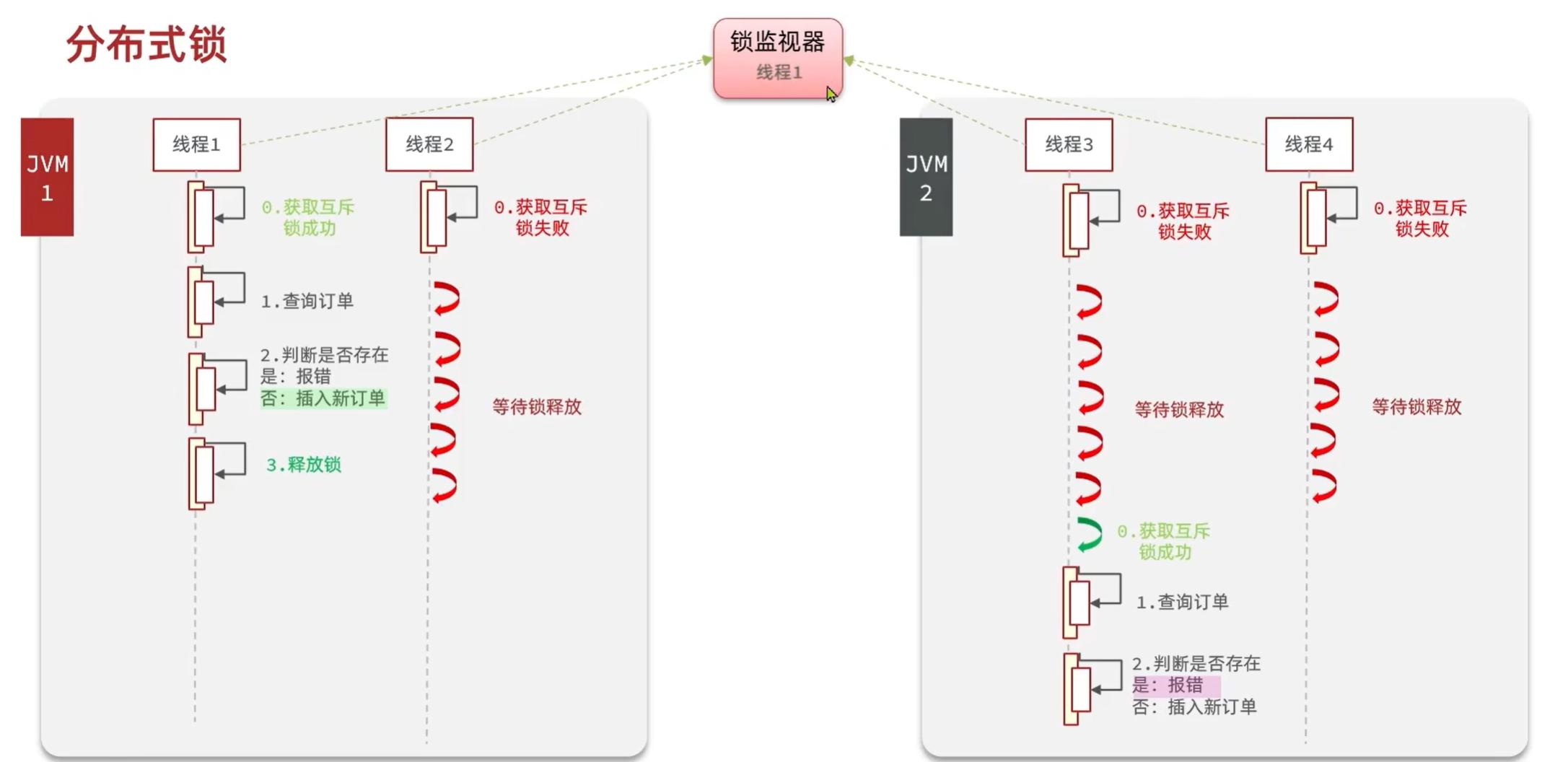
- 分布式锁需要满足的条件
- 可见性
- 互斥
- 高可用
- 高性能
- 安全性
常见的分布式锁有三种:
| MySQL | Redis | Zookeeper | |
|---|---|---|---|
| 互斥 | 利用MySQL本身的互斥锁机制 | 利用setnx这样的互斥命令 | 利用节点的唯一性和有序性实现互斥 |
| 高可用 | 好 | 好 | 好 |
| 高性能 | 一般 | 好 | 一般 |
| 安全性 | 断开连接,自动释放锁 | 利用锁超时时间,到期释放 | 临时节点,断开连接自动释放 |
4.2 基于Redis的分布式锁
实现分布式锁时需要实现的两个基本方法:
- 获取锁:
- 互斥:确保只能有一个线程获取锁
- 非阻塞:尝试一次,成功返回true,失败返回false
1 | |
- 释放锁:
- 手动释放
- 超时释放:获取锁时添加一个超时时间
1 | |
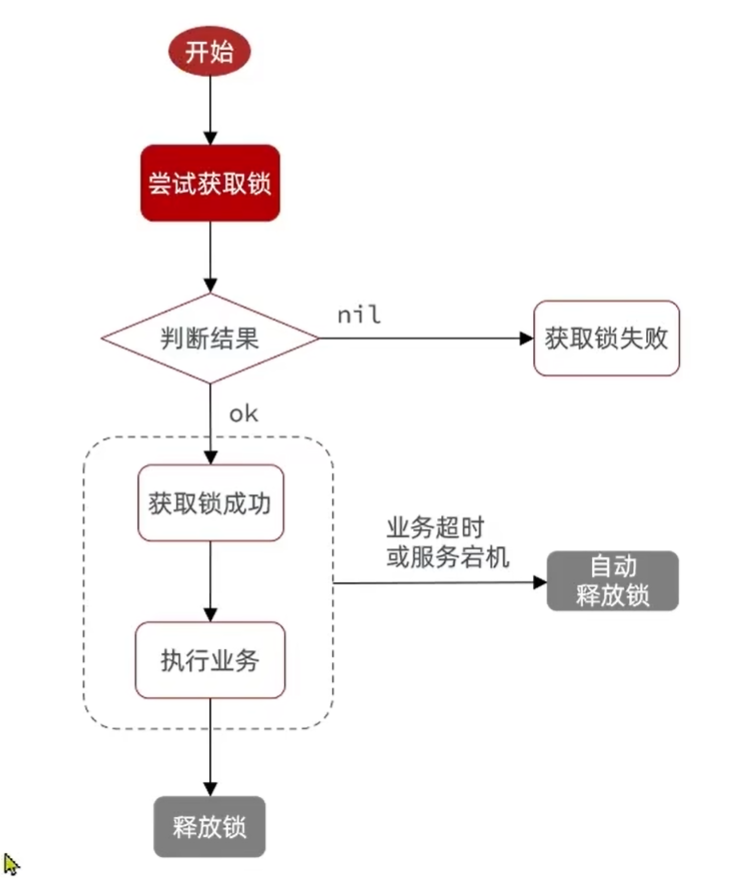
我们利用redis 的setNx 方法,当有多个线程进入时,我们就利用该方法,第一个线程进入时,redis 中就有这个key 了,返回了1,如果结果是1,则表示他抢到了锁,那么他去执行业务,然后再删除锁,退出锁逻辑,没有抢到锁的哥们,等待一定时间后重试即可
4.3 实现分布式锁(版本一)
- 利用setnx方法进行加锁,同时增加过期时间,防止死锁,此方法可以保证加锁和增加过期时间具有原子性
- 释放锁逻辑
- 释放锁,防止删除别人的锁
1 | |
- 修改业务代码:
1 | |
4.4 Redis分布式锁误删情况
持有锁的线程在锁的内部出现了阻塞,导致他的锁自动释放,这时其他线程,线程2来尝试获得锁,就拿到了这把锁,然后线程2在持有锁执行过程中,线程1反应过来,继续执行,而线程1执行过程中,走到了删除锁逻辑,此时就会把本应该属于线程2的锁进行删除,这就是误删别人锁的情况说明
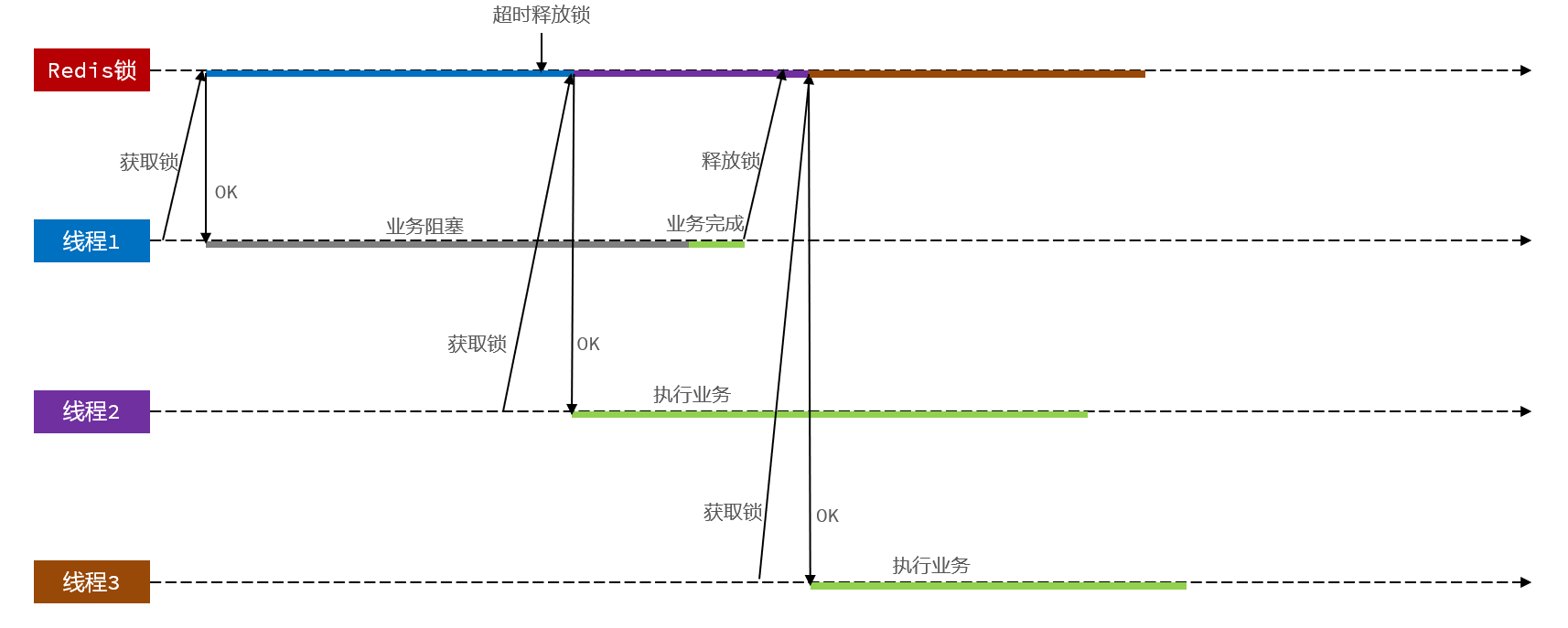
解决方案就是在每个线程释放锁的时候,去判断一下当前这把锁是否属于自己,如果属于自己,则不进行锁的删除
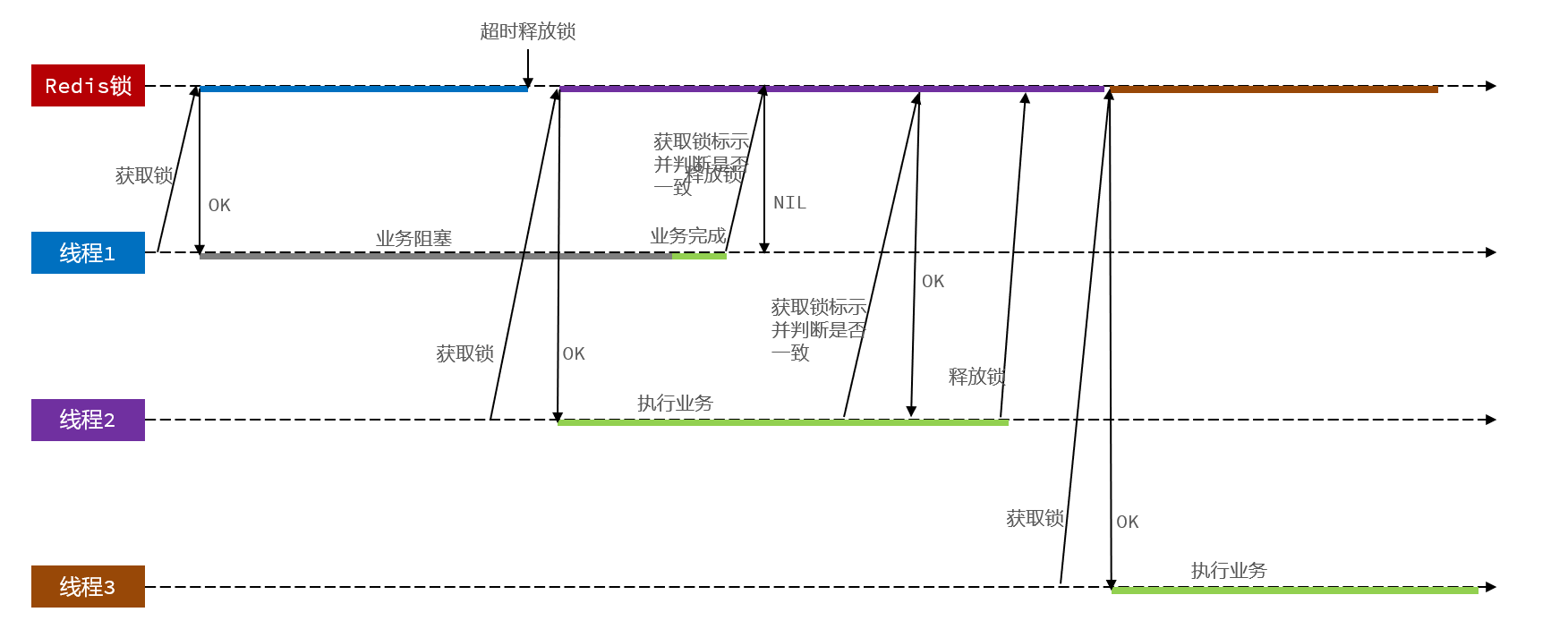
解决Redis分布式锁误删问题
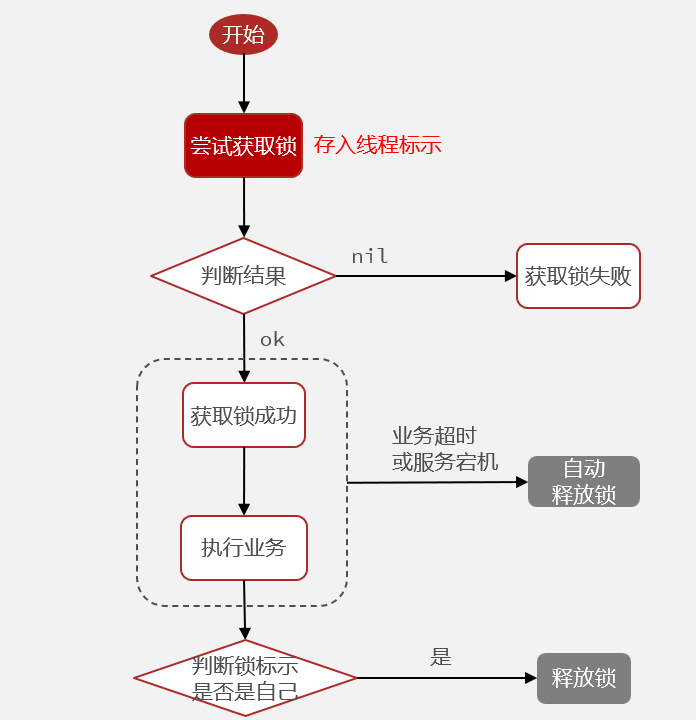
需求:修改之前的分布式锁实现,满足:
- 在获取锁时存入线程标示(可以用UUID表示)
- 在释放锁时先获取锁中的线程标示,判断是否与当前线程标示一致
- 如果一致则释放锁
- 如果不一致则不释放锁
加锁:
1 | |
释放锁:先判断,再释放
1 | |
4.5 分布式锁的原子性问题
线程1现在持有锁之后,在执行业务逻辑过程中,他正准备删除锁,而且已经走到了条件判断的过程中,比如他已经拿到了当前这把锁确实是属于他自己的,正准备删除锁,但是此时他的锁到期了,那么此时线程2进来,但是线程1他会接着往后执行,当他卡顿结束后,他直接就会执行删除锁那行代码,相当于条件判断并没有起到作用,这就是删锁时的原子性问题,之所以有这个问题,是因为线程1的拿锁,比锁,删锁,实际上并不是原子性的
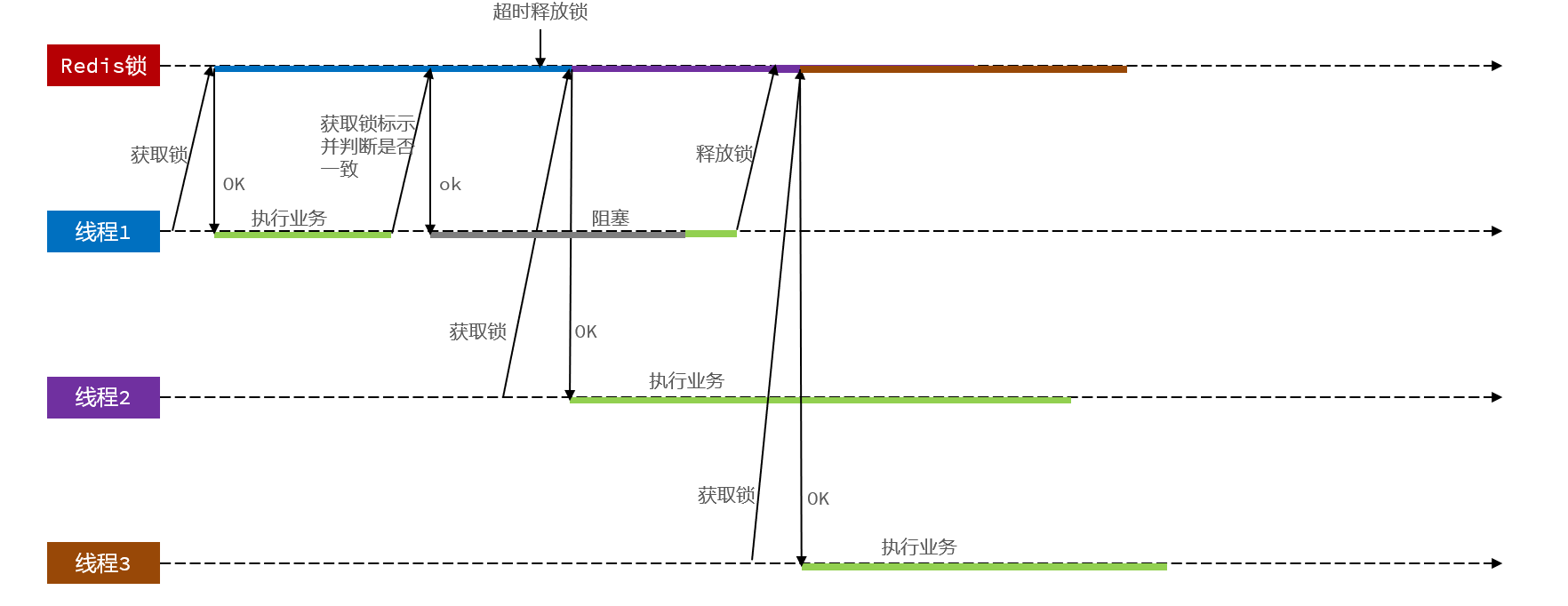
4.6 Lua脚本解决多条命令原子性问题
Redis提供了Lua脚本功能,在一个脚本中编写多条Redis命令,确保多条命令执行时的原子性
Redis提供的调用函数,语法如下:
1 | |
例如,我们要执行set name jack,则脚本是这样:
1 | |
例如,我们要先执行set name Rose,再执行get name,则脚本如下:
1 | |
- 释放锁的业务流程是这样的
- 获取锁中的线程标示
- 判断是否与指定的标示(当前线程标示)一致
- 如果一致则释放锁(删除)
- 如果不一致则什么都不做
最终我们操作redis的拿锁比锁删锁的lua脚本就会变成这样
1 | |
4.7 利用Java代码调用Lua脚本改造分布式锁
RedisTemplate中,可以利用execute方法去执行lua脚本
1 | |
4.8 基于Redis的分布式锁实现思路
- 利用set nx ex获取锁,并设置过期时间,保存线程标示
- 释放锁时先判断线程标示是否与自己一致,一致则删除锁
- 特性:
- 利用set nx满足互斥性
- 利用set ex保证故障时锁依然能释放,避免死锁,提高安全性
- 利用Redis集群保证高可用和高并发特性
- 特性:
4.9 分布式锁-redission功能介绍
基于setnx实现的分布式锁存在下面的问题:
- 不可重入问题:同一个线程无法多次获取同一把锁
- 不可重试:获取锁只尝试一次就返回false,没有重试机制
- 超时释放:: 锁超时释放虽然可以避免死锁,但如果是业务执行耗时较长,也会导致锁释放,存在安全隐患
- 主从一致性: :如果Redis提供了主从集群,主从同步存在延迟,当主宕机时,如果从并同步主中的锁数据,则会出现锁实现
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。
Redission提供了分布式锁的多种多样的功能
4.10 分布式锁-Redission快速入门
- 引入依赖:
1 | |
- 配置Redisson客户端:
1 | |
- 使用Redission的分布式锁
1 | |
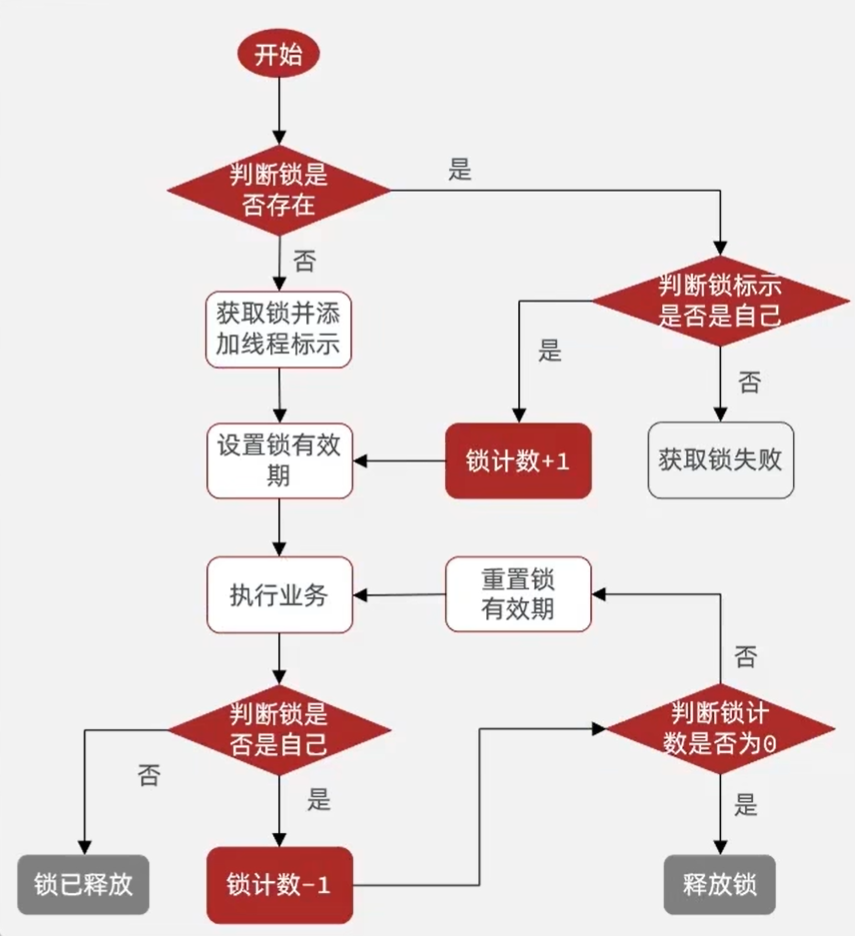
4.11 分布式锁-redission可重入锁原理
1 | |
4.12 分布式锁-redission 锁重试和WatchDog机制
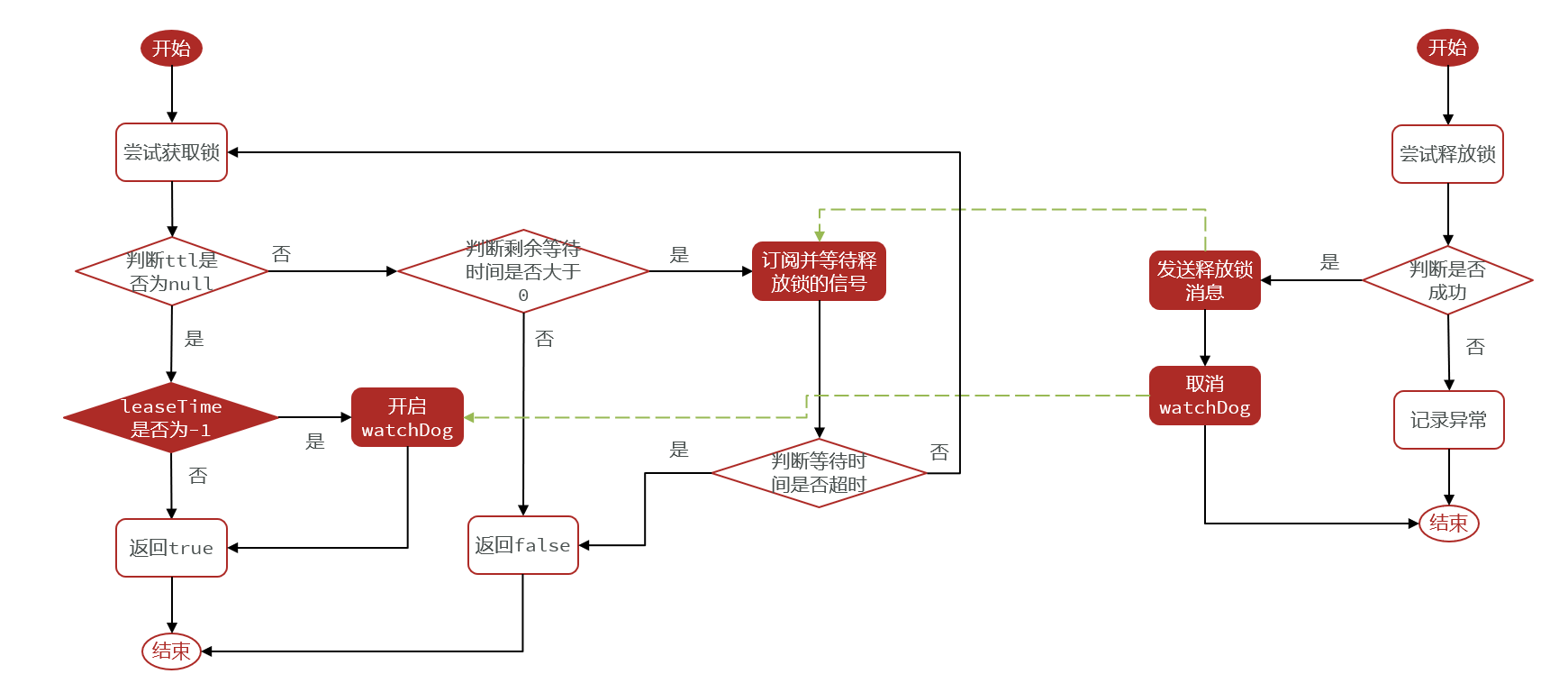
Redisson分布式锁原理:
- 可重入:利用hash结构记录线程id和重入次数
- 可重试:利用信号量和PubSub功能实现等待、唤醒,获取锁失败的重试机制
- 超时续约:利用watchDog,每隔一段时间(releaseTime / 3),重置超时时间
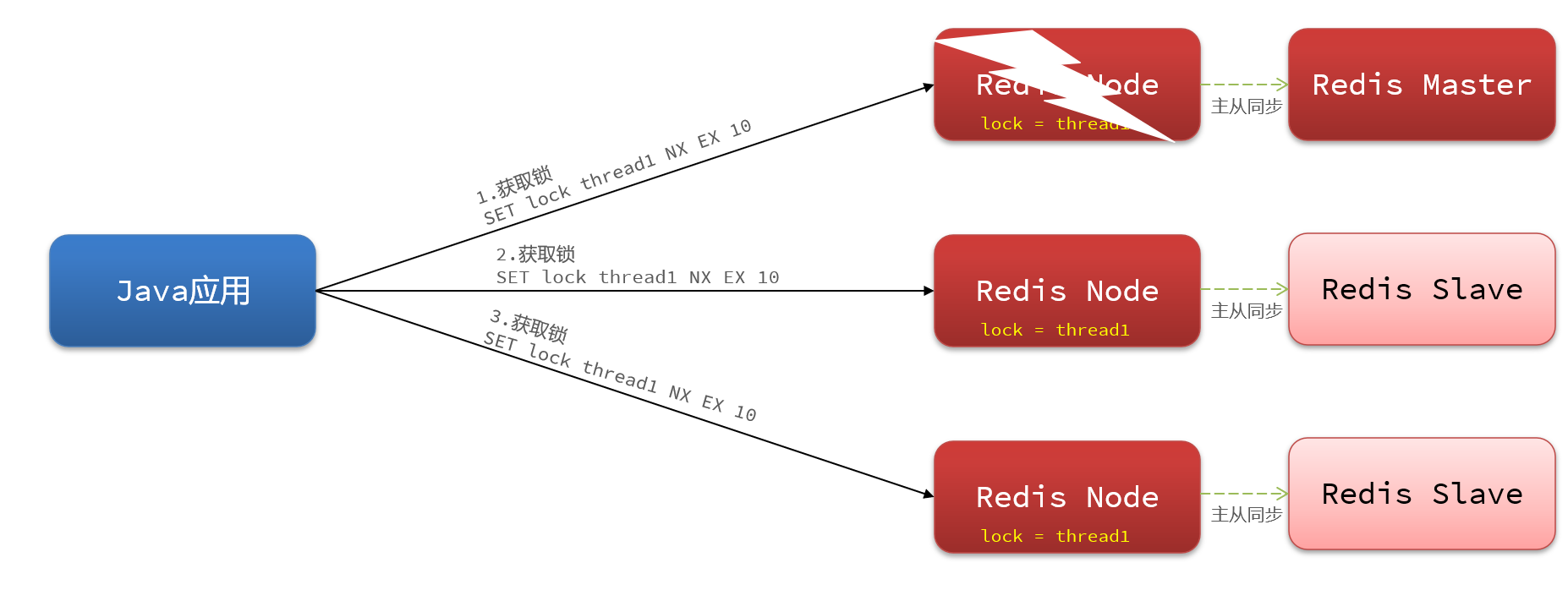
4.13 分布式锁-redission 锁的MutiLock原理
redission提出来了MutiLock锁,使用这把锁咱们就不使用主从了,每个节点的地位都是一样的
这把锁加锁的逻辑需要写入到每一个主丛节点上,只有所有的服务器都写入成功,此时才是加锁成功,假设现在某个节点挂了,那么他去获得锁的时候,只要有一个节点拿不到,都不能算是加锁成功,就保证了加锁的可靠性。
总结
- 不可重入Redis分布式锁:
- 原理:利用setnx的互斥性;利用ex避免死锁;释放锁时判断线程标示
- 缺陷:不可重入、无法重试、锁超时失效
- 可重入的Redis分布式锁:
- 原理:利用hash结构,记录线程标示和重入次数;利用watchDog延续锁时间;利用信号量控制锁重试等待
- 缺陷:redis宕机引起锁失效问题
- Redisson的multiLock:
- 原理:多个独立的Redis节点,必须在所有节点都获取重入锁,才算获取锁成功
- 缺陷:运维成本高、实现复杂
5. Redis消息队列(实现异步秒杀)
5.1 认识消息队列
什么是消息队列:字面意思就是存放消息的队列。最简单的消息队列模型包括3个角色:
- 消息队列:存储和管理消息,也被称为消息代理(Message Broker)
- 生产者:发送消息到消息队列
- 消费者:从消息队列获取消息并处理消息
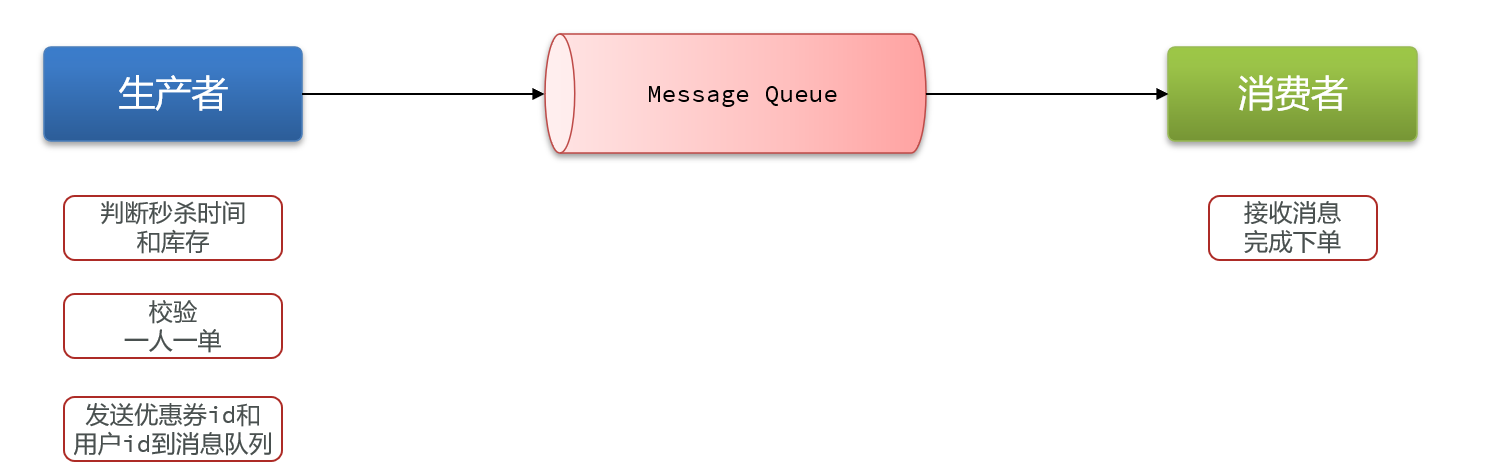
Redis提供了三种不同的方式来实现消息队列:
- list结构:基于List结构模拟消息队列
- PubSub:基本的点对点消息模型
- Stream:比较完善的消息队列模型
5.2 基于List实现消息队列
只能单个生产者单个消费者
消息队列(Message Queue),字面意思就是存放消息的队列。而Redis的list数据结构是一个双向链表,很容易模拟出队列效果。
- 队列是入口和出口不在一边,因此我们可以利用:LPUSH 结合 RPOP、或者 RPUSH 结合 LPOP来实现。
- 不过要注意的是,当队列中没有消息时RPOP或LPOP操作会返回null,并不像JVM的阻塞队列那样会阻塞并等待消息。因此这里应该使用BRPOP或者BLPOP来实现阻塞效果。

基于List的消息队列有哪些优缺点?
优点:
- 利用Redis存储,不受限于JVM内存上限
- 基于Redis的持久化机制,数据安全性有保证
- 可以满足消息有序性
缺点:
- 无法避免消息丢失
- 只支持单消费者
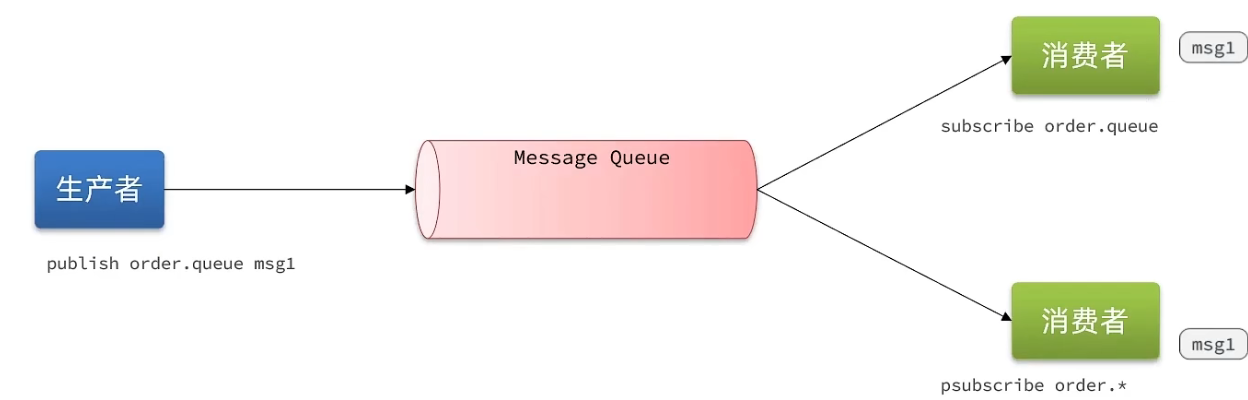
5.3 基于PubSub的消息队列
可以多生产多消费
PubSub(发布订阅)是Redis2.0版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个channel,生产者向对应channel发送消息后,所有订阅者都能收到相关消息。
常用命令:
SUBSCRIBE channel [channel]:订阅一个或多个频道PUBLISH channel msg:向一个频道发送消息PSUBSCRIBE pattern[pattern]:订阅与pattern格式匹配的所有频道
基于PubSub的消息队列有哪些优缺点?
优点:
- 采用发布订阅模型,支持多生产、多消费
缺点:
- 不支持数据持久化
- 无法避免消息丢失
- 消息堆积有上限,超出时数据丢失
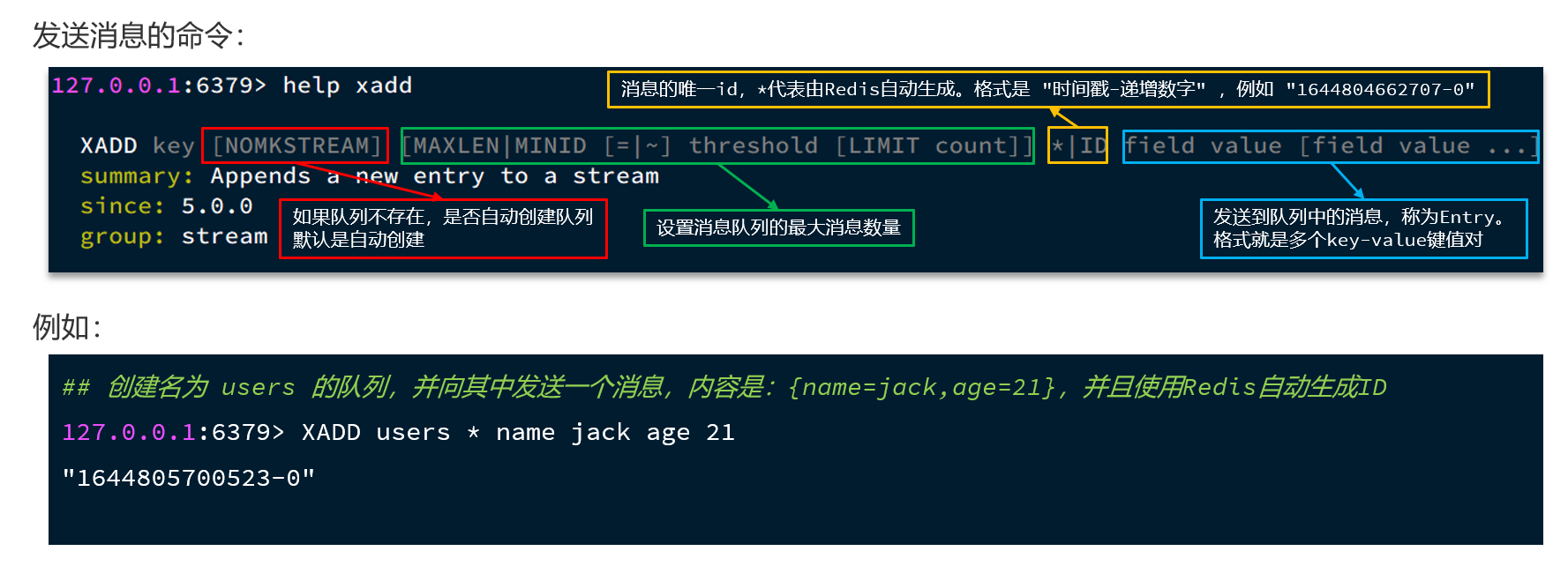
5.4 基于Stream的消息队列
Stream 是 Redis 5.0 引入的一种新数据类型,可以实现一个功能非常完善的消息队列。
- 发送消息的命令:
- 读取消息的方式之一:XREAD
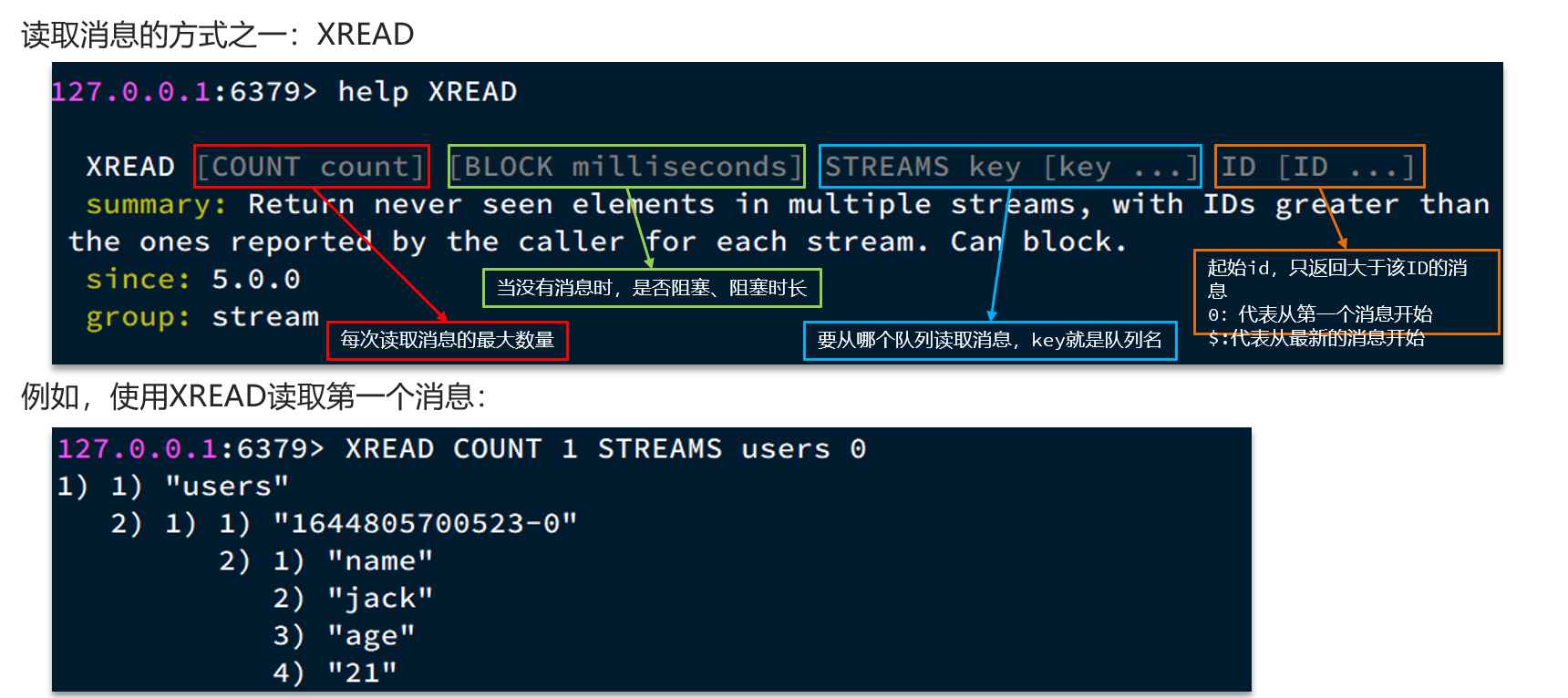
- XREAD阻塞方式,读取最新的消息:

- 在业务开发中,我们可以循环的调用XREAD阻塞方式来查询最新消息,从而实现持续监听队列的效果,伪代码如下

STREAM类型消息队列的XREAD命令特点:
- 消息可回溯
- 一个消息可以被多个消费者读取
- 可以阻塞读取
- 有消息漏读的风险
5.5 基于Stream的消息队列-消费者组
消费者组(Consumer Group):将多个消费者划分到一个组中,监听同一个队列。具备下列特点:
- 消息分流
- 队列中的消息会分流给组内的不同消费者,而不是重复消费,从而加快消息处理的速度
- 消息标示
- 消费者组会维护一个标示,记录最后一个被处理的消息,哪怕消费者宕机重启,还会从标示之后读取消息。确保每一个消息都会被消费
- 消息确认
- 消费者获取消息后,消息处于pending状态,并存入一个pending-list。当处理完成后需要通过XACK来确认消息,标记消息为已处理,才会从pending-list移除。
创建消费者组
1 | |
- key:队列名称
- groupName:消费者组名称
- ID:起始ID标示,$代表队列中最后一个消息,0则代表队列中第一个消息
- MKSTREAM:队列不存在时自动创建队列
删除指定的消费者组
1 | |
给指定的消费者组添加消费者
1 | |
删除消费者组中的指定消费者
1 | |
从消费者组读取消息:
1 | |
- group:消费组名称
- consumer:消费者名称,如果消费者不存在,会自动创建一个消费者
- count:本次查询的最大数量
- BLOCK milliseconds:当没有消息时最长等待时间
- NOACK:无需手动ACK,获取到消息后自动确认
- STREAMS key:指定队列名称
- ID:获取消息的起始ID:
- “>”:从下一个未消费的消息开始
- 其它:根据指定id从pending-list中获取已消费但未确认的消息,例如0,是从pending-list中的第一个消息开始
消费者监听消息的基本思路:

STREAM类型消息队列的XREADGROUP命令特点:
- 消息可回溯
- 可以多消费者争抢消息,加快消费速度
- 可以阻塞读取
- 没有消息漏读的风险
- 有消息确认机制,保证消息至少被消费一次
对比:
| List | PubSub | Stream | |
|---|---|---|---|
| 消息持久化 | 支持 | 不支持 | 支持 |
| 阻塞读取 | 支持 | 支持 | 支持 |
| 消息堆积处理 | 受限于内存空间,可以利用多消费者加快处理 | 受限于消费者缓冲区 | 受限于队列长度,可以利用消费者组提高消费速度,减少堆积 |
| 消息确认机制 | 不支持 | 不支持 | 支持 |
| 消息回溯 | 不支持 | 不支持 | 支持 |
5.6 基于Redis的Stream结构作为消息队列,实现异步秒杀下单
- 创建一个Stream类型的消息队列,名为stream.orders
- 修改之前的秒杀下单Lua脚本,在认定有抢购资格后,直接向stream.orders中添加消息,内容包含voucherId、userId、orderId
- 项目启动时,开启一个线程任务,尝试获取stream.orders中的消息,完成下单
VoucherOrderServiceImpl:
1 | |
6. 达人探店
6.1 发布探店笔记
探店笔记类似点评网站的评价,往往是图文结合。对应的表有两个:
- tb_blog:探店笔记表,包含笔记中的标题、文字、图片等
- tb_blog_comments:其他用户对探店笔记的评价
6.1.1 上传接口
1 | |
6.1.2 BlogController
1 | |
6.1.3 BlogServiceImpl
实现查看发布探店笔记的接口
1 | |
6.2 点赞功能
需求:
- 同一个用户只能点赞一次,再次点击则取消点赞
- 如果当前用户已经点赞,则点赞按钮高亮显示(前端已实现,判断字段Blog类的isLike属性)
- 为什么采用set集合:因为我们的数据是不能重复的
1 | |
实现步骤:
- 给Blog类中添加一个isLike字段,标示是否被当前用户点赞
- 修改点赞功能,利用Redis的set集合判断是否点赞过,未点赞过则点赞数+1,已点赞过则点赞数-1
- 修改根据id查询Blog的业务,判断当前登录用户是否点赞过,赋值给isLike字段
- 修改分页查询Blog业务,判断当前登录用户是否点赞过,赋值给isLike字段
6.3 点赞排行榜
在探店笔记的详情页面,应该把给该笔记点赞的人显示出来,比如最早点赞的TOP5,形成点赞排行榜
之前的点赞是放到set集合,但是set集合是不能排序的,所以这个时候,咱们可以采用一个可以排序的set集合,就是咱们的sortedSet
| List | Set | SortedSet | |
|---|---|---|---|
| 排序方式 | 按添加顺序排序 | 无法排序 | 根据score值排序 |
| 唯一性 | 不唯一 | 唯一 | 唯一 |
| 查找方式 | 按索引查找或首尾查找 | 根据元素查找 | 根据元素查找 |
6.3.1 BlogServiceImpl
点赞逻辑代码
1 | |
6.3.2 点赞列表查询列表
BlogController
1 | |
BlogService
1 | |
7. 好友关注
7.1 关注和取消关注
需求:基于该表数据结构,实现两个接口:
- 关注和取关接口
- 判断是否关注的接口
关注是User之间的关系,是博主与粉丝的关系,数据库中有一张tb_follow表来标示
7.1.1 FollowController
1 | |
7.1.2 FollowService
1 | |
7.2 共同关注
想要去看共同关注的好友,需要首先进入到这个页面,这个页面会发起两个请求
- 去查询用户的详情
- 去查询用户的笔记
需求:利用Redis中恰当的数据结构,实现共同关注功能。在博主个人页面展示出当前用户与博主的共同关注呢。
- 当然是使用我们之前学习过的set集合咯,在set集合中,有交集并集补集的api,我们可以把两人的关注的人分别放入到一个set集合中,然后再通过api去查看这两个set集合中的交集数据。
FollowServiceImpl
1 | |
FollowServiceImpl
1 | |
7.3 共同推送-Feed流实现方案
关注推送也叫做Feed流,直译为投喂。为用户持续的提供“沉浸式”的体验,通过无限下拉刷新获取新的信息
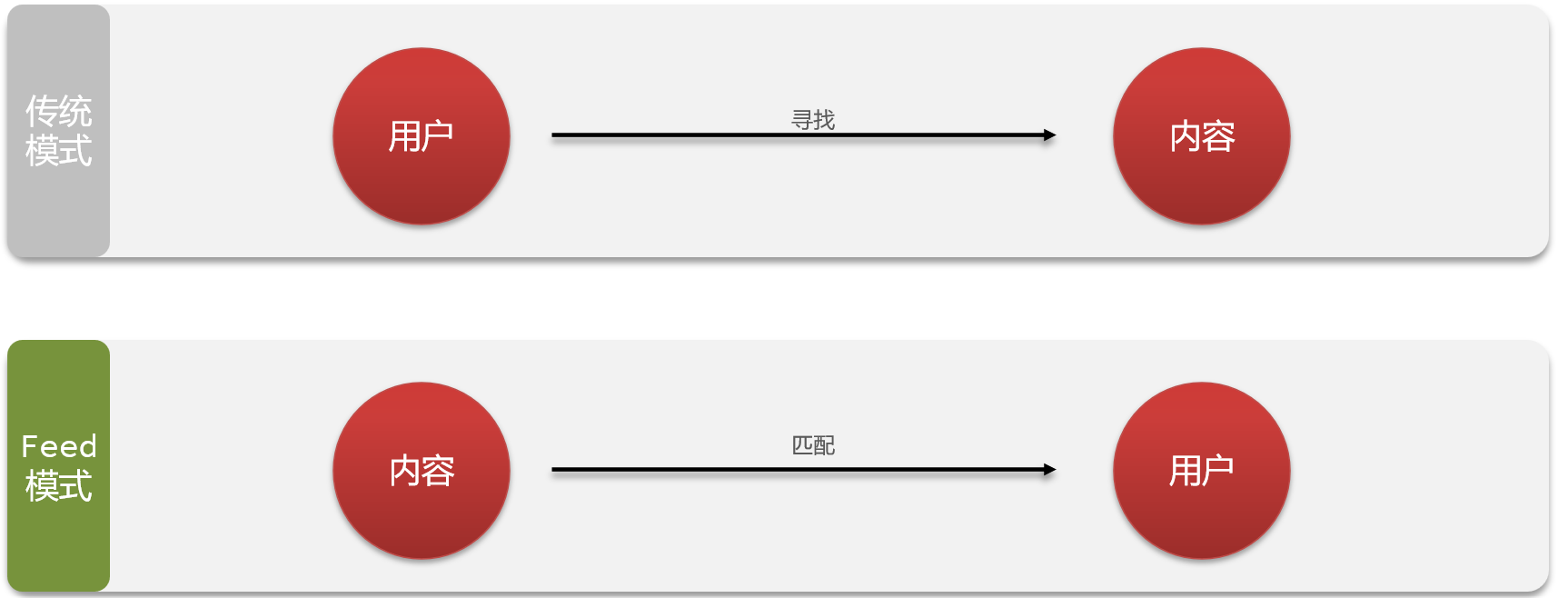
7.3.1 Feed流产品有两种常见模式
Timeline:不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注。例如朋友圈
- 优点:信息全面,不会有缺失。并且实现也相对简单
- 缺点:信息噪音较多,用户不一定感兴趣,内容获取效率低
智能排序:利用智能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣信息来吸引用户
- 优点:投喂用户感兴趣信息,用户粘度很高,容易沉迷
- 缺点:如果算法不精准,可能起到反作用
本例中的个人页面,是基于关注的好友来做Feed流,因此采用Timeline的模式。该模式的实现方案有三种:
我们本次针对好友的操作,采用的就是Timeline的方式,只需要拿到我们关注用户的信息,然后按照时间排序即可
7.3.2 Timeline的三种模式
- 拉模式
- 推模式
- 推拉结合
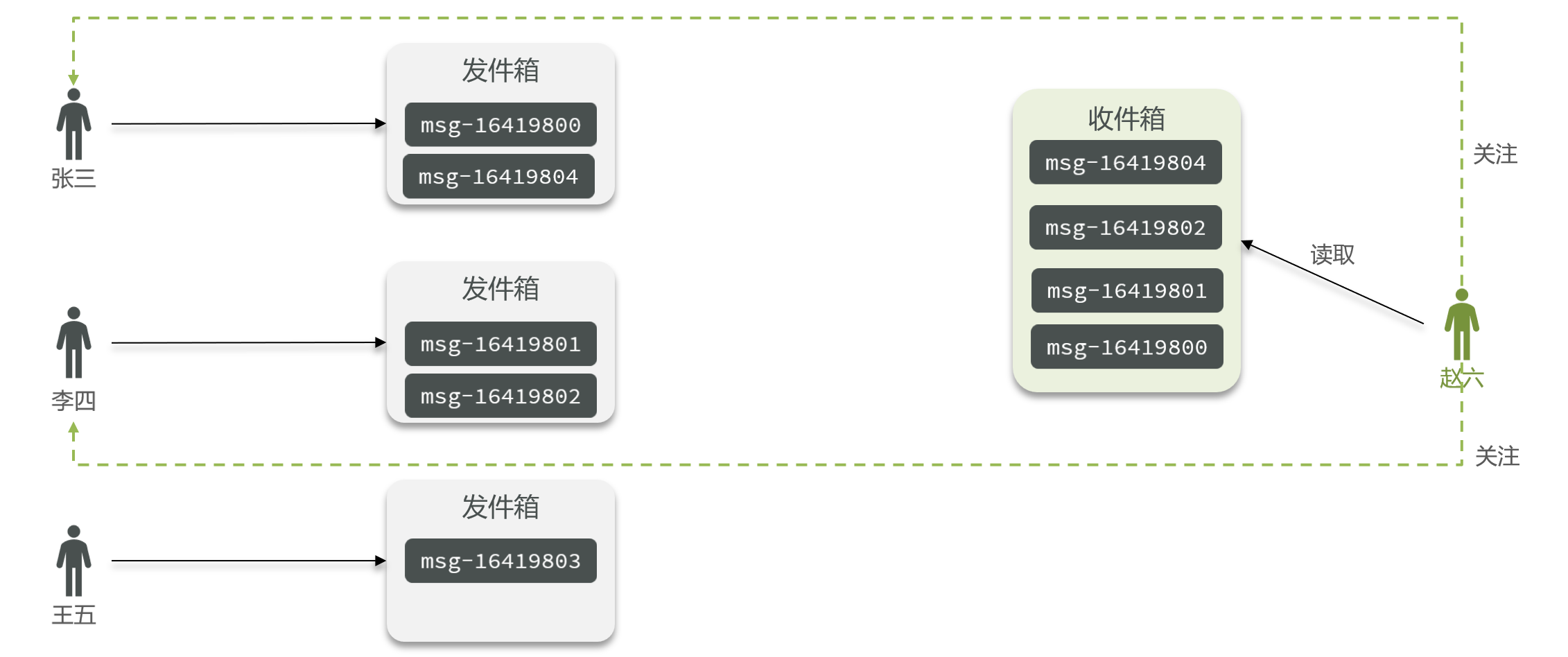
拉模式:也叫做读扩散
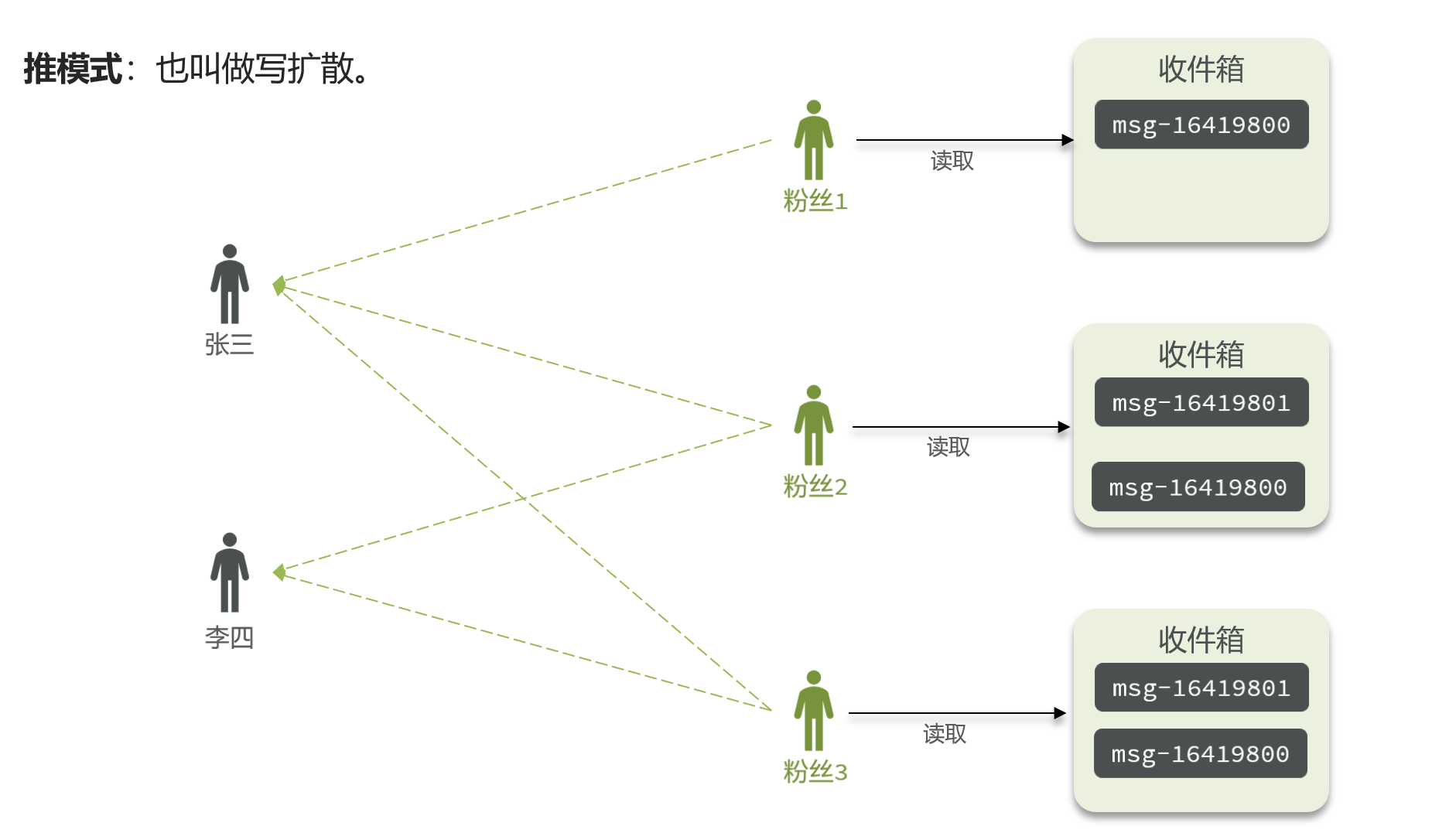
推模式:也叫做写扩散。
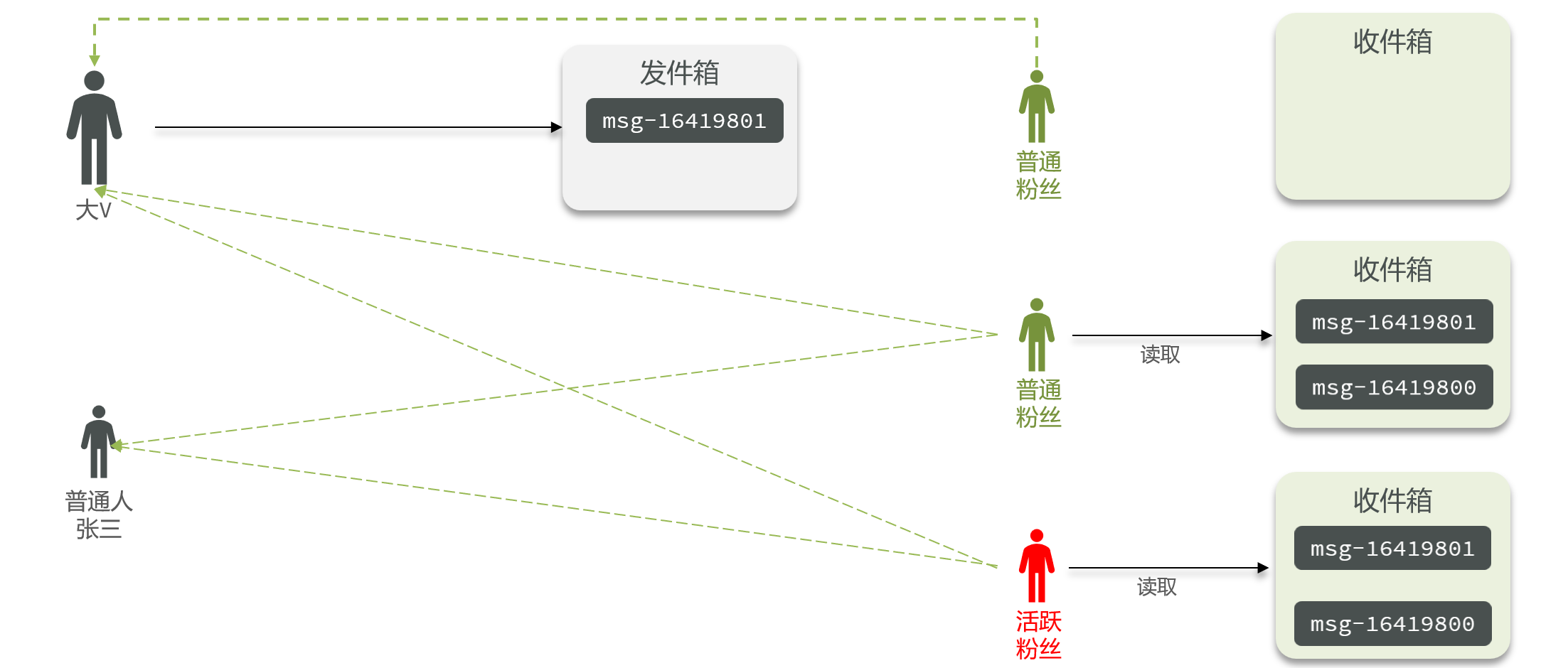
推拉结合模式:也叫做读写混合,兼具推和拉两种模式的优点
三种模式对比:
| 拉模式 | 推模式 | 推拉结合 | |
|---|---|---|---|
| 写比例 | 低 | 高 | 中 |
| 读比例 | 高 | 低 | 中 |
| 用户读取延迟 | 高 | 低 | 低 |
| 实现难度 | 复杂 | 简单 | 很复杂 |
| 使用场景 | 很少使用 | 用户量少、没有大V | 过千万的用户量,有大V |
7.4 推送到粉丝收件箱
需求:
- 修改新增探店笔记的业务,在保存blog到数据库的同时,推送到粉丝的收件箱
- 收件箱满足可以根据时间戳排序,必须用Redis的数据结构实现
- 查询收件箱数据时,可以实现分页查询
Feed流的滚动分页
- Feed流中的数据会不断更新,所以数据的角标也在变化,因此不能采用传统的分页模式。
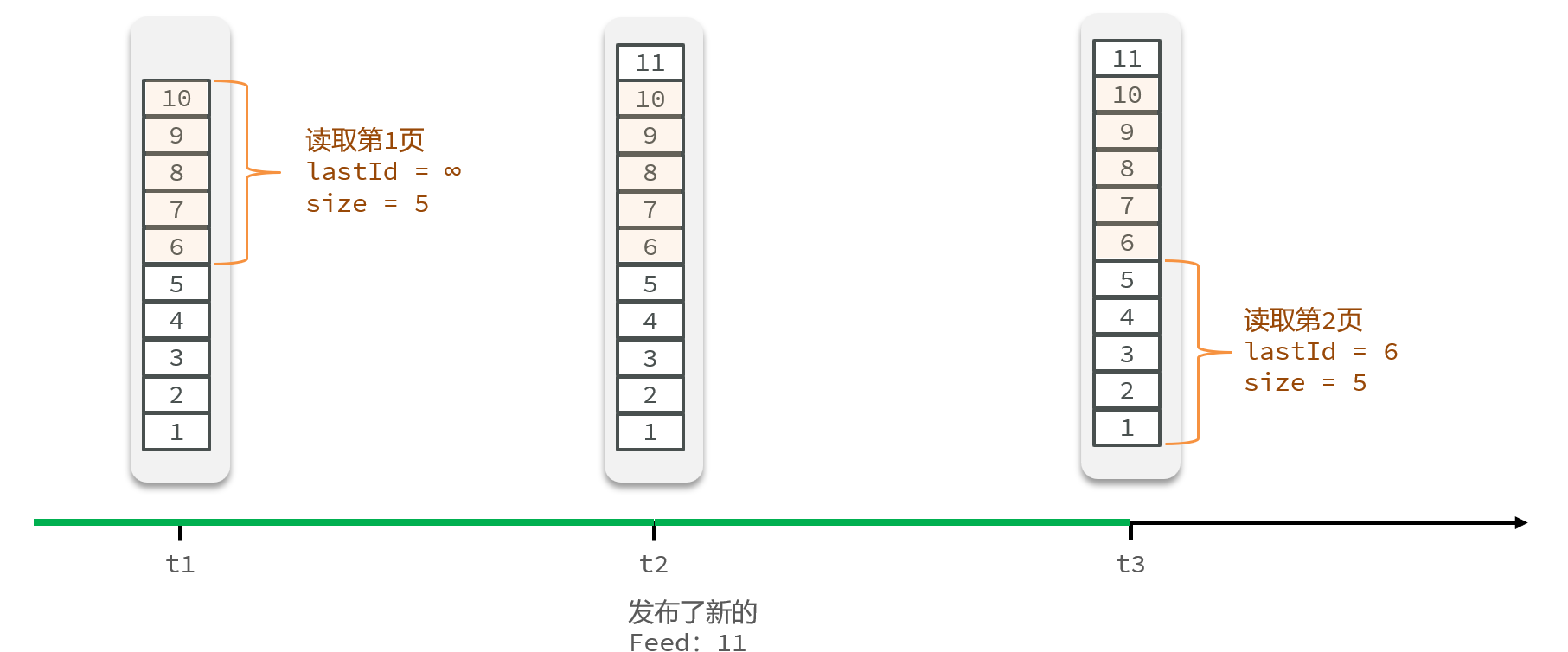
我们在保存完探店笔记后,获得到当前笔记的粉丝,然后把数据推送到粉丝的redis中去。
代码如下:
1 | |
7.5 实现关注推送页面的分页查询
需求:在个人主页的“关注”卡片中,查询并展示推送的Blog信息:
- 每次查询完成后,我们要分析出查询出数据的最小时间戳,这个值会作为下一次查询的条件
- 我们需要找到与上一次查询相同的查询个数作为偏移量,下次查询时,跳过这些查询过的数据,拿到我们需要的数据
- 综上:我们的请求参数中就需要携带 lastId:上一次查询的最小时间戳 和偏移量这两个参数
7.5.1 定义出来具体的返回值实体类
1 | |
7.5.2 BlogController
1 | |
7.5.3 BlogServiceImpl
1 | |
8. 附近商户
8.1 GEO数据结构
GEO就是Geolocation的简写形式,代表地理坐标。Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。常见的命令有:
- GEOADD:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)
- GEODIST:计算指定的两个点之间的距离并返回
- GEOHASH:将指定member的坐标转为hash字符串形式并返回
- GEOPOS:返回指定member的坐标
- GEORADIUS:指定圆心、半径,找到该圆内包含的所有member,并按照与圆心之间的距离排序后返回。6.以后已废弃
- GEOSEARCH:在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2.新功能
- GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。 6.2.新功能
8.2 附近商户搜索
8.2.1 导入店铺数据到GEO
- 我们要做的事情是:将数据库表中的数据导入到redis中去,redis中的GEO,GEO在redis中就一个menber和一个经纬度,我们把x和y轴传入到redis做的经纬度位置去,但我们不能把所有的数据都放入到menber中去,毕竟作为redis是一个内存级数据库,如果存海量数据,redis还是力不从心,所以我们在这个地方存储他的id即可。
- 但是这个时候还有一个问题,就是在redis中并没有存储type,所以我们无法根据type来对数据进行筛选,所以我们可以按照商户类型做分组,类型相同的商户作为同一组,以typeId为key存入同一个GEO集合中即可
HmDianPingApplicationTests:
1 | |
8.2.2 实现附近商户功能
ShopController:
1 | |
ShopServiceImpl:
1 | |
9. 用户签到
9.1 BitMap用法
我们按月来统计用户签到信息,签到记录为1,未签到则记录为0
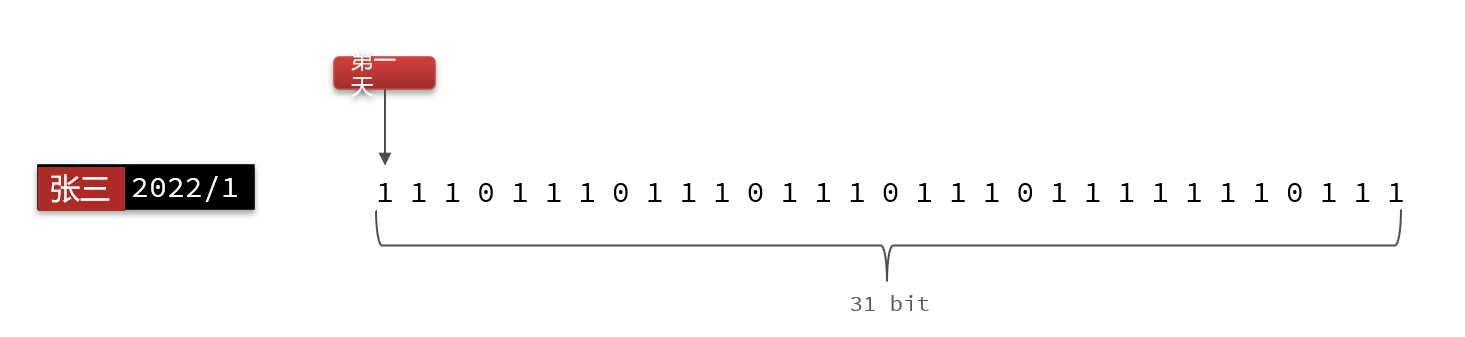
把每一个bit位对应当月的每一天,形成了映射关系。用0和1标示业务状态,这种思路就称为位图(BitMap)。这样我们就用极小的空间,来实现了大量数据的表示
BitMap的操作命令有:
- SETBIT:向指定位置(offset)存入一个0或1
- GETBIT :获取指定位置(offset)的bit值
- BITCOUNT :统计BitMap中值为1的bit位的数量
- BITFIELD :操作(查询、修改、自增)BitMap中bit数组中的指定位置(offset)的值
- BITFIELD_RO :获取BitMap中bit数组,并以十进制形式返回
- BITOP :将多个BitMap的结果做位运算(与 、或、异或)
- BITPOS :查找bit数组中指定范围内第一个0或1出现的位置
9.2 实现签到功能
需求:实现签到接口,将当前用户当天签到信息保存到Redis中
9.2.1 UserController
1 | |
9.2.2 UserServiceImpl
1 | |
9.3 签到统计
需求:实现下面接口,统计当前用户截止当前时间在本月的连续签到天数
- **问题1:**什么叫做连续签到天数?
- 从最后一次签到开始向前统计,直到遇到第一次未签到为止,计算总的签到次数,就是连续签到天数。
- **问题2:**如何得到本月到今天为止的所有签到数据?
- 假设今天是10号,那么我们就可以从当前月的第一天开始,获得到当前这一天的位数,是10号,那么就是10位,去拿这段时间的数据,就能拿到所有的数据了,那么这10天里边签到了多少次呢?统计有多少个1即可。
- 问题3:如何从后向前遍历每个bit位?
- 我们只需要让得到的10进制数字和1做与运算就可以了,因为1只有遇见1 才是1,其他数字都是0
- 我们把签到结果和1进行与操作,每与一次,就把签到结果向右移动一位,依次内推,我们就能完成逐个遍历的效果了。
9.3.1 UserController
1 | |
9.3.2 UserServiceImpl
1 | |
10. UV统计-HyperLogLog
首先我们搞懂两个概念:
- UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。
- PV:全称Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
- 通常来说UV会比PV大很多,所以衡量同一个网站的访问量,我们需要综合考虑很多因素,所以我们只是单纯的把这两个值作为一个参考值
- UV统计在服务端做会比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。但是如果每个访问的用户都保存到Redis中,数据量会非常恐怖,那怎么处理呢?
HyperLogLog
- Hyperloglog(HLL)是从Loglog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。
- Redis中的HLL是基于string结构实现的,单个HLL的内存永远小于16kb,内存占用低的令人发指!作为代价,其测量结果是概率性的,有小于0.81%的误差。不过对于UV统计来说,这完全可以忽略。
三. Redis高级篇
1. 分布式缓存
1.1 单点Redis的问题
数据丢失问题
- Redis是内存存储,服务重启可能会丢失数据
- 解决方案:实现Redis数据持久化
并发能力问题
- 单节点Redis并发能力虽然不错,但也无法满足如618这样的高并发场景
- 解决方案:搭建主从集群,实现读写分离
故障恢复问题
- 如果Redis宕机,则服务不可用,需要一种自动的故障恢复手段
- 解决方案:利用Redis哨兵,实现健康检测和自动恢复
存储能力问题
- Redis基于内存,单节点能存储的数据量难以满足海量数据需求
- 解决方案:搭建分片集群,利用插槽机制实现动态扩容
1.2 Redis持久化
Redis有两种持久化方案:
- RDB持久化
- AOF持久化
1.2.1 RDB持久化
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。快照文件称为RDB文件,默认是保存在当前运行目录。
1.2.1.1 RDB持久化在四种情况下会执行:
- 执行save命令
- 执行bgsave命令
- Redis停机时
- 触发RDB条件时
1.2.1.2 触发RDB条件
- Redis内部有触发RDB的机制,可以在redis.conf文件中找到,格式如下:
1 | |
- RDB的其它配置也可以在redis.conf文件中设置:
1 | |
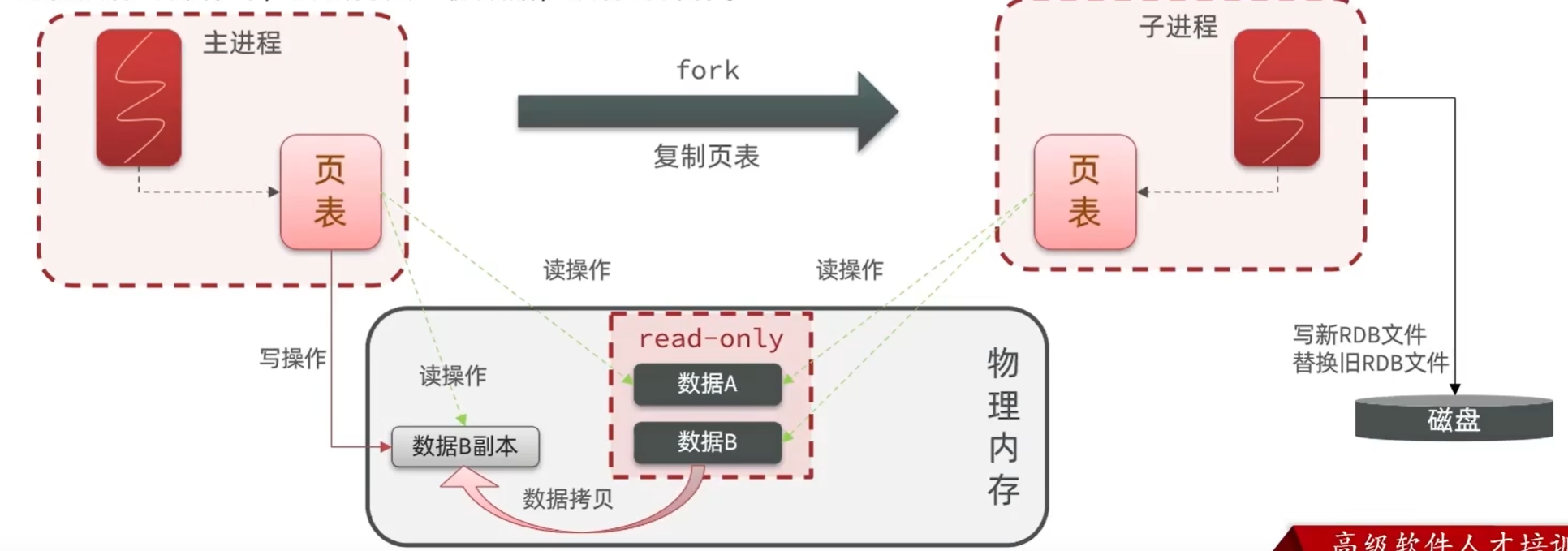
1.2.2 RDB原理
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入 RDB 文件。
fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存;
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。
1.2.3 RDB小结
RDB方式bgsave的基本流程?
- fork主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并写入新的RDB文件
- 用新RDB文件替换旧的RDB文件
RDB会在什么时候执行?save 60 1000代表什么含义?
- 默认是服务停止时
- 代表60秒内至少执行1000次修改则触发RDB
RDB的缺点?
- RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
- fork子进程、压缩、写出RDB文件都比较耗时
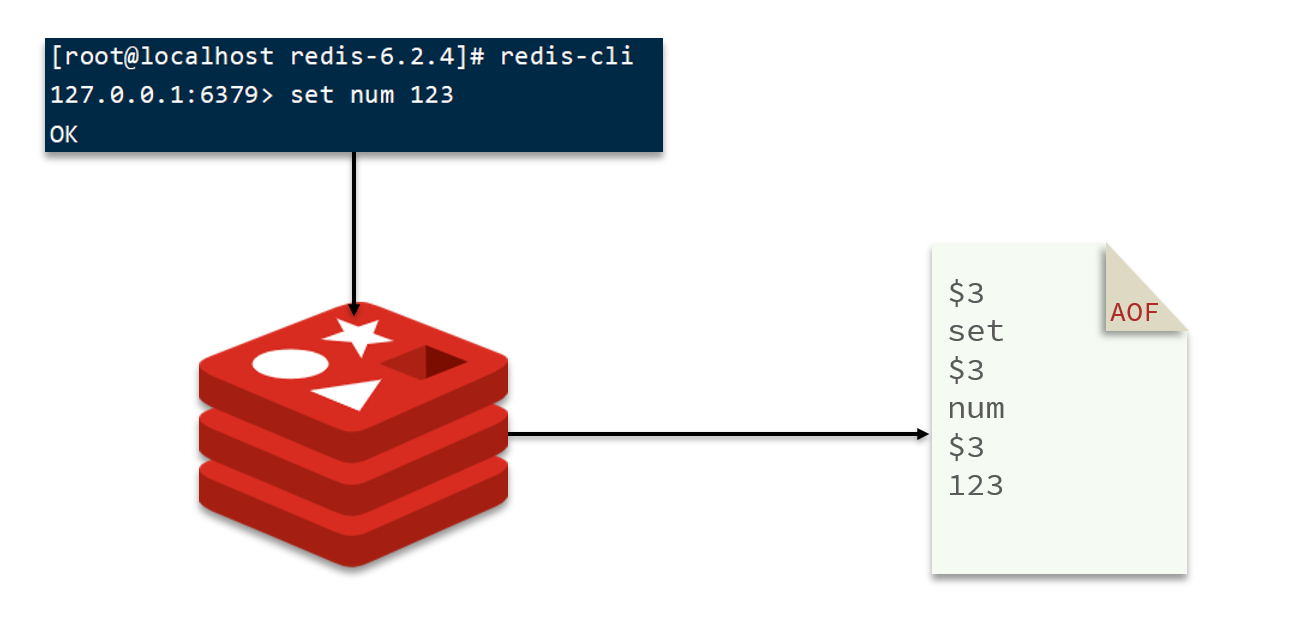
1.2.4 AOF持久化
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。
- AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:
1 | |
- AOF的命令记录的频率也可以通过redis.conf文件来配:
1 | |
1.2.5 AOF文件重写
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。

- Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置:
1 | |
1.2.6 RDB与AOF对比
RDB和AOF各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。
| RDB | AOF | |
|---|---|---|
| 持久化方式 | 定时对整个内存做快照 | 记录每一次执行的命令 |
| 数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷盘策略 |
| 文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积很大 |
| 宕机恢复速度 | 很快 | 慢 |
| 数据恢复优先级 | 低,因为数据完整性不如AOF | 高,因为数据完整性更高 |
| 系统资源占用 | 高,大量CPU和内存消耗 | 低,主要是磁盘IO资源 但AOF重写时会占用大量CPU和内存资源 |
| 使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高常见 |
2. Redis主从
- Redis主结点只写(master)
- Redis从结点只读(slave)
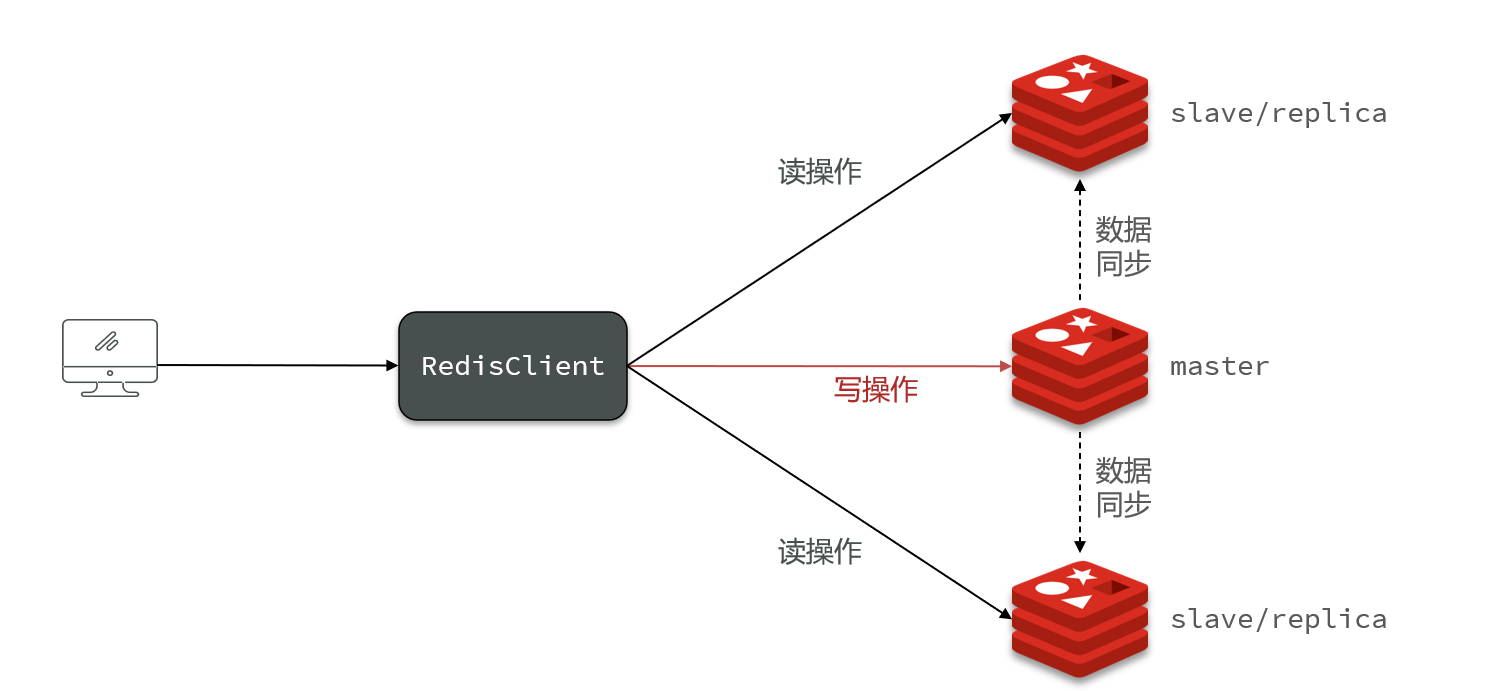
2.1 搭建主从架构
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
2.2 主从数据同步原理
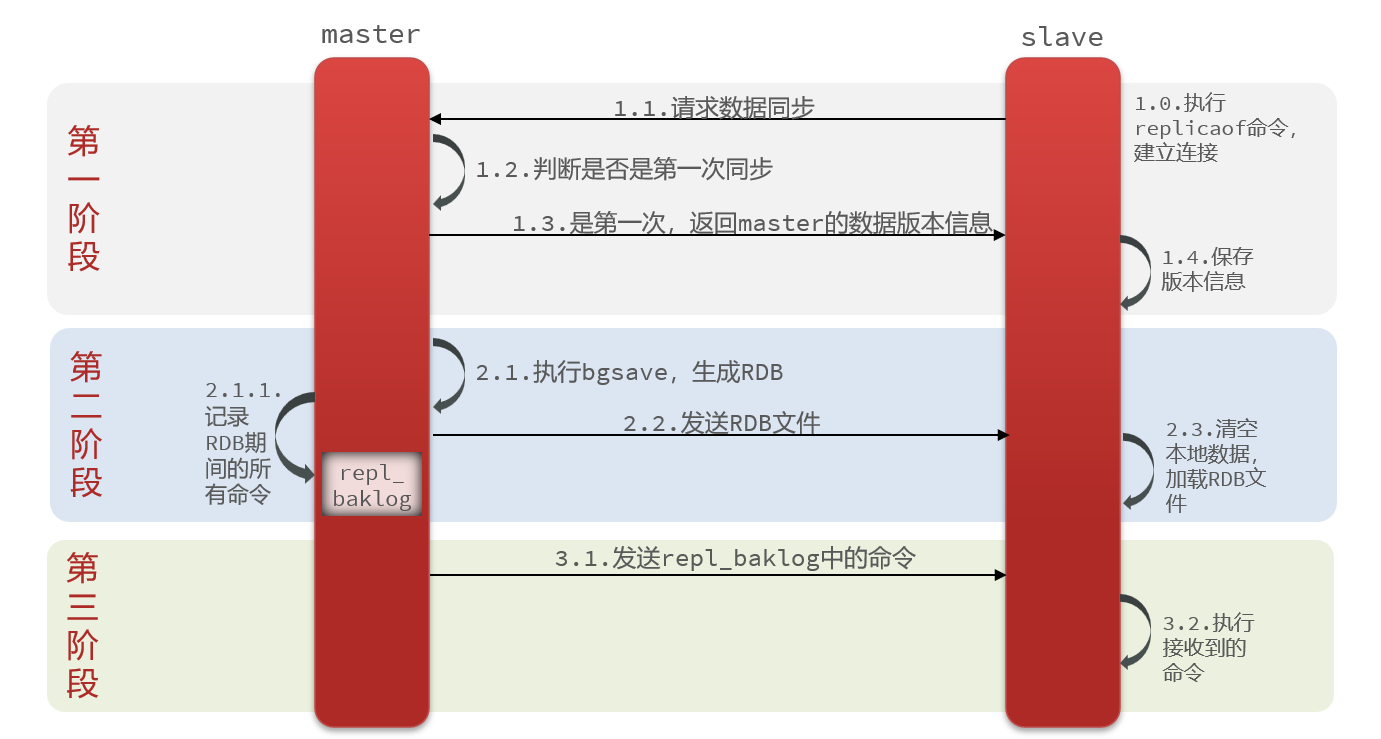
2.2.1 全量同步
主从第一次建立连接时,会执行全量同步,将master节点的所有数据都拷贝给slave节点:
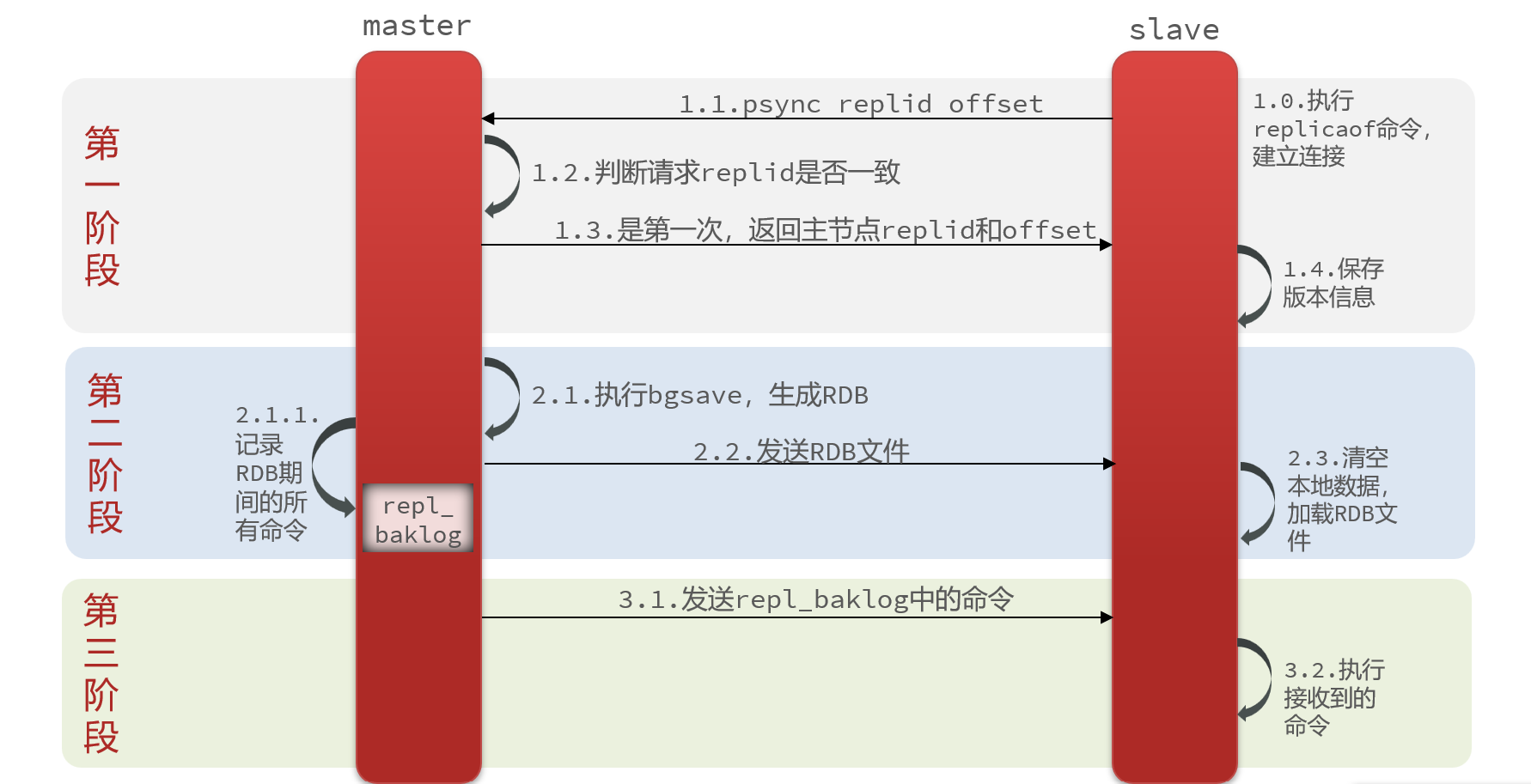
master如何得知salve是第一次来连接呢??
有几个概念,可以作为判断依据:
Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
因此slave做数据同步,必须向master声明自己的replication id 和offset,master才可以判断到底需要同步哪些数据。
因此,master判断一个节点是否是第一次同步的依据,就是看replid是否一致。
完整流程描述:
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
- slave执行接收到的命令,保持与master之间的同步
2.2.2 增量同步
全量同步需要先做RDB,然后将RDB文件通过网络传输个slave,成本太高了。因此除了第一次做全量同步,其它大多数时候slave与master都是做增量同步。
- 什么是增量同步?就是只更新slave与master存在差异的部分数据
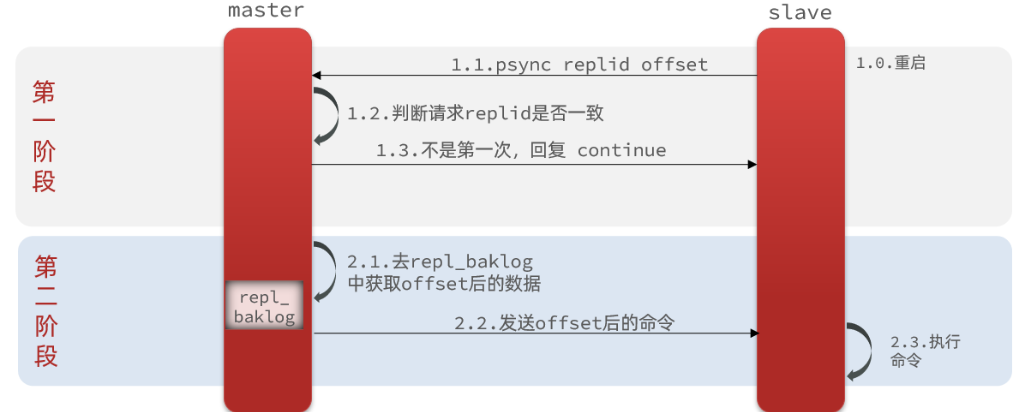
- repl_baklog中会记录Redis处理过的命令日志及offset,包括master当前的offset,和slave已经拷贝到的offset:
- slave与master的offset之间的差异,就是salve需要增量拷贝的数据了。
- repl_baklog大小有上限,写满后会覆盖最早的数据。如果slave断开时间过久,导致尚未备份的数据被覆盖,则无法基于log做增量同步,只能再次全量同步。
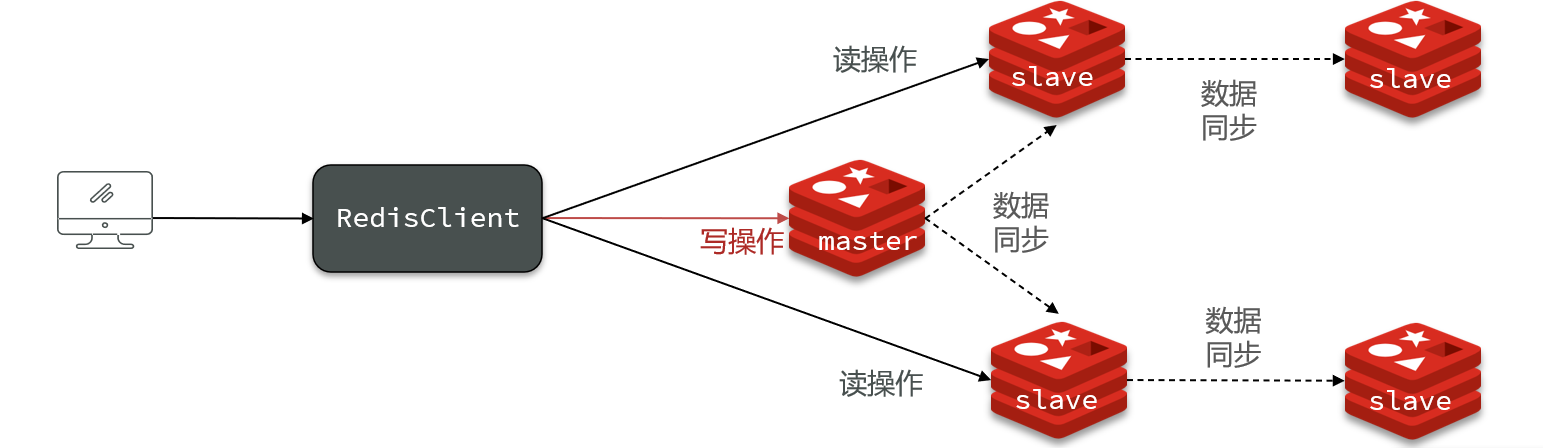
2.2.3 主从同步优化
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
2.2.4 小结
简述全量同步和增量同步区别?
- 全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
- 增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave
什么时候执行全量同步?
- slave节点第一次连接master节点时
- slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步?
- slave节点断开又恢复,并且在repl_baklog中能找到offset时
3. Redis哨兵
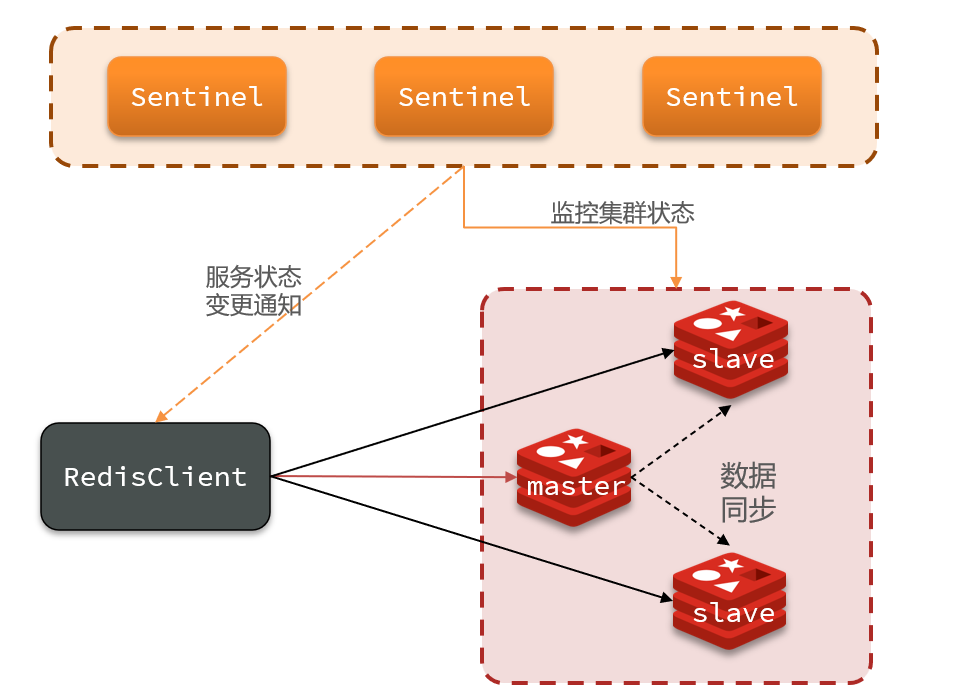
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复
3.1 哨兵的作用
- 监控:Sentinel 会不断检查您的master和slave是否按预期工作
- 自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主
- 通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端
3.2 集群监控原理
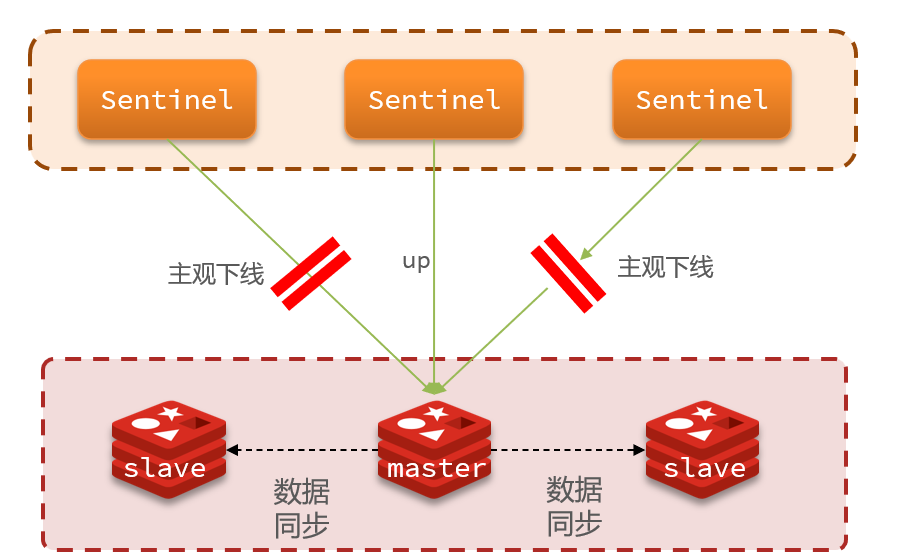
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
- 主观下线:如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
- 客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
3.3 选举新的master
一旦发现master故障,sentinel需要在salve中选择一个作为新的master,选择依据是这样的:
- 首先会判断slave节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds * 10)则会排除该slave节点
- 然后判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举
- 如果slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高
- 最后是判断slave节点的运行id大小,越小优先级越高。
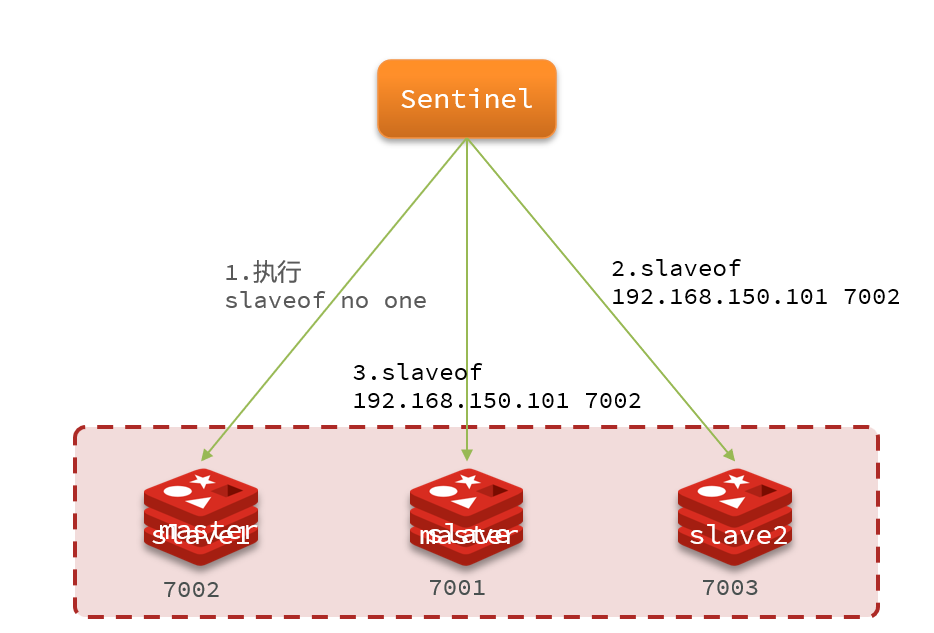
3.4 如何实现故障转移
当选出一个新的master后,该如何实现切换呢?
流程如下:
- sentinel给备选的slave1节点发送slaveof no one命令,让该节点成为master
- 广播:sentinel给所有其它slave发送slaveof 192.168.150.101 7002 命令,让这些slave成为新master的从节点,开始从新的master上同步数据。
- 最后,sentinel将故障节点标记为slave,当故障节点恢复后会自动成为新的master的slave节点
3.5 小结
Sentinel的三个作用是什么?
- 监控
- 故障转移
- 通知
Sentinel如何判断一个redis实例是否健康?
- 每隔1秒发送一次ping命令,如果超过一定时间没有相向则认为是主观下线
- 如果大多数sentinel都认为实例主观下线,则判定服务下线
故障转移步骤有哪些?
- 首先选定一个slave作为新的master,执行slaveof no one
- 然后让所有节点都执行slaveof 新master
- 修改故障节点配置,添加slaveof 新master
3.6 RedisTemplate
在Sentinel集群监管下的Redis主从集群,其节点会因为自动故障转移而发生变化,Redis的客户端必须感知这种变化,及时更新连接信息。Spring的RedisTemplate底层利用lettuce实现了节点的感知和自动切换。
- 引入依赖
在项目的pom文件中引入依赖:
1 | |
- 配置Redis地址
然后在配置文件application.yml中指定redis的sentinel相关信息:
1 | |
- 配置读写分离
在项目的启动类中,添加一个新的bean:
1 | |
这个bean中配置的就是读写策略,包括四种:
- MASTER:从主节点读取
- MASTER_PREFERRED:优先从master节点读取,master不可用才读取replica
- REPLICA:从slave(replica)节点读取
- REPLICA _PREFERRED:优先从slave(replica)节点读取,所有的slave都不可用才读取master
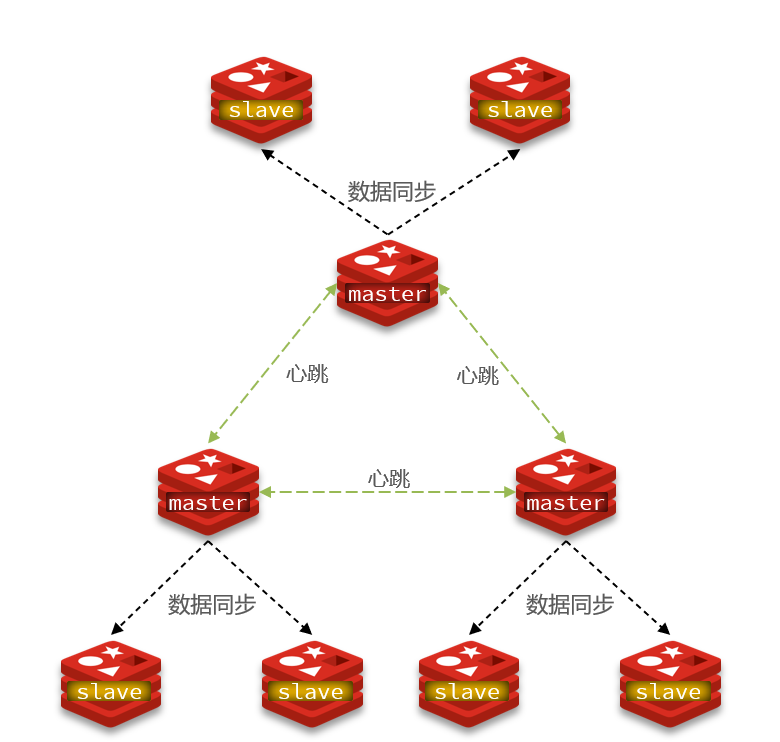
4. Redis分片集群
4.1 分片集群
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
- 海量数据存储问题
- 高并发写的问题
使用分片集群可以解决上述问题,分片集群特征:
- 集群中有多个master,每个master保存不同数据
- 每个master都可以有多个slave节点
- master之间通过ping监测彼此健康状态
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点
4.2 散列插槽
Redis会把每一个master节点映射到0~16383共16384个插槽(hash slot)上

数据key不是与节点绑定,而是与插槽绑定。redis会根据key的有效部分计算插槽值,分两种情况:
- key中包含”{}”,且“{}”中至少包含1个字符,“{}”中的部分是有效部分
- key中不包含“{}”,整个key都是有效部分
例如:key是num,那么就根据num计算,如果是{itcast}num,则根据itcast计算。计算方式是利用CRC16算法得到一个hash值,然后对16384取余,得到的结果就是slot值。
Redis如何判断某个key应该在哪个实例?
- 将16384个插槽分配到不同的实例
- 根据key的有效部分计算哈希值,对16384取余
- 余数作为插槽,寻找插槽所在实例即可
如何将同一类数据固定的保存在同一个Redis实例?
- 这一类数据使用相同的有效部分,例如key都以{typeId}为前缀
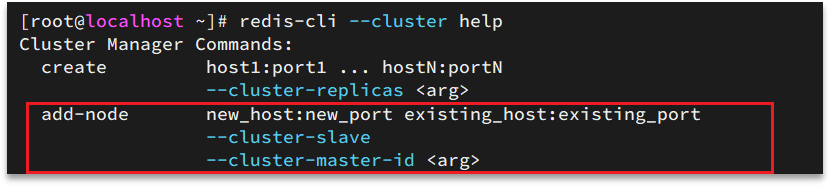
4.3 集群伸缩
redis-cli –cluster提供了很多操作集群的命令
- 添加节点的命令:
4.4 故障转移
4.4.1 自动故障转移
当集群中有一个master宕机会发生什么呢?
直接停止一个redis实例,例如7002:
- 首先是该实例与其它实例失去连接
- 然后是疑似宕机:
- 最后是确定下线,自动提升一个slave为新的master
- 当7002再次启动,就会变为一个slave节点了
4.4.2 手动故障转移
利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点,实现无感知的数据迁移。
4.5 RedisTemplate访问分片集群
RedisTemplate底层同样基于lettuce实现了分片集群的支持,而使用的步骤与哨兵模式基本一致:
- 引入redis的starter依赖
- 配置分片集群地址
- 配置读写分离
与哨兵模式相比,其中只有分片集群的配置方式略有差异,如下:
1 | |
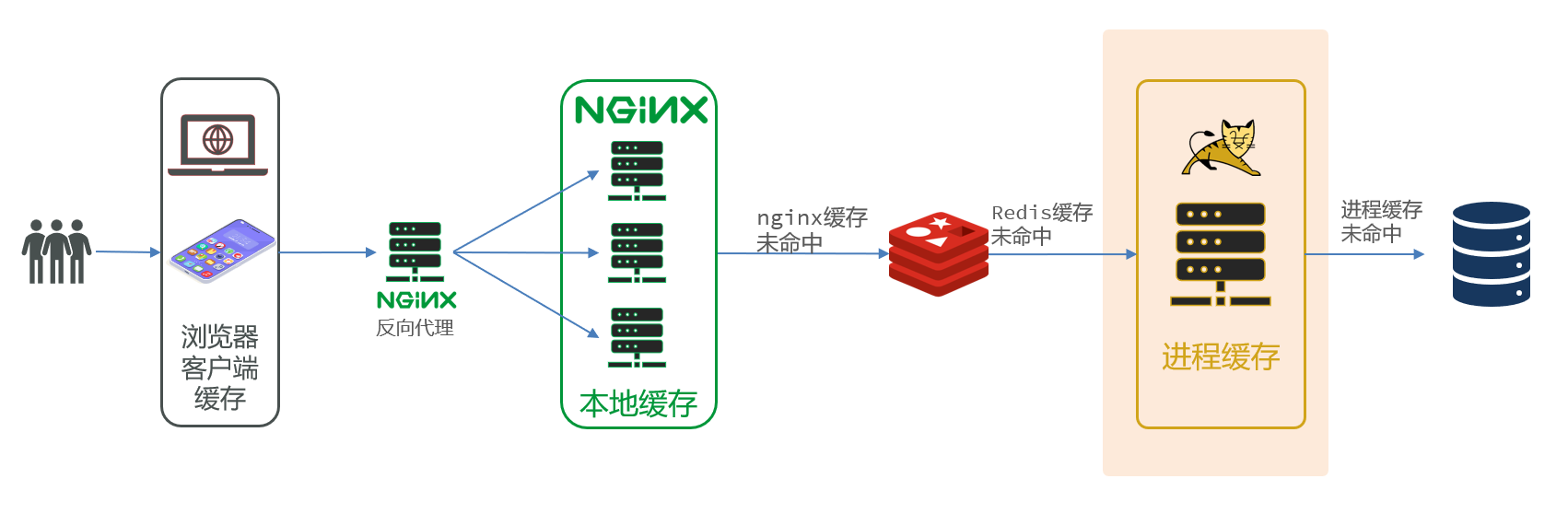
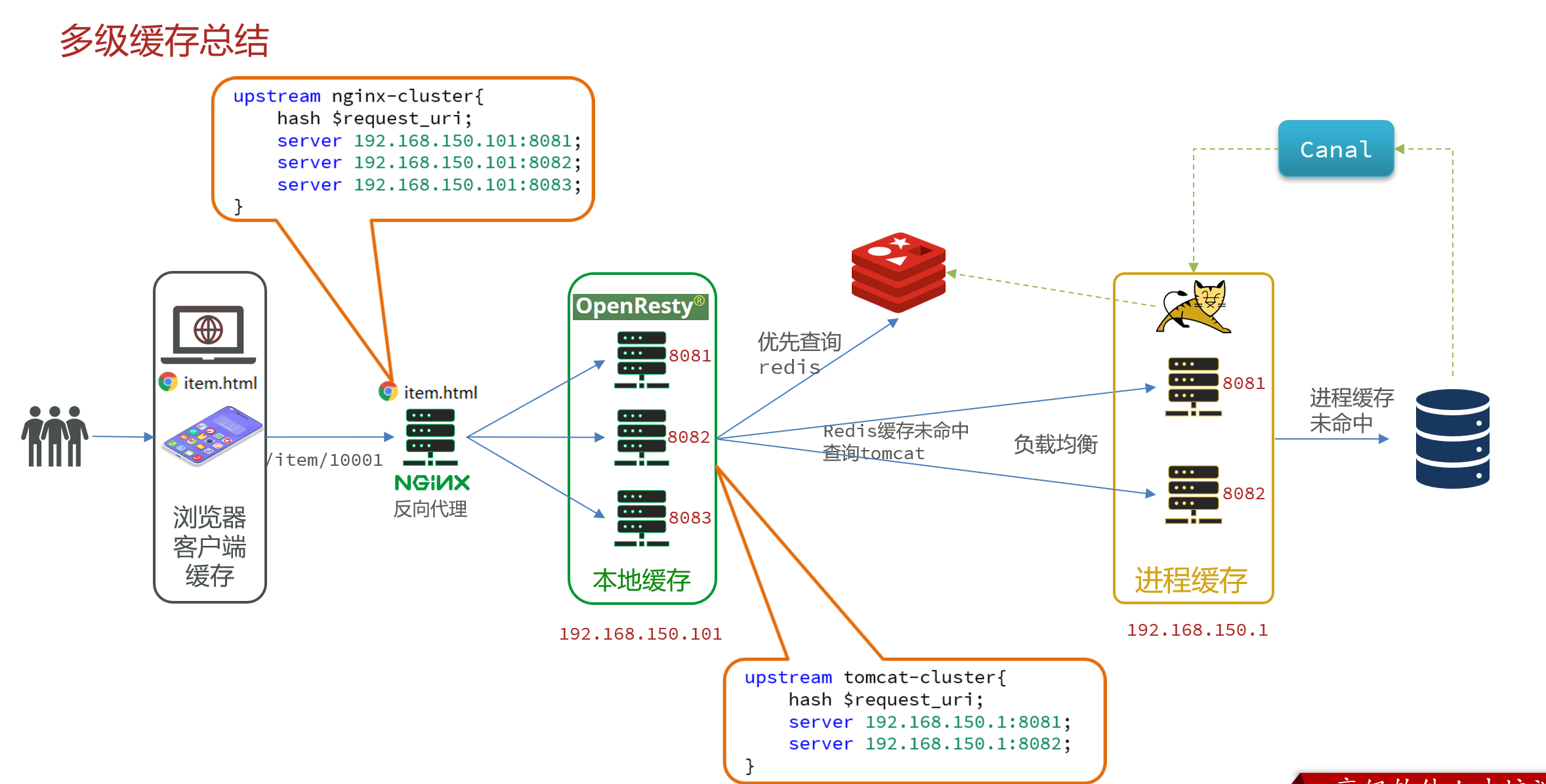
5. 多级缓存
5.1 什么是多级缓存
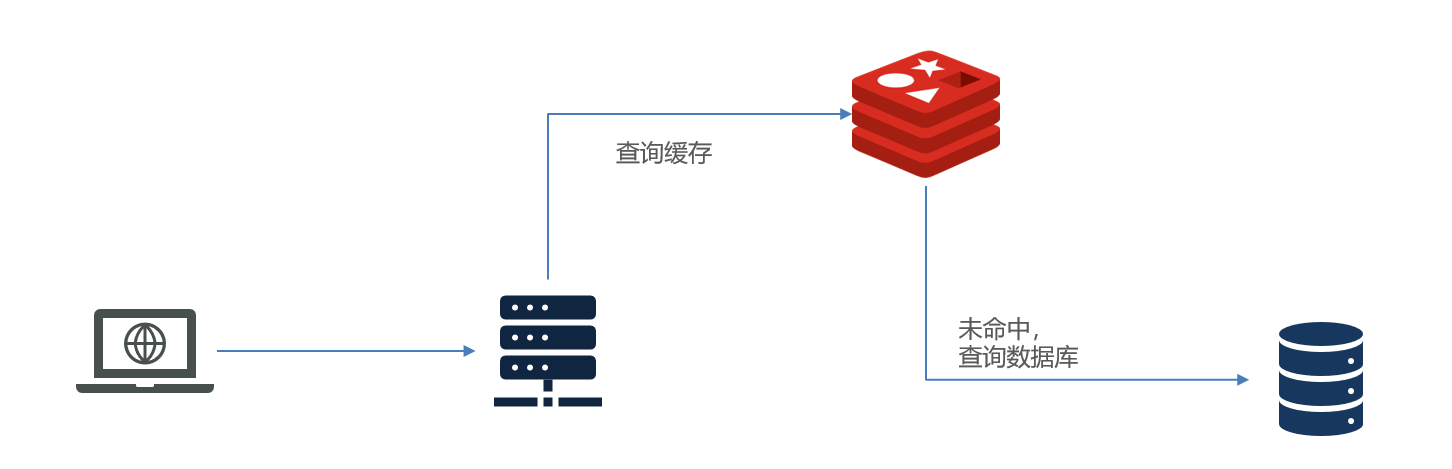
传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库
- 请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈
- Redis缓存失效时,会对数据库产生冲击
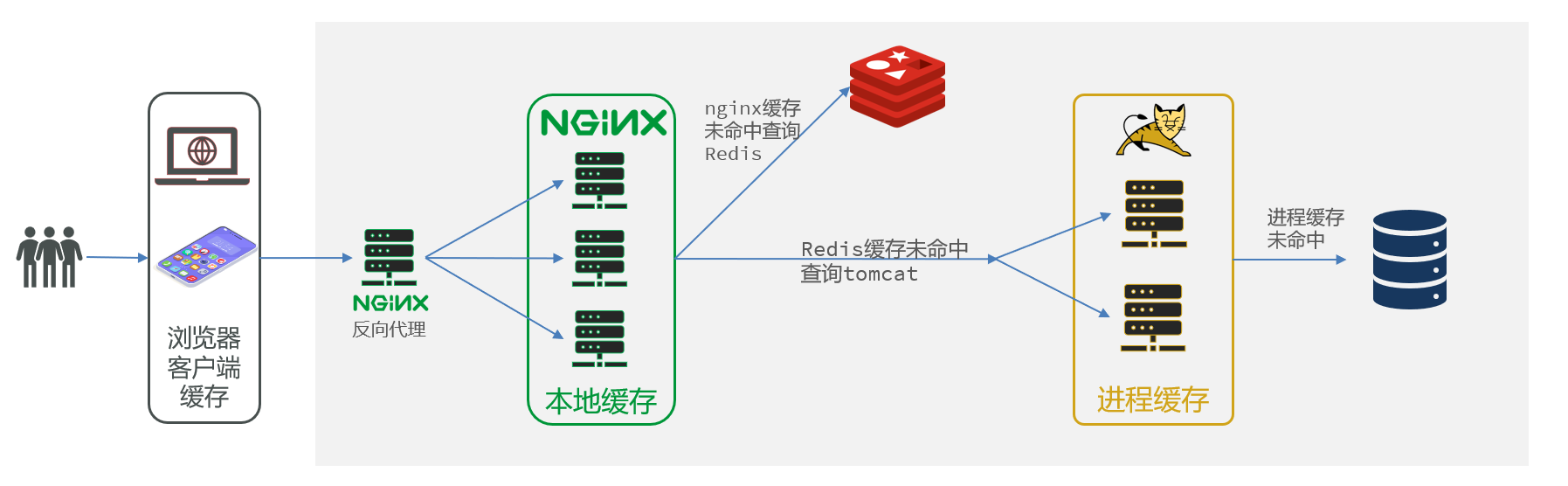
多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能:
- 浏览器访问静态资源时,优先读取浏览器本地缓存
- 访问非静态资源(ajax查询数据)时,访问服务端
- 请求到达Nginx后,优先读取Nginx本地缓存
- 如果Nginx本地缓存未命中,则去直接查询Redis(不经过Tomcat)
- 如果Redis查询未命中,则查询Tomcat
- 请求进入Tomcat后,优先查询JVM进程缓存
- 如果JVM进程缓存未命中,则查询数据库
多级缓存的关键有两个:
- 一个是在nginx中编写业务,实现nginx本地缓存、Redis、Tomcat的查询
- 另一个就是在Tomcat中实现JVM进程缓存
5.2 JVM进程缓存
5.2.1 初识Caffeine
缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类:
- 分布式缓存,例如Redis:
- 优点:存储容量更大、可靠性更好、可以在集群间共享
- 缺点:访问缓存有网络开销
- 场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
- 进程本地缓存,例如HashMap、GuavaCache:
- 优点:读取本地内存,没有网络开销,速度更快
- 缺点:存储容量有限、可靠性较低、无法共享
- 场景:性能要求较高,缓存数据量较小
我们今天会利用Caffeine框架来实现JVM进程缓存
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine。
- 缓存使用的基本API:
1 | |
Caffeine既然是缓存的一种,肯定需要有缓存的清除策略,不然的话内存总会有耗尽的时候。Caffeine提供了三种缓存驱逐策略:
基于容量:设置缓存的数量上限
1
2
3
4// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1) // 设置缓存大小上限为 1
.build();基于时间:设置缓存的有效时间
1
2
3
4
5
6// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
// 设置缓存有效期为 10 秒,从最后一次写入开始计时
.expireAfterWrite(Duration.ofSeconds(10))
.build();基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。
注意:在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
5.2.2 实现JVM进程缓存
利用Caffeine实现下列需求:
- 给根据id查询商品的业务添加缓存,缓存未命中时查询数据库
- 给根据id查询商品库存的业务添加缓存,缓存未命中时查询数据库
- 缓存初始大小为100
- 缓存上限为10000
定义两个Caffeine的缓存对象,分别保存商品、库存的缓存数据。
在item-service的com.heima.item.config包下定义CaffeineConfig类:
1 | |
ItemController
修改item-service中的com.heima.item.web包下的ItemController类,添加缓存逻辑:
1 | |
5.3 Lua语法入门
Nginx编程需要用到Lua语言
5.3.1 初识Lua
Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
5.3.2 变量和循环
Lua的数据类型
| 数据类型 | 描述 |
|---|---|
| nil | 这个最简单,只有值nil属于该类,表示一个无效值(在条件表达式中相当于false)。 |
| boolean | 包含两个值:false和true |
| number | 表示双精度类型的实浮点数 |
| string | 字符串由一对双引号或单引号来表示 |
| function | 由 C 或 Lua 编写的函数 |
| table | Lua 中的表(table)其实是一个”关联数组”(associative arrays),数组的索引可以是数字、字符串或表类型。在 Lua 里,table 的创建是通过”构造表达式”来完成,最简单构造表达式是{},用来创建一个空表。 |
- Lua提供了type()函数来判断一个变量的数据类型
变量
Lua声明变量的时候无需指定数据类型,而是用local来声明变量为局部变量:
1 | |
Lua中的table类型既可以作为数组,又可以作为Java中的map来使用。数组就是特殊的table,key是数组角标而已:
1 | |
Lua中的数组角标是从1开始,访问的时候与Java中类似:
1 | |
Lua中的table可以用key来访问:
1 | |
5.3.3 循环
对于table,我们可以利用for循环来遍历。不过数组和普通table遍历略有差异。
遍历数组:
1 | |
遍历普通table
1 | |
5.3.4 函数
定义函数的语法:
1 | |
例如,定义一个函数,用来打印数组:
1 | |
5.3.5 条件控制
类似Java的条件控制,例如if、else语法:
1 | |
5.3.6 案例
需求:自定义一个函数,可以打印table,当参数为nil时,打印错误信息
1 | |
6. 实现多级缓存
6.1 OpenResty
多级缓存的实现离不开Nginx编程,而Nginx编程又离不开OpenResty
OpenResty® 是一个基于 Nginx的高性能 Web 平台,用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。具备下列特点:
- 具备Nginx的完整功能
- 基于Lua语言进行扩展,集成了大量精良的 Lua 库、第三方模块
- 允许使用Lua自定义业务逻辑、自定义库
6.2 OpenResty快速入门
OpenResty监听请求
OpenResty的很多功能都依赖于其目录下的Lua库,需要在nginx.conf中指定依赖库的目录,并导入依赖:
- 添加对OpenResty的Lua模块的加载
修改/usr/local/openresty/nginx/conf/nginx.conf文件,在其中的http下面,添加下面代码:
1 | |
- 监听/api/item路径
修改/usr/local/openresty/nginx/conf/nginx.conf文件,在nginx.conf的server下面,添加对/api/item这个路径的监听:
1 | |
这个监听,就类似于SpringMVC中的@GetMapping("/api/item")做路径映射。
而content_by_lua_file lua/item.lua则相当于调用item.lua这个文件,执行其中的业务,把结果返回给用户。相当于java中调用service。
- 编写item.lua,返回假数据
item.lua中,利用ngx.say()函数返回数据到Response中
1 | |
6.3 请求参数处理
要返回真实数据,必须根据前端传递来的商品id,查询商品信息才可以。那么如何获取前端传递的商品参数呢?
- OpenResty中提供了一些API用来获取不同类型的前端请求参数:
| 参数格式 | 参数示例 | 参数解析代码示例 |
|---|---|---|
| 路径占位符 | /item/1001 |
–1.正则表达式匹配: location ~ /item/(\d+) { content_by_lua_file lua/item.lua; } – 2. 匹配到的参数会存入ngx.var数组中, – 可以用角标获取 local id = ngx.var[1] |
| 请求头 | id: 1001 |
– 获取请求头,返回值是table类型 local headers = ngx.req.get_headers() |
| Get请求参数 | ?id=1001 |
– 获取GET请求参数,返回值是table类型 local getParams = ngx.req.get_url_args() |
| Post表单参数 | id=1001 |
– 读取请求体 ngx.req.read_body() – 获取POST表单参数,返回值是table类型 local postParams = ngx.req.get_post_args() |
| JSON参数 | {"id": 1001} |
– 读取请求体 ngx.req.read_body() – 获取body中的json参数,返回值是string类型 local jsonBody = ngx.req.get_body_data() |
6.4 查询Tomcat
拿到商品ID后,本应去缓存中查询商品信息,不过目前我们还未建立nginx、redis缓存。因此,这里我们先根据商品id去tomcat查询商品信息
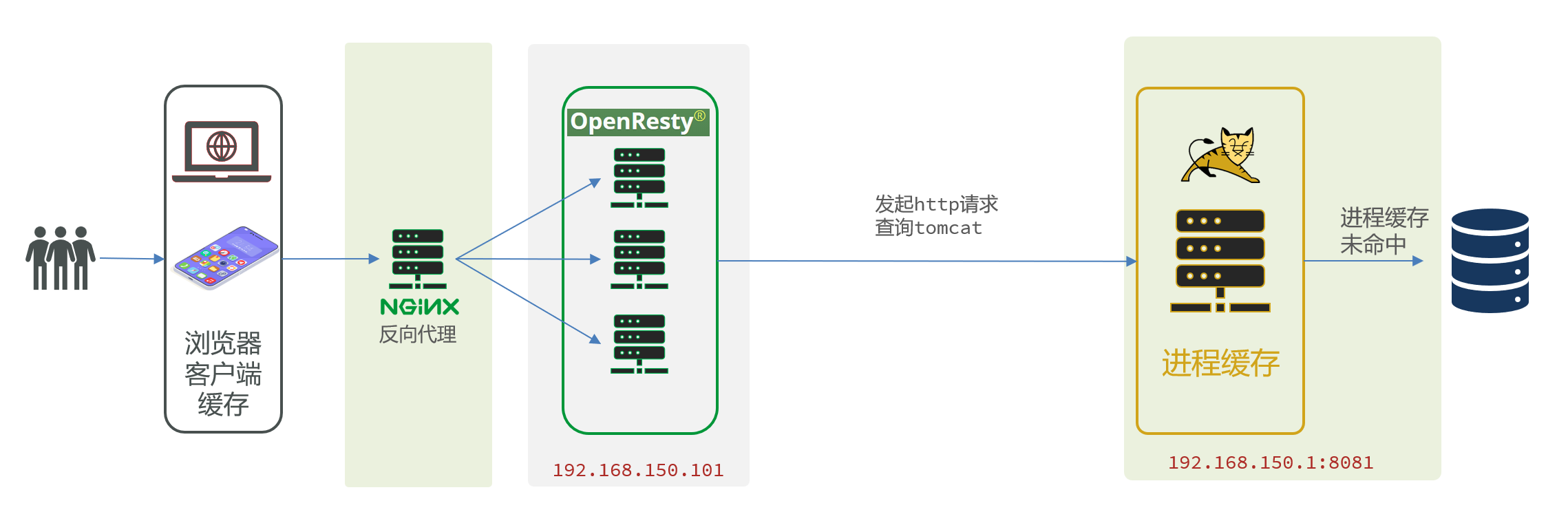
6.4.1 发送http请求的API
nginx提供了内部API用以发送http请求:
1 | |
返回的响应内容包括:
- resp.status:响应状态码
- resp.header:响应头,是一个table
- resp.body:响应体,就是响应数据
6.4.2 封装HTTP查询函数
1 | |
6.4.3 实现商品查询
最后,我们修改/usr/local/openresty/lua/item.lua文件,利用刚刚封装的函数库实现对tomcat的查询:
1 | |
6.4.4 CJSON工具类
OpenResty提供了一个cjson的模块用来处理JSON的序列化和反序列化。
- 引入cjson模块:
1 | |
- 序列化:
1 | |
- 反序列化:
1 | |
6.4.5 实现Tomcat查询
下面,我们修改之前的item.lua中的业务,添加json处理功能:
1 | |
6.4.6 基于ID负载均衡
我们的tomcat是单机部署。而实际开发中,tomcat一定是集群模式
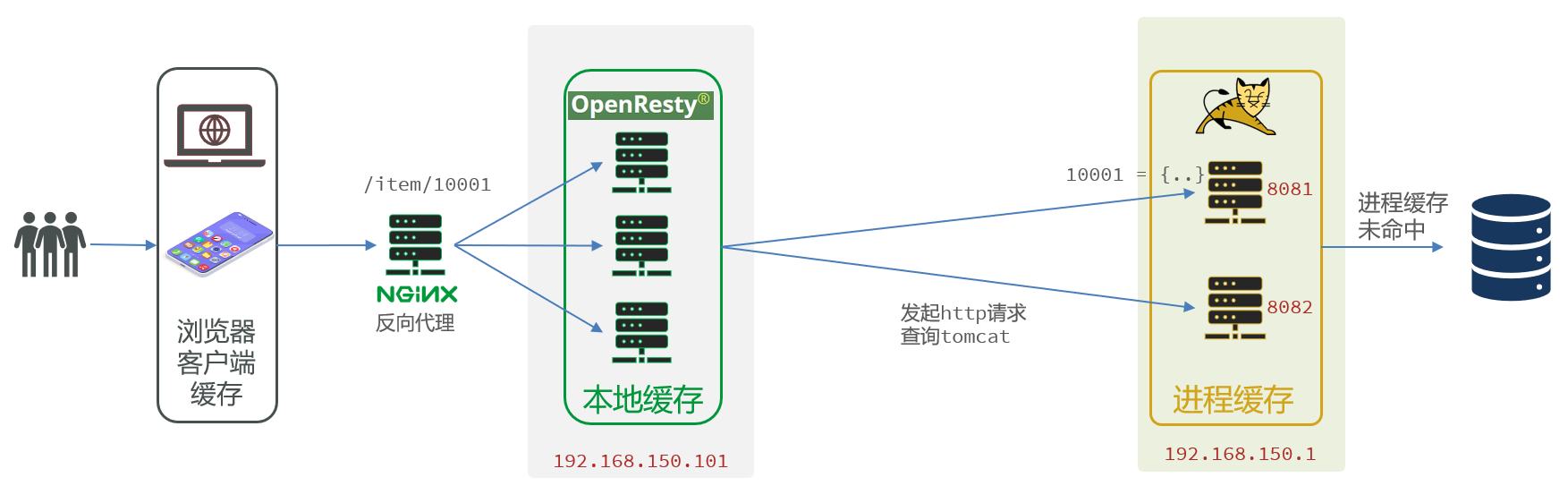
OpenResty需要对tomcat集群做负载均衡。
而默认的负载均衡规则是轮询模式,当我们查询/item/10001时:
- 第一次会访问8081端口的tomcat服务,在该服务内部就形成了JVM进程缓存
- 第二次会访问8082端口的tomcat服务,该服务内部没有JVM缓存(因为JVM缓存无法共享),会查询数据库
解决方案
修改/usr/local/openresty/nginx/conf/nginx.conf文件,实现基于ID做负载均衡。
首先,定义tomcat集群,并设置基于路径做负载均衡:
1 | |
然后,修改对tomcat服务的反向代理,目标指向tomcat集群:
1 | |
6.5 Redis缓存预热
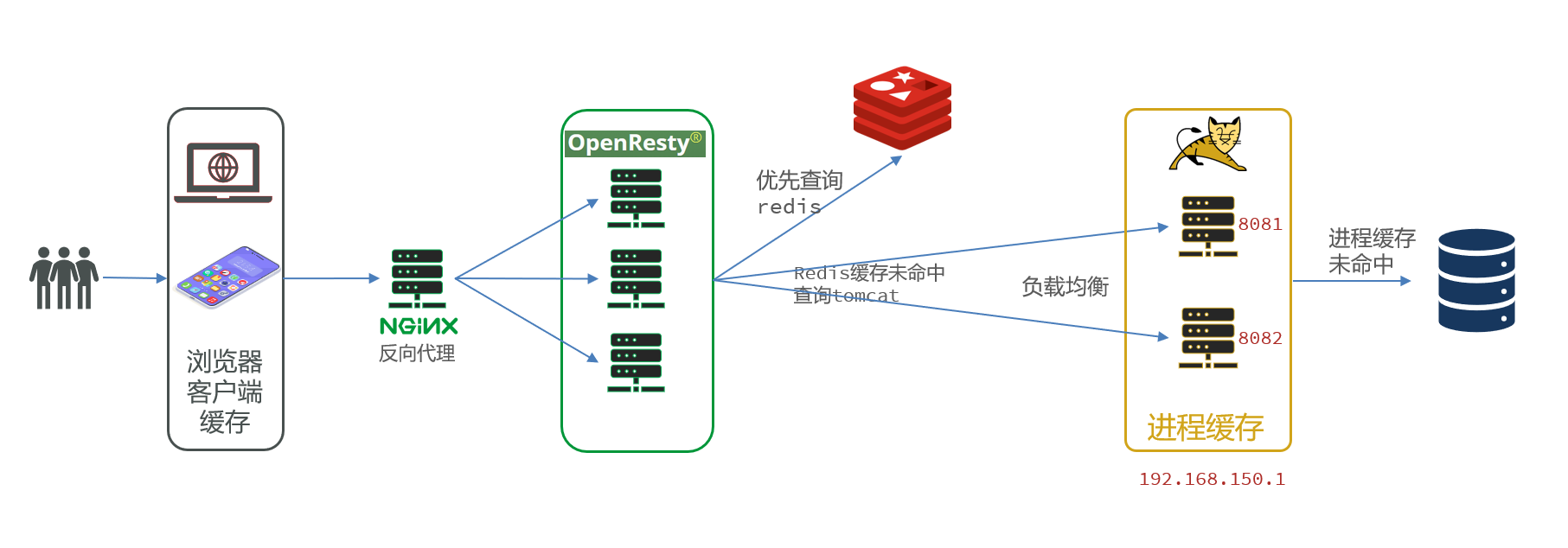
Redis缓存会面临冷启动问题:
- 冷启动:服务刚刚启动时,Redis中并没有缓存,如果所有商品数据都在第一次查询时添加缓存,可能会给数据库带来较大压力。
- 缓存预热:在实际开发中,我们可以利用大数据统计用户访问的热点数据,在项目启动时将这些热点数据提前查询并保存到Redis中。
- 我们数据量较少,并且没有数据统计相关功能,目前可以在启动时将所有数据都放入缓存中。
缓存预热需要在项目启动时完成,并且必须是拿到RedisTemplate之后。
这里我们利用InitializingBean接口来实现,因为InitializingBean可以在对象被Spring创建并且成员变量全部注入后执行。
1 | |
6.6 查询Redis缓存
当请求进入OpenResty之后:
- 优先查询Redis缓存
- 如果Redis缓存未命中,再查询Tomcat
修改item.lua文件,实现对Redis的查询,查询逻辑是:
- 根据id查询Redis
- 如果查询失败则继续查询Tomcat
- 将查询结果返回
1 | |
6.7 Nginx本地缓存
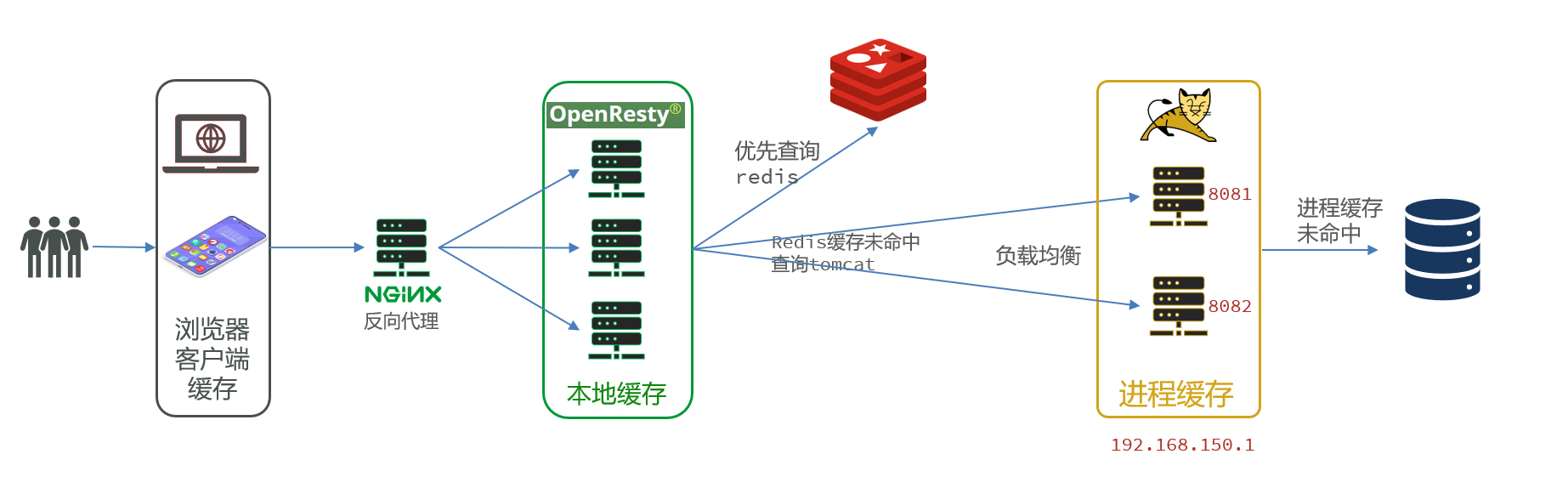
OpenResty为Nginx提供了shard dict的功能,可以在nginx的多个worker之间共享数据,实现缓存功能。
- 开启共享字典,在nginx.conf的http下添加配置:
1 | |
- 操作共享字典:
1 | |
实现本地缓存查询
1 | |
7. 缓存同步
我们必须保证数据库数据、缓存数据的一致性,这就是缓存与数据库的同步
7.1 数据同步策略
缓存数据同步的常见方式有三种:
设置有效期:给缓存设置有效期,到期后自动删除。再次查询时更新
- 优势:简单、方便
- 缺点:时效性差,缓存过期之前可能不一致
- 场景:更新频率较低,时效性要求低的业务
同步双写:在修改数据库的同时,直接修改缓存
- 优势:时效性强,缓存与数据库强一致
- 缺点:有代码侵入,耦合度高;
- 场景:对一致性、时效性要求较高的缓存数据
**异步通知:**修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
- 优势:低耦合,可以同时通知多个缓存服务
- 缺点:时效性一般,可能存在中间不一致状态
- 场景:时效性要求一般,有多个服务需要同步
异步实现:基于Canal的通知:
- 商品服务完成商品修改后,业务直接结束,没有任何代码侵入
- Canal监听MySQL变化,当发现变化后,立即通知缓存服务
- 缓存服务接收到canal通知,更新缓存
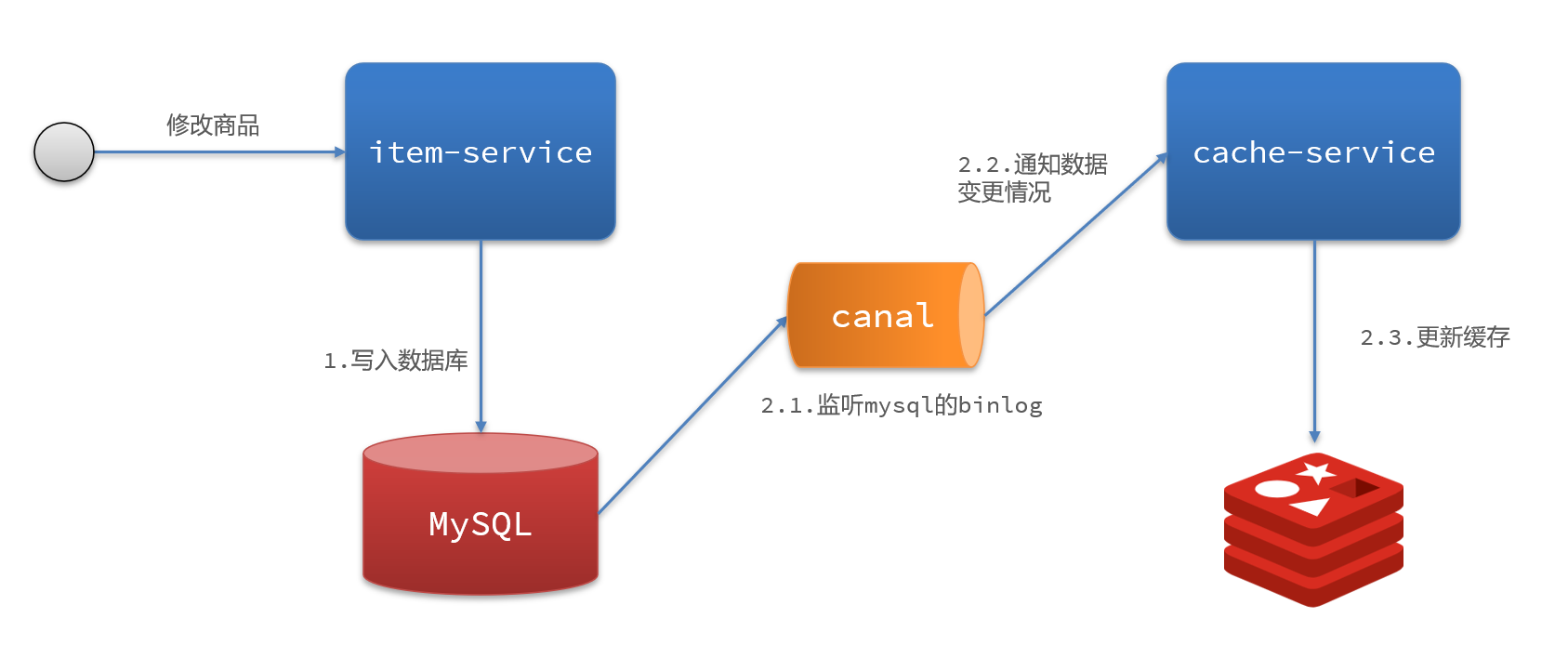
7.2 Canal
Canal,译意为水道/管道/沟渠,canal是阿里巴巴旗下的一款开源项目,基于Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。
Canal是基于mysql的主从同步来实现的,MySQL主从同步的原理如下:
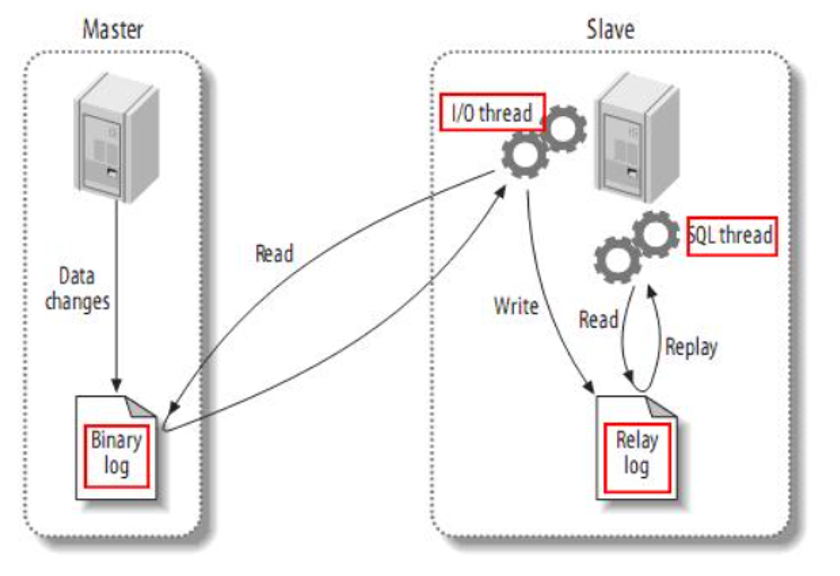
而Canal就是把自己伪装成MySQL的一个slave节点,从而监听master的binary log变化。再把得到的变化信息通知给Canal的客户端,进而完成对其它数据库的同步。
7.3 监听Canal
Canal提供了各种语言的客户端,当Canal监听到binlog变化时,会通知Canal的客户端。
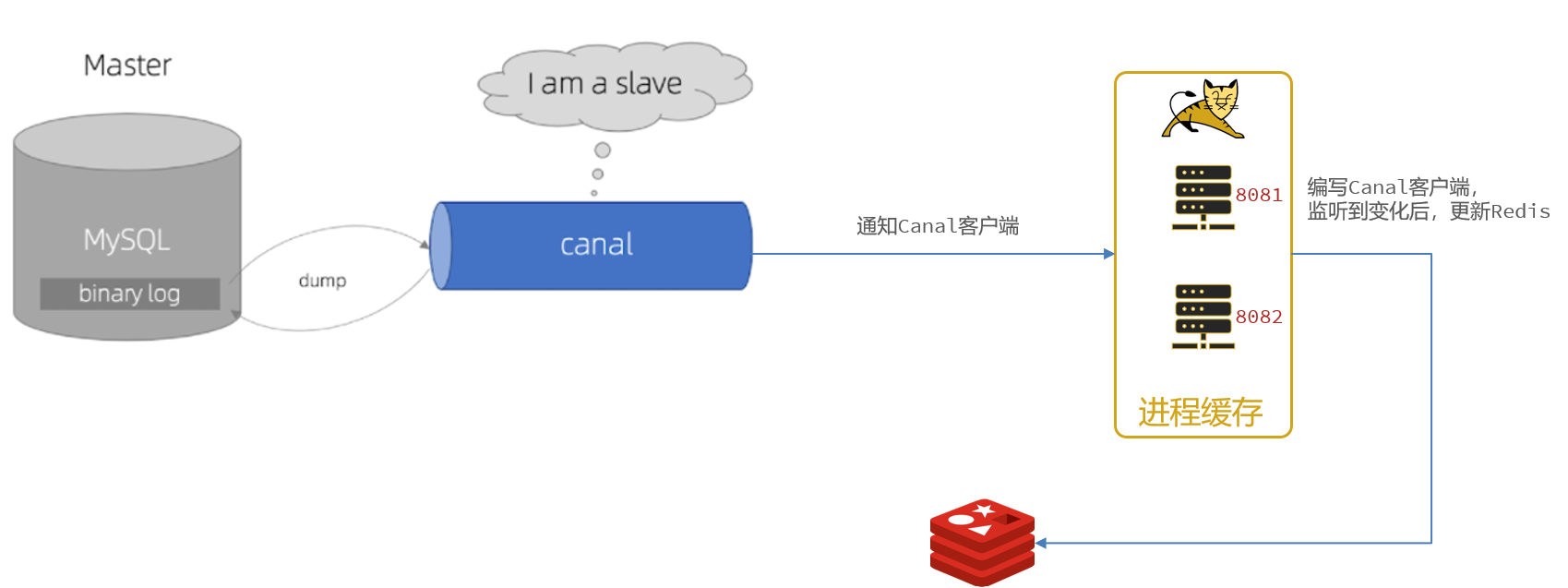
我们可以利用Canal提供的Java客户端,监听Canal通知消息。当收到变化的消息时,完成对缓存的更新。
编写监听器
通过实现EntryHandler<T>接口编写监听器,监听Canal消息。注意两点:
- 实现类通过
@CanalTable("tb_item")指定监听的表信息 - EntryHandler的泛型是与表对应的实体类
1 | |
8. 多级缓存总结
9. Redis最佳实践
9.1 Redis键值设计
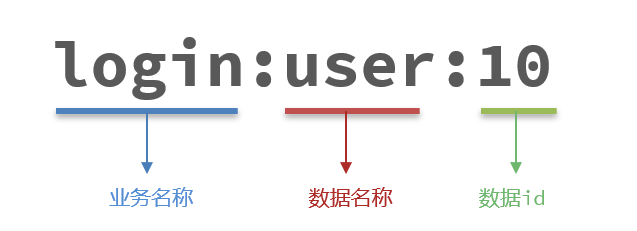
9.1.1 优雅的key结构
Redis的Key虽然可以自定义,但最好遵循下面的几个最佳实践约定:
- 遵循基本格式:
[业务名称]:[数据名]:[id] - 长度不超过44字节
- 不包含特殊字符
这样设计的好处:
- 可读性强
- 避免key冲突
- 方便管理
- 更节省内存
9.1.2 拒绝BigKey
9.1.2.1 BigKey
BigKey通常以Key的大小和Key中成员的数量来综合判定,例如:
- Key本身的数据量过大:一个String类型的Key,它的值为5 MB
- Key中的成员数过多:一个ZSET类型的Key,它的成员数量为10,000个
- Key中成员的数据量过大:一个Hash类型的Key,它的成员数量虽然只有1,000个但这些成员的Value(值)总大小为100 MB
推荐值:
- 单个key的value小于10KB
- 对于集合类型的key,建议元素数量小于1000
9.1.2.2 BigKey的危害
- 网络阻塞
- 对BigKey执行读请求时,少量的QPS就可能导致带宽使用率被占满,导致Redis实例,乃至所在物理机变慢
- 数据倾斜
- BigKey所在的Redis实例内存使用率远超其他实例,无法使数据分片的内存资源达到均衡
- Redis阻塞
- 对元素较多的hash、list、zset等做运算会耗时较旧,使主线程被阻塞
- CPU压力
- 对BigKey的数据序列化和反序列化会导致CPU的使用率飙升,影响Redis实例和本机其它应用
9.1.2.3 如何发现BigKey
- redis-cli –bigkeys
- 利用redis-cli提供的–bigkeys参数,可以遍历分析所有key,并返回Key的整体统计信息与每个数据的Top1的big key
- scan扫描
- 自己编程,利用scan扫描Redis中的所有key,利用strlen、hlen等命令判断key的长度(此处不建议使用MEMORY USAGE)
- 第三方工具
- 利用第三方工具,如 Redis-Rdb-Tools 分析RDB快照文件,全面分析内存使用情况
- 网络监控
- 自定义工具,监控进出Redis的网络数据,超出预警值时主动告警
9.1.2.4 如何删除BigKey
BigKey内存占用较多,即便时删除这样的key也需要耗费很长时间,导致Redis主线程阻塞,引发一系列问题。
- redis 3.0 及以下版本
- 如果是集合类型,则遍历BigKey的元素,先逐个删除子元素,最后删除BigKey
- Redis 4.0以后
- Redis在4.0后提供了异步删除的命令:unlink
9.1.3 恰当的数据类型
例1:比如存储一个User对象,我们有三种存储方式:
- 方式一:json字符串
- 方式二:字段打散
- 方式三:hash(推荐)

例2:假如有hash类型的key,其中有100万对field和value,field是自增id,这个key存在什么问题?如何优化?
存在的问题:
- hash的entry数量超过500时,会使用哈希表而不是ZipList,内存占用较多
- 可以通过hash-max-ziplist-entries配置entry上限。但是如果entry过多就会导致BigKey问题
- 方案一: 拆分为string类型
- 方案二: 拆分为小的hash,将 id / 100 作为key, 将id % 100 作为field,这样每100个元素为一个Hash(推荐)
9.1.4 总结
- Key的最佳实践
- 固定格式:
[业务名]:[数据名]:[id] - 足够简短:不超过44字节
- 不包含特殊字符
- 固定格式:
- Value的最佳实践:
- 合理的拆分数据,拒绝BigKey
- 选择合适数据结构
- Hash结构的entry数量不要超过1000
- 设置合理的超时时间
9.2 批处理优化
9.2.1 Pipeline
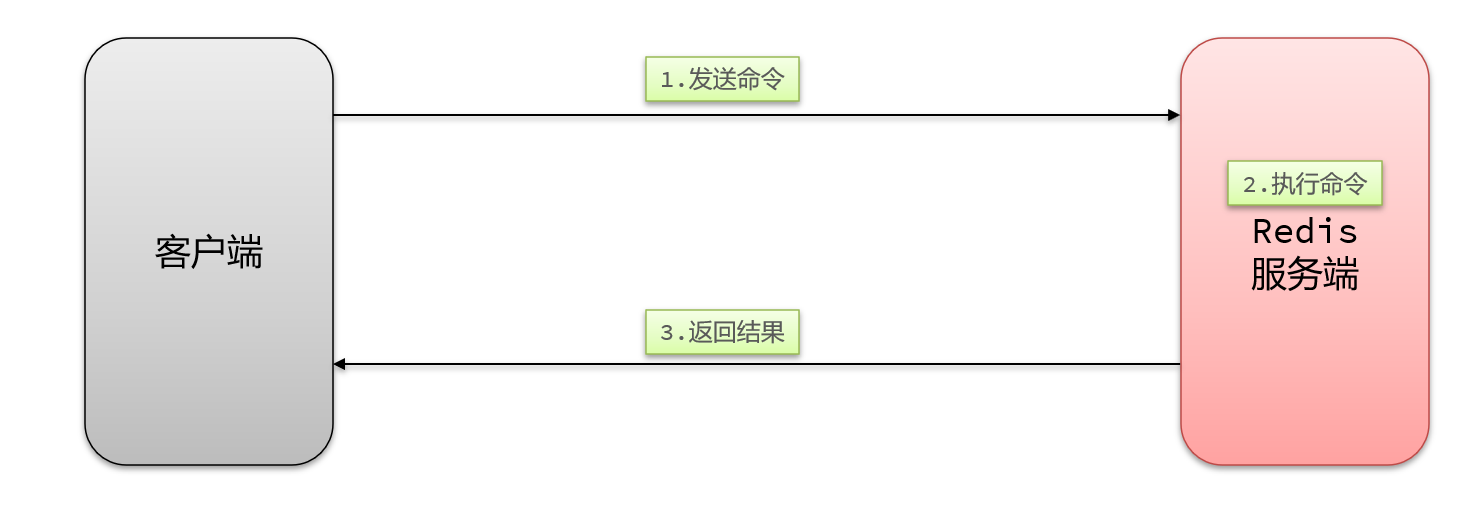
9.2.1.1 客户端与redis服务器是这样交互的
- 单个命令的执行流程
一次命令的响应时间 = 1次往返的网络传输耗时 + 1次Redis执行命令耗时
- N条命令依次执行
N次命令的响应时间 = N次往返的网络传输耗时 + N次Redis执行命令耗时
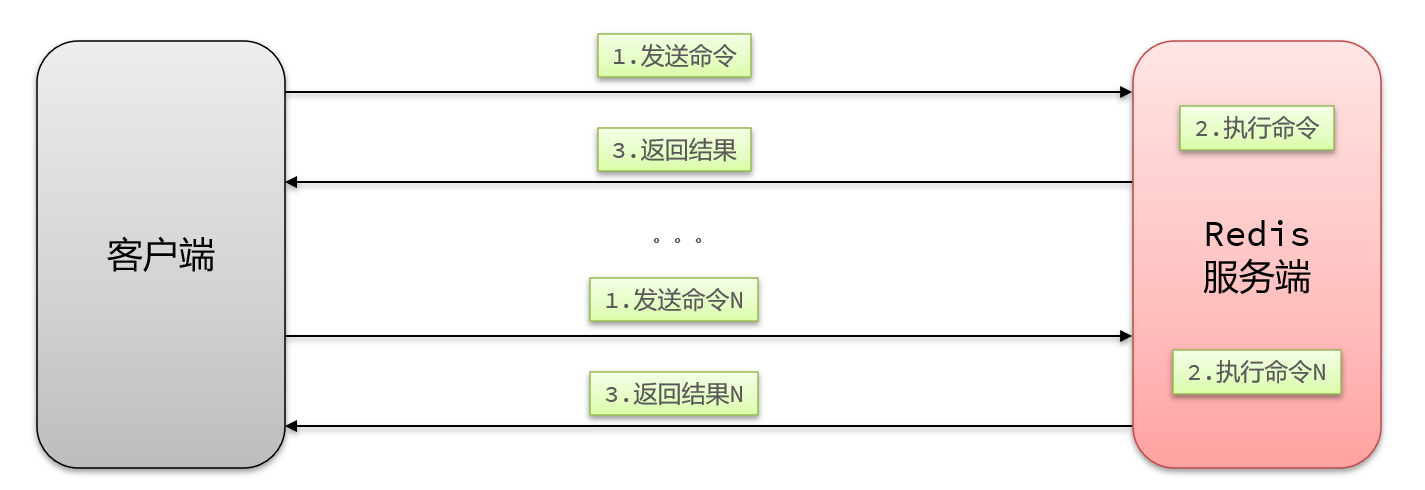
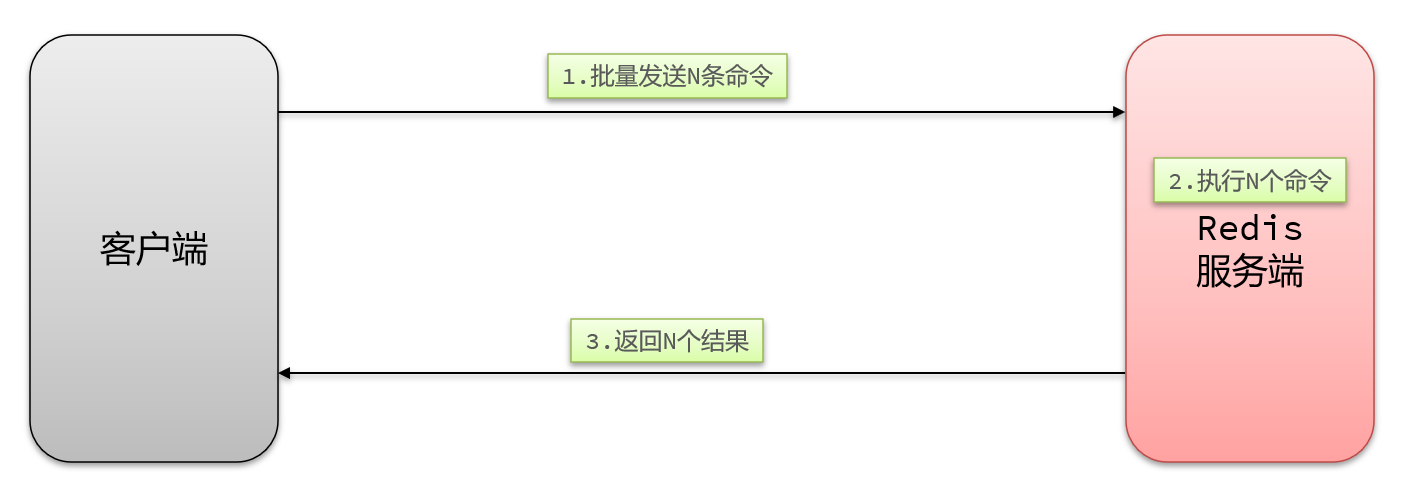
- N条命令批量执行
N次命令的响应时间 = 1次往返的网络传输耗时 + N次Redis执行命令耗时
9.2.1.2 MSet
Redis提供了很多Mxxx这样的命令,可以实现批量插入数据,例如:
- mset
- hmset
利用mset批量插入10万条数据
1 | |
9.2.1.3 Pipeline
MSET虽然可以批处理,但是却只能操作部分数据类型,因此如果有对复杂数据类型的批处理需要,建议使用Pipeline
1 | |
9.2.2 集群下的批处理
如MSET或Pipeline这样的批处理需要在一次请求中携带多条命令,而此时如果Redis是一个集群,那批处理命令的多个key必须落在一个插槽中,否则就会导致执行失败。
| 串行命令 | 串行slot | 并行slot(推荐) | hash_tag | |
|---|---|---|---|---|
| 实现思路 | for循环遍历,依次执行每个命令 | 在客户端计算每个key的slot,将slot一致分为一组,每组都利用Pipeline批处理,串行执行各组命令 | 在客户端计算每个key的slot,将slot一致分为一组,每组都利用Pipeline批处理,并行执行各组命令 | 将所有key设置相同的hash_tag,则所有key的slot一定相同 |
| 耗时 | N次网络耗时 + N次命令耗时 | m次网络耗时 + N次命令耗时 (m = key的slot个数) |
1次网络耗时 + N次命令耗时 | 1次网络耗时 + N次命令耗时 |
| 优点 | 实现简单 | 耗时较短 | 耗时非常短 | 耗时非常短、实现简单 |
| 缺点 | 耗时非常久 | 实现稍复杂 | 实现复杂 | 容易出现数据倾斜 |
- 推荐使用并行slot
9.3 服务端优化
9.3.1 持久化配置
Redis的持久化虽然可以保证数据安全,但也会带来很多额外的开销,因此持久化请遵循下列建议:
- 用来做缓存的Redis实例尽量不要开启持久化功能
- 建议关闭RDB持久化功能,使用AOF持久化
- 利用脚本定期在slave节点做RDB,实现数据备份
- 设置合理的rewrite阈值,避免频繁的bgrewrite
- 配置no-appendfsync-on-rewrite = yes,禁止在rewrite期间做aof,避免因AOF引起的阻塞
- 部署有关建议:
- Redis实例的物理机要预留足够内存,应对fork和rewrite
- 单个Redis实例内存上限不要太大,例如4G或8G。可以加快fork的速度、减少主从同步、数据迁移压力
- 不要与CPU密集型应用部署在一起
- 不要与高硬盘负载应用一起部署。例如:数据库、消息队列
9.3.2 慢查询优化
在Redis执行时耗时超过某个阈值的命令,称为慢查询。
慢查询的危害:由于Redis是单线程的,所以当客户端发出指令后,他们都会进入到redis底层的queue来执行,如果此时有一些慢查询的数据,就会导致大量请求阻塞,从而引起报错,所以我们需要解决慢查询问题。
慢查询的阈值可以通过配置指定:
- slowlog-log-slower-than:慢查询阈值,单位是微秒。默认是10000,建议1000
慢查询会被放入慢查询日志中,日志的长度有上限,可以通过配置指定:
- slowlog-max-len:慢查询日志(本质是一个队列)的长度。默认是128,建议1000
查看慢查询日志列表:
- slowlog len:查询慢查询日志长度
- slowlog get [n]:读取n条慢查询日志
- slowlog reset:清空慢查询列表
9.3.3 命令及安全配置
漏洞出现的核心的原因有以下几点:
- Redis未设置密码
- 利用了Redis的config set命令动态修改Redis配置
- 使用了Root账号权限启动Redis
为了避免这样的漏洞,这里给出一些建议:
- Redis一定要设置密码
- 禁止线上使用下面命令:keys、flushall、flushdb、config set等命令。可以利用rename-command禁用。
- bind:限制网卡,禁止外网网卡访问
- 开启防火墙
- 不要使用Root账户启动Redis
- 尽量不是有默认的端口
9.3.4 内存配置
当Redis内存不足时,可能导致Key频繁被删除、响应时间变长、QPS不稳定等问题。当内存使用率达到90%以上时就需要我们警惕,并快速定位到内存占用的原因。
| 内存类型 | 说明 |
|---|---|
| 数据内存 | 是Redis最主要的部分,存储Redis的键值信息。主要问题是BigKey问题、内存碎片问题 |
| 进程内存 | Redis主进程本身运行肯定需要占用内存,如代码、常量池等;这部分内存大约几兆,在大多数生产环境中与Redis数据占用的内存相比可以忽略 |
| 缓冲区内存 | 一般包括客户端缓冲区、AOF缓冲区、复制缓冲区等。客户端缓冲区又包括输入缓冲区和输出缓冲区两种。这部分内存占用波动较大,不当使用BigKey可能导致内存溢出 |
内存缓冲区常见的有三种:
- 复制缓冲区:主从复制的repl_backlog_buf,如果太小可能导致频繁的全量复制,影响性能。通过replbacklog-size来设置,默认1mb
- AOF缓冲区:AOF刷盘之前的缓存区域,AOF执行rewrite的缓冲区。无法设置容量上限
- 客户端缓冲区:分为输入缓冲区和输出缓冲区,输入缓冲区最大1G且不能设置。输出缓冲区可以设置
9.4 集群最佳实践
9.4.1 问题1、在Redis的默认配置中,如果发现任意一个插槽不可用,则整个集群都会停止对外服务:
- 为了保证高可用特性,这里建议将 cluster-require-full-coverage配置为false
9.4.2 问题2、集群带宽问题
集群节点之间会不断的互相Ping来确定集群中其它节点的状态。每次Ping携带的信息至少包括:
- 插槽信息
- 集群状态信息
集群中节点越多,集群状态信息数据量也越大,10个节点的相关信息可能达到1kb,此时每次集群互通需要的带宽会非常高,这样会导致集群中大量的带宽都会被ping信息所占用,这是一个非常可怕的问题,所以我们需要去解决这样的问题
解决途径:
- 避免大集群,集群节点数不要太多,最好少于1000,如果业务庞大,则建立多个集群。
- 避免在单个物理机中运行太多Redis实例
- 配置合适的cluster-node-timeout值
9.4.3 其他问题
- 数据倾斜问题
- 客户端性能问题
- 命令的集群兼容性问题
- lua和事务问题
那我们到底是集群还是主从
- 单体Redis(主从Redis)已经能达到万级别的QPS,并且也具备很强的高可用特性。如果主从能满足业务需求的情况下,所以如果不是在万不得已的情况下,尽量不搭建Redis集群
四. Redis原理篇
1. Redis数据结构
1.1 动态字符串SDS
我们都知道Redis中保存的Key是字符串,value往往是字符串或者字符串的集合。可见字符串是Redis中最常用的一种数据结构。
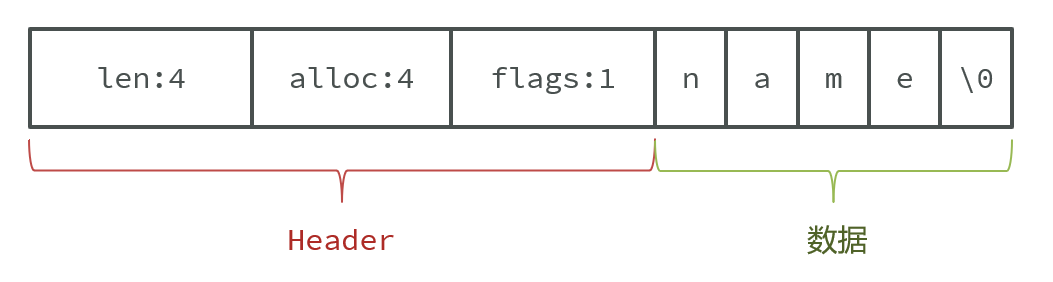
Redis构建了一种新的字符串结构,称为简单动态字符串(Simple Dynamic String),简称SDS。
- 例如:Redis将在底层创建两个SDS,其中一个是包含“name”的SDS,另一个是包含“虎哥”的SDS。

Redis是C语言实现的,其中SDS是一个结构体,源码如下:
1 | |
例如,一个包含字符串“name”的sds结构如下:
- SDS之所以叫做动态字符串,是因为它具备动态扩容的能力,例如一个内容为“hi”的SDS
- 假如我们要给SDS追加一段字符串“,Amy”,这里首先会申请新内存空间
- 如果新字符串小于1M,则新空间为扩展后字符串长度的两倍+1;
- 如果新字符串大于1M,则新空间为扩展后字符串长度+1M+1。称为内存预分配。
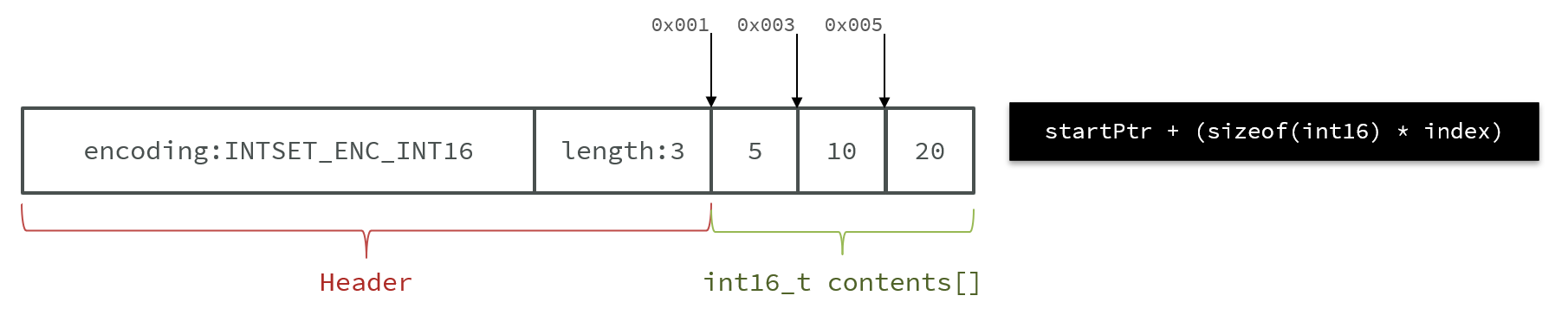
1.2 IntSet
IntSet是Redis中set集合的一种实现方式,基于整数数组来实现,并且具备长度可变、有序等特征。
1 | |
其中的encoding包含三种模式,表示存储的整数大小不同:
1 | |
为了方便查找,Redis会将intset中所有的整数按照升序依次保存在contents数组中,结构如图:
IntSet升级
我们向该其中添加一个数字:50000,这个数字超出了int16_t的范围,intset会自动升级编码方式到合适的大小。
以当前案例来说流程如下:
- 升级编码为INTSET_ENC_INT32, 每个整数占4字节,并按照新的编码方式及元素个数扩容数组
- 倒序依次将数组中的元素拷贝到扩容后的正确位置
- 将待添加的元素放入数组末尾
- 最后,将inset的encoding属性改为INTSET_ENC_INT32,将length属性改为4
原本:

扩容后:

总结:Intset可以看做是特殊的整数数组,具备一些特点:
- Redis会确保Intset中的元素唯一、有序
- 具备类型升级机制,可以节省内存空间
- 底层采用二分查找方式来查询
1.3 Dict
我们知道Redis是一个键值型(Key-Value Pair)的数据库,我们可以根据键实现快速的增删改查。而键与值的映射关系正是通过Dict来实现的。
- Dict由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)
当我们向Dict添加键值对时,Redis首先根据key计算出hash值(h),然后利用 h & sizemask来计算元素应该存储到数组中的哪个索引位置。
- 我们存储k1=v1,假设k1的哈希值h =1,则1&3 =1,因此k1=v1要存储到数组角标1位置。
Dict的扩容
Dict中的HashTable就是数组结合单向链表的实现,当集合中元素较多时,必然导致哈希冲突增多,链表过长,则查询效率会大大降低。
Dict在每次新增键值对时都会检查负载因子(LoadFactor = used/size) ,满足以下两种情况时会触发哈希表扩容:
- 哈希表的 LoadFactor >= 1,并且服务器没有执行 BGSAVE 或者 BGREWRITEAOF 等后台进程;
- 哈希表的 LoadFactor > 5 ;
Dict的收缩
Dict除了扩容以外,每次删除元素时,也会对负载因子做检查,当LoadFactor < 0.1 时,会做哈希表收缩
Dict的rehash
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的size和sizemask变化,而key的查询与sizemask有关。因此必须对哈希表中的每一个key重新计算索引,插入新的哈希表,这个过程称为rehash。过程是这样的:
- 计算新hash表的realeSize,值取决于当前要做的是扩容还是收缩:
- 如果是扩容,则新size为第一个大于等于dict.ht[0].used + 1的2^n
- 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2^n (不得小于4)
- 按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
- 设置dict.rehashidx = 0,标示开始rehash
- 将dict.ht[0]中的每一个dictEntry都rehash到dict.ht[1]
- 将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
- 将rehashidx赋值为-1,代表rehash结束
- 在rehash过程中,新增操作,则直接写入ht[1],查询、修改和删除则会在dict.ht[0]和dict.ht[1]依次查找并执行。这样可以确保ht[0]的数据只减不增,随着rehash最终为空
总结
Dict的结构:
- 类似java的HashTable,底层是数组加链表来解决哈希冲突
- Dict包含两个哈希表,ht[0]平常用,ht[1]用来rehash
Dict的伸缩:
- 当LoadFactor大于5或者LoadFactor大于1并且没有子进程任务时,Dict扩容
- 当LoadFactor小于0.1时,Dict收缩
- 扩容大小为第一个大于等于used + 1的2^n
- 收缩大小为第一个大于等于used 的2^n
- Dict采用渐进式rehash,每次访问Dict时执行一次rehash
- rehash时ht[0]只减不增,新增操作只在ht[1]执行,其它操作在两个哈希表
1.4 ZipList
ZipList 是一种特殊的“双端链表” ,由一系列特殊编码的连续内存块组成。可以在任意一端进行压入/弹出操作, 并且该操作的时间复杂度为 O(1)。
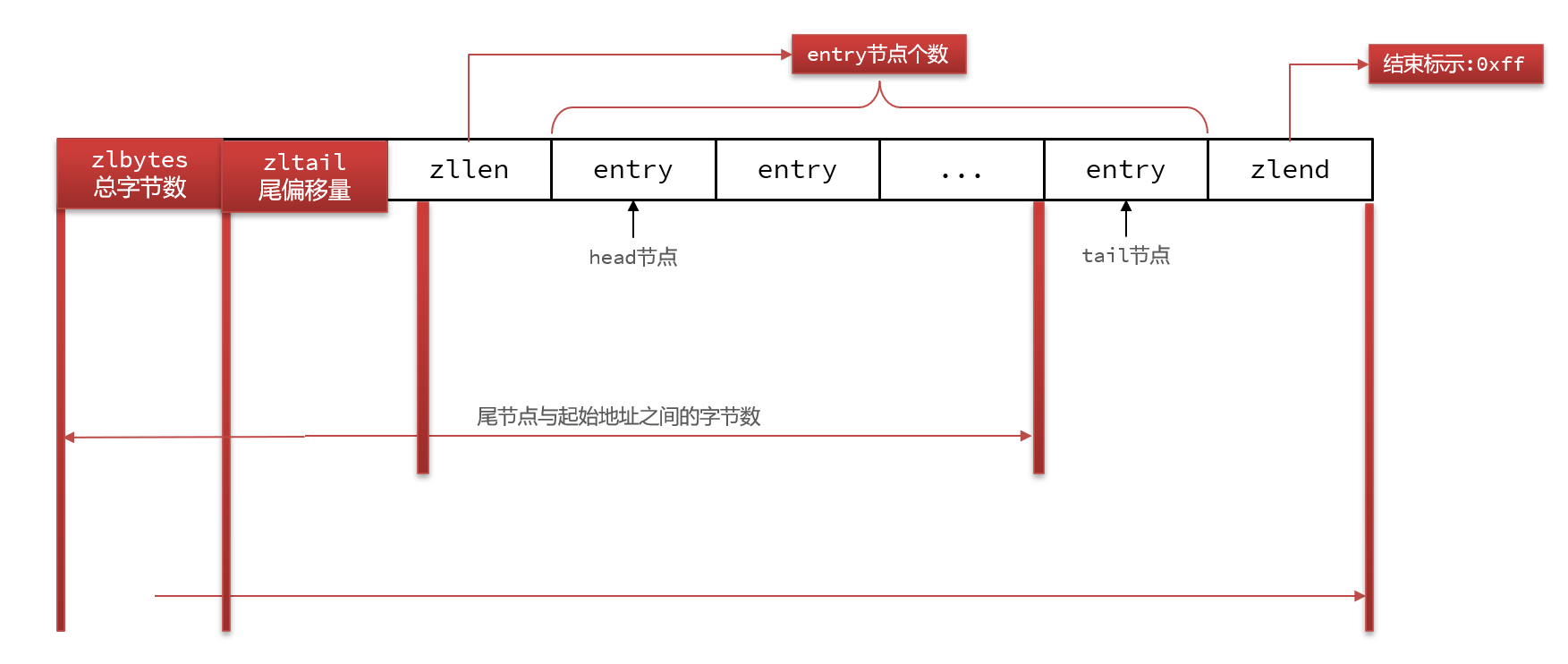
| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4 字节 | 记录整个压缩列表占用的内存字节数 |
| zltail | uint32_t | 4 字节 | 记录压缩列表表尾节点距离压缩列表的起始地址有多少字节,通过这个偏移量,可以确定表尾节点的地址。 |
| zllen | uint16_t | 2 字节 | 记录了压缩列表包含的节点数量。 最大值为UINT16_MAX (65534),如果超过这个值,此处会记录为65535,但节点的真实数量需要遍历整个压缩列表才能计算得出。 |
| entry | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定。 |
| zlend | uint8_t | 1 字节 | 特殊值 0xFF (十进制 255 ),用于标记压缩列表的末端。 |
ZipListEntry
ZipList 中的Entry并不像普通链表那样记录前后节点的指针,因为记录两个指针要占用16个字节,浪费内存。而是采用了下面的结构:

- previous_entry_length:前一节点的长度,占1个或5个字节。
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- 如果前一节点的长度大于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据
- encoding:编码属性,记录content的数据类型(字符串还是整数)以及长度,占用1个、2个或5个字节
- contents:负责保存节点的数据,可以是字符串或整数
ZipList的连锁更新问题
现在,假设我们有N个连续的、长度为250~253字节之间的entry,因此entry的previous_entry_length属性用1个字节即可表示,如图所示:

ZipList这种特殊情况下产生的连续多次空间扩展操作称之为连锁更新(Cascade Update)。新增、删除都可能导致连锁更新的发生。
总结
ZipList特性:
- 压缩列表的可以看做一种连续内存空间的”双向链表”
- 列表的节点之间不是通过指针连接,而是记录上一节点和本节点长度来寻址,内存占用较低
- 如果列表数据过多,导致链表过长,可能影响查询性能
- 增或删较大数据时有可能发生连续更新问题
1.5 QuickList
问题1:ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请内存效率很低。怎么办?
- 答:为了缓解这个问题,我们必须限制ZipList的长度和entry大小。
问题2:但是我们要存储大量数据,超出了ZipList最佳的上限该怎么办?
- 答:我们可以创建多个ZipList来分片存储数据。
问题3:数据拆分后比较分散,不方便管理和查找,这多个ZipList如何建立联系?
- 答:Redis在3.2版本引入了新的数据结构QuickList,它是一个双端链表,只不过链表中的每个节点都是一个ZipList。
为了避免QuickList中的每个ZipList中entry过多,Redis提供了一个配置项:list-max-ziplist-size来限制。
除了控制ZipList的大小,QuickList还可以对节点的ZipList做压缩。通过配置项list-compress-depth来控制
QuickList的特点:
- 是一个节点为ZipList的双端链表
- 节点采用ZipList,解决了传统链表的内存占用问题
- 控制了ZipList大小,解决连续内存空间申请效率问题
- 中间节点可以压缩,进一步节省了内存
1.6 SkipList
SkipList(跳表)首先是链表,但与传统链表相比有几点差异:
- 元素按照升序排列存储
- 节点可能包含多个指针,指针跨度不同。
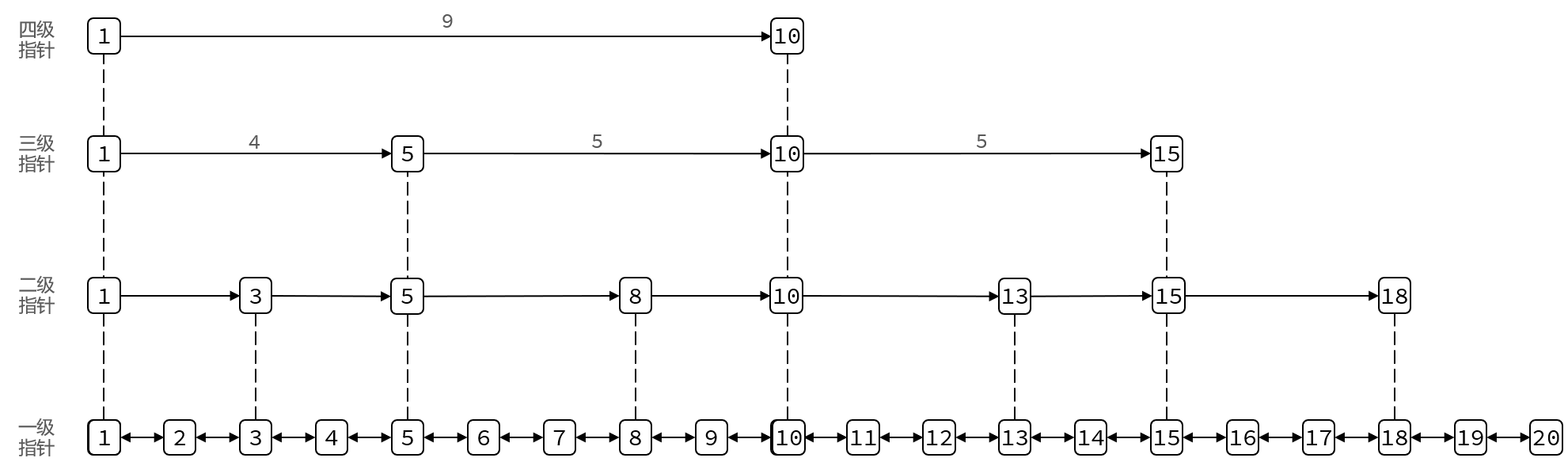
SkipList的特点:
- 跳跃表是一个双向链表,每个节点都包含score和ele值
- 节点按照score值排序,score值一样则按照ele字典排序
- 每个节点都可以包含多层指针,层数是1到32之间的随机数
- 不同层指针到下一个节点的跨度不同,层级越高,跨度越大
- 增删改查效率与红黑树基本一致,实现却更简单
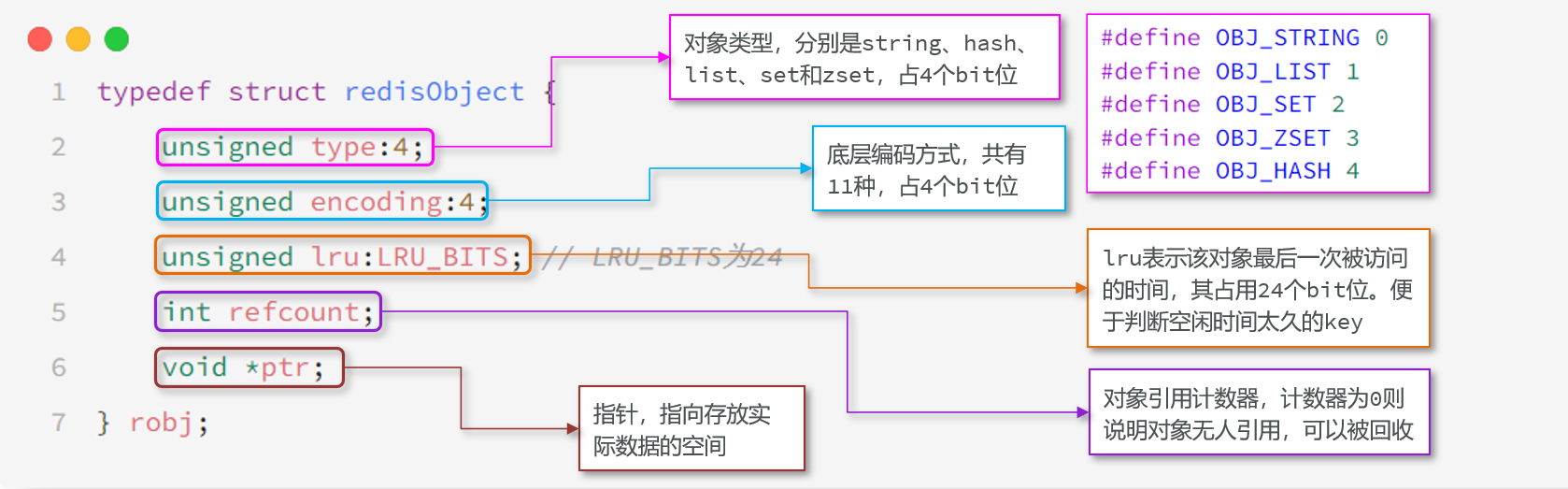
1.7 RedisObject
Redis中的任意数据类型的键和值都会被封装为一个RedisObject,也叫做Redis对象
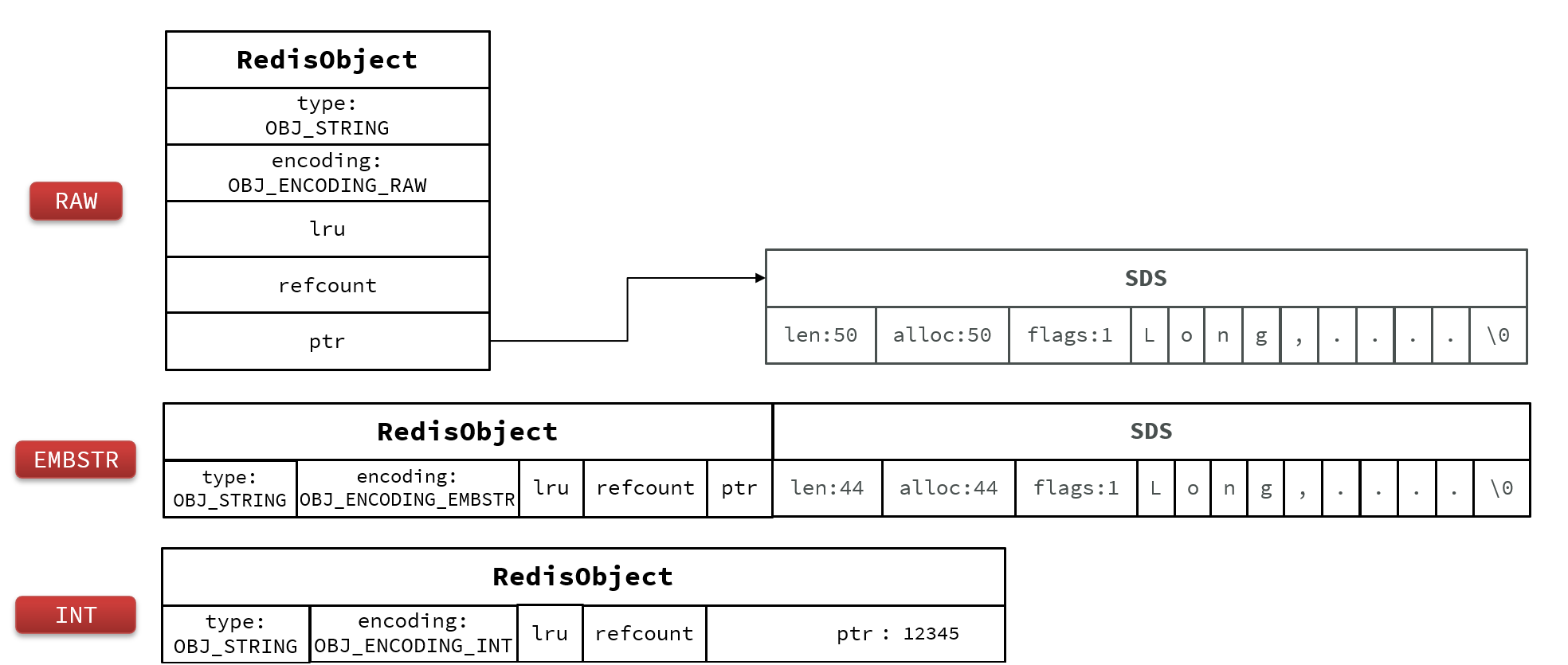
1.8 Redis基本数据类型-String
String是Redis中最常见的数据存储类型:
- 其基本编码方式是RAW,基于简单动态字符串(SDS)实现,存储上限为512mb。
- 如果存储的SDS长度小于44字节,则会采用EMBSTR编码,此时object head与SDS是一段连续空间。申请内存时只需要调用一次内存分配函数,效率更高。
- 如果存储的字符串是整数值,并且大小在LONG_MAX范围内,则会采用INT编码:直接将数据保存在RedisObject的ptr指针位置(刚好8字节),不再需要SDS了。
1.9 Redis基本数据类型-List
Redis的List类型可以从首、尾操作列表中的元素:
- 在3.2版本之前,Redis采用ZipList和LinkedList来实现List,当元素数量小于512并且元素大小小于64字节时采用ZipList编码,超过则采用LinkedList编码。
- 在3.2版本之后,Redis统一采用QuickList来实现List
- LinkedList :普通链表,可以从双端访问,内存占用较高,内存碎片较多
- ZipList :压缩列表,可以从双端访问,内存占用低,存储上限低
- QuickList:LinkedList + ZipList,可以从双端访问,内存占用较低,包含多个ZipList,存储上限高
1.10 Redis基本数据类型-Set
Set是Redis中的单列集合,满足下列特点:
- 不保证有序性
- 保证元素唯一
- 求交集、并集、差集
什么样的数据结构可以满足?
- HashTable,也就是Redis中的Dict,不过Dict是双列集合(可以存键、值对)
Set是Redis中的集合,不一定确保元素有序,可以满足元素唯一、查询效率要求极高。
- 为了查询效率和唯一性,set采用HT编码(Dict)。Dict中的key用来存储元素,value统一为null。
- 当存储的所有数据都是整数,并且元素数量不超过set-max-intset-entries时,Set会采用IntSet编码,以节省内存
1.11 Redis基本数据类型-ZSet
ZSet也就是SortedSet,其中每一个元素都需要指定一个score值和member值:
- 可以根据score值排序后
- member必须唯一
- 可以根据member查询分数
因此,zset底层数据结构必须满足键值存储、键必须唯一、可排序这几个需求。之前学习的哪种编码结构可以满足?
- SkipList:可以排序,并且可以同时存储score和ele值(member)
- HT(Dict):可以键值存储,并且可以根据key找value
当元素数量不多时,HT和SkipList的优势不明显,而且更耗内存。因此zset还会采用ZipList结构来节省内存,不过需要同时满足两个条件:
- 元素数量小于zset_max_ziplist_entries,默认值128
- 每个元素都小于zset_max_ziplist_value字节,默认值64
ziplist本身没有排序功能,而且没有键值对的概念,因此需要有zset通过编码实现:
- ZipList是连续内存,因此score和element是紧挨在一起的两个entry, element在前,score在后
- score越小越接近队首,score越大越接近队尾,按照score值升序排列
1.12 Redis基本数据类型-Hash
Hash结构与Redis中的Zset非常类似:
- 都是键值存储
- 都需求根据键获取值
- 键必须唯一
区别如下:
- zset的键是member,值是score;hash的键和值都是任意值
- zset要根据score排序;hash则无需排序
因此,Hash底层采用的编码与Zset也基本一致,只需要把排序有关的SkipList去掉即可
- Hash结构默认采用ZipList编码,用以节省内存。 ZipList中相邻的两个entry 分别保存field和value
- 当数据量较大时,Hash结构会转为HT编码,也就是Dict,触发条件有两个:
- ZipList中的元素数量超过了hash-max-ziplist-entries(默认512)
- ZipList中的任意entry大小超过了hash-max-ziplist-value(默认64字节)
2. Redis网络模型
2.1 用户空间和内核态空间
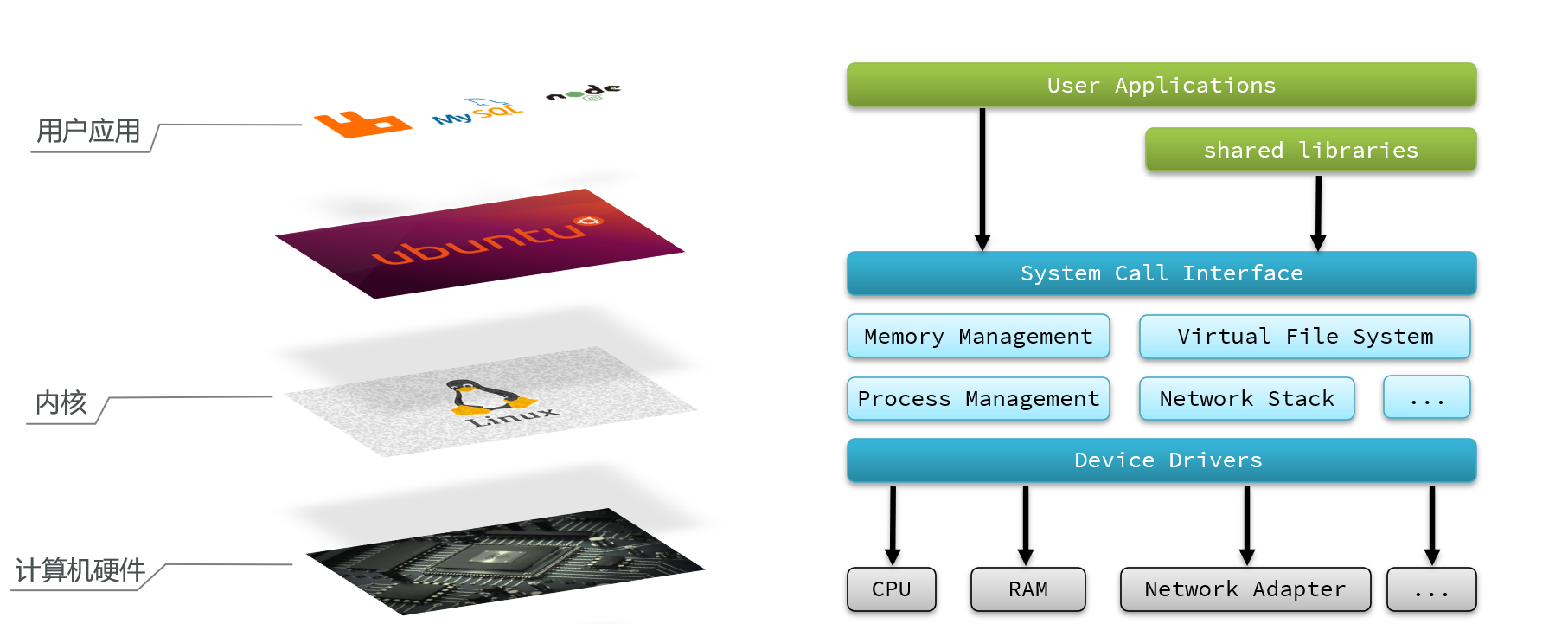
用户的应用,比如redis,mysql等其实是没有办法去执行访问我们操作系统的硬件的,所以我们可以通过发行版的这个壳子去访问内核,再通过内核去访问计算机硬件
计算机硬件包括,如cpu,内存,网卡等等,内核(通过寻址空间)可以操作硬件的,但是内核需要不同设备的驱动,有了这些驱动之后,内核就可以去对计算机硬件去进行 内存管理,文件系统的管理,进程的管理等等
为了避免用户应用导致冲突甚至内核崩溃,用户应用与内核是分离的:
- 进程的寻址空间划分成两部分:内核空间、用户空间
- 用户空间只能执行受限的命令(Ring3),而且不能直接调用系统资源,必须通过内核提供的接口来访
- 内核空间可以执行特权命令(Ring0),调用一切系统资源
Linux系统为了提高IO效率,会在用户空间和内核空间都加入缓冲区:
- 写数据时,要把用户缓冲数据拷贝到内核缓冲区,然后写入设备
- 读数据时,要从设备读取数据到内核缓冲区,然后拷贝到用户缓冲区
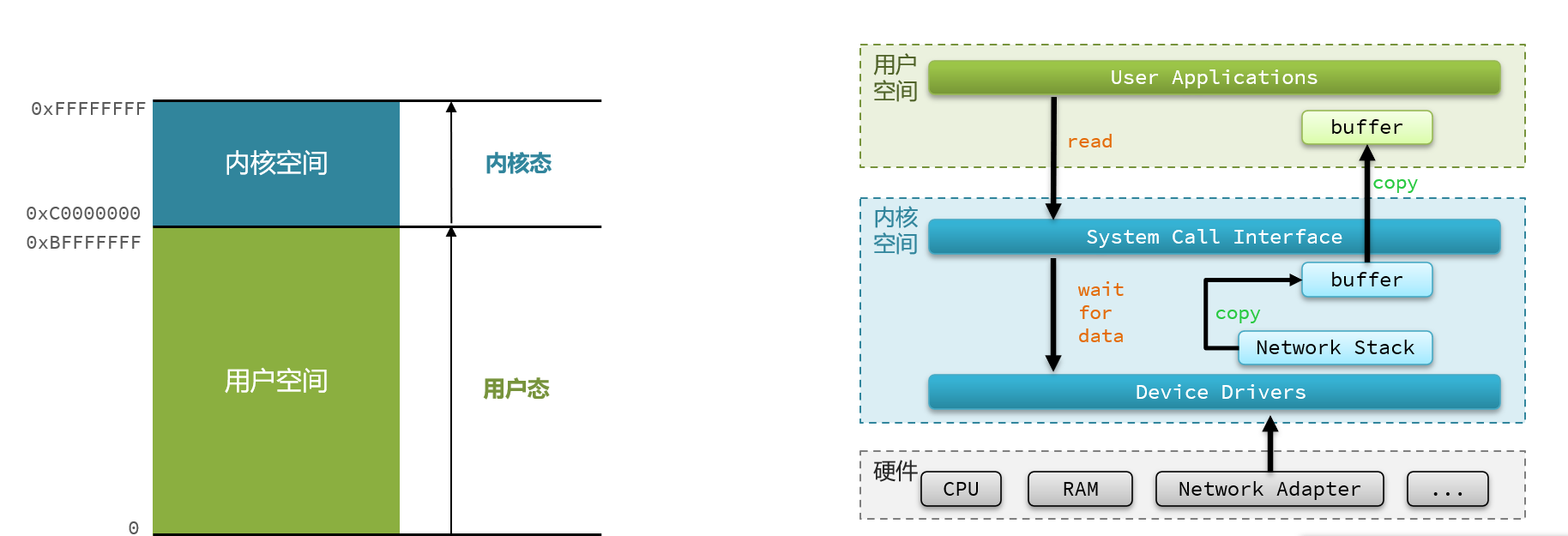
2.2 阻塞IO
总结归纳了5种IO模型:
- 阻塞IO(Blocking IO)
- 非阻塞IO(Nonblocking IO)
- IO多路复用(IO Multiplexing)
- 信号驱动IO(Signal Driven IO)
- 异步IO(Asynchronous IO)
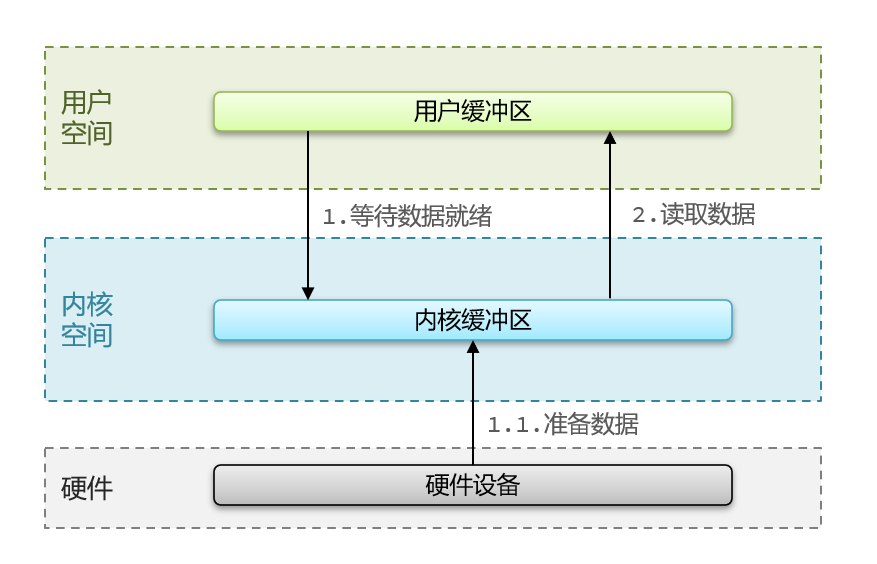
用户去读取数据时,会去先发起recvform一个命令,去尝试从内核上加载数据,如果内核没有数据,那么用户就会等待,此时内核会去从硬件上读取数据,内核读取数据之后,会把数据拷贝到用户态,并且返回ok,整个过程,都是阻塞等待的,这就是阻塞IO
顾名思义,阻塞IO就是两个阶段都必须阻塞等待,具体流程如下图:
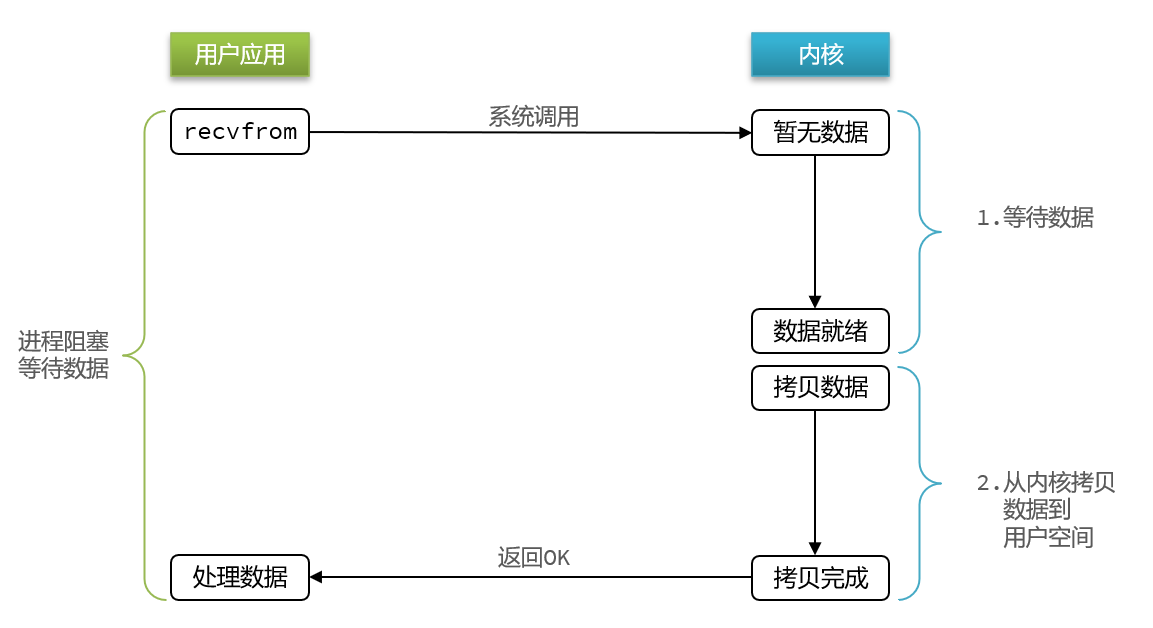
阶段一:
- 用户进程尝试读取数据(比如网卡数据)
- 此时数据尚未到达,内核需要等待数据
- 此时用户进程也处于阻塞状态
阶段二:
- 数据到达并拷贝到内核缓冲区,代表已就绪
- 将内核数据拷贝到用户缓冲区
- 拷贝过程中,用户进程依然阻塞等待
- 拷贝完成,用户进程解除阻塞,处理数据
可以看到,阻塞IO模型中,用户进程在两个阶段都是阻塞状态。
2.3 非阻塞IO
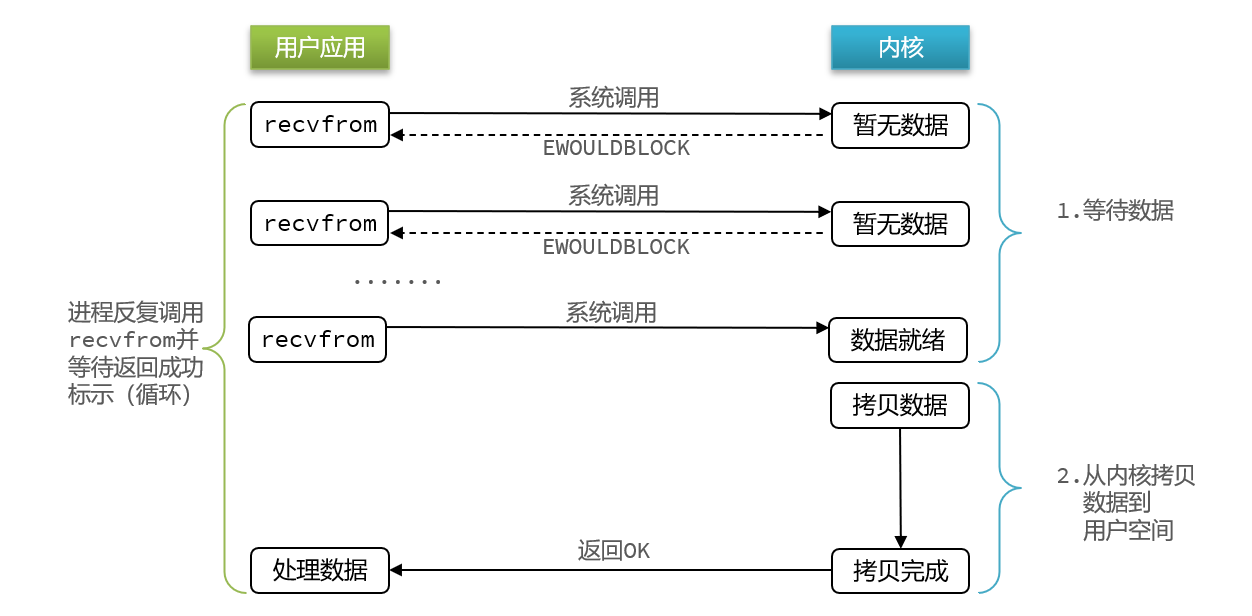
顾名思义,非阻塞IO的recvfrom操作会立即返回结果而不是阻塞用户进程。
阶段一:
- 用户进程尝试读取数据(比如网卡数据)
- 此时数据尚未到达,内核需要等待数据
- 返回异常给用户进程
- 用户进程拿到error后,再次尝试读取
- 循环往复,直到数据就绪
阶段二:
- 将内核数据拷贝到用户缓冲区
- 拷贝过程中,用户进程依然阻塞等待
- 拷贝完成,用户进程解除阻塞,处理数据
- 可以看到,非阻塞IO模型中,用户进程在第一个阶段是非阻塞,第二个阶段是阻塞状态。虽然是非阻塞,但性能并没有得到提高。而且忙等机制会导致CPU空转,CPU使用率暴增。
2.4 IO多路复用
无论是阻塞IO还是非阻塞IO,用户应用在一阶段都需要调用recvfrom来获取数据,差别在于无数据时的处理方案:
如果调用recvfrom时,恰好没有数据,阻塞IO会使CPU阻塞,非阻塞IO使CPU空转,都不能充分发挥CPU的作用。
如果调用recvfrom时,恰好有数据,则用户进程可以直接进入第二阶段,读取并处理数据
而在单线程情况下,只能依次处理IO事件,如果正在处理的IO事件恰好未就绪(数据不可读或不可写),线程就会被阻塞,所有IO事件都必须等待,性能自然会很差。文件描述符(File Descriptor):简称FD,是一个从0 开始的无符号整数,用来关联Linux中的一个文件。在Linux中,一切皆文件,例如常规文件、视频、硬件设备等,当然也包括网络套接字(Socket)。
IO多路复用:是利用单个线程来同时监听多个FD,并在某个FD可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。
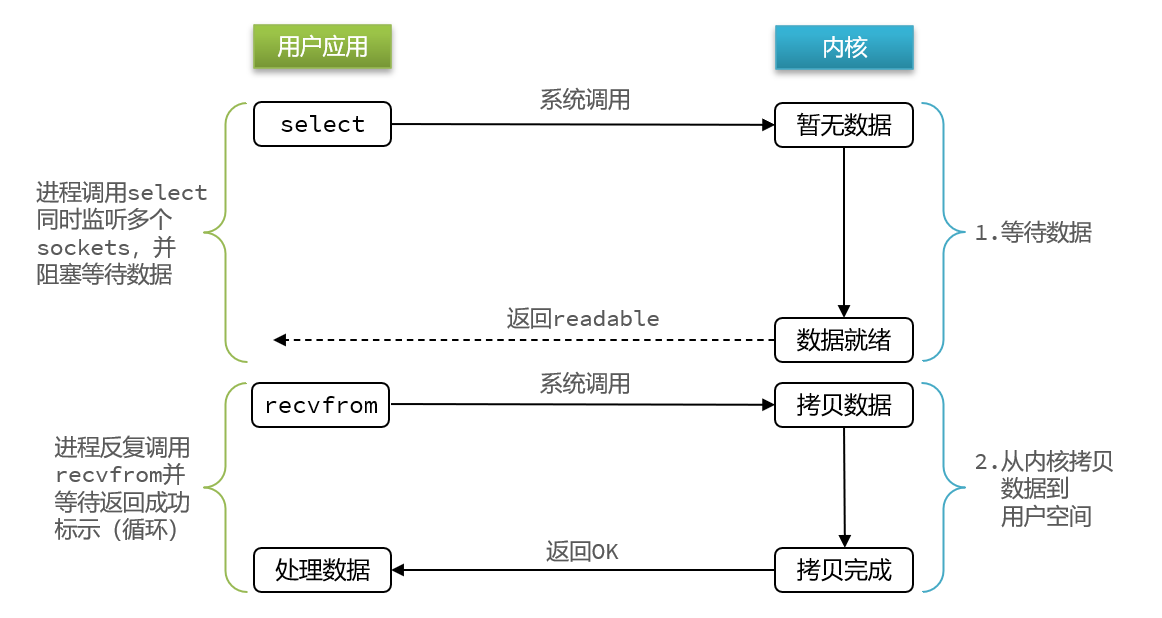
阶段一:
- 用户进程调用select,指定要监听的FD集合
- 核监听FD对应的多个socket
- 任意一个或多个socket数据就绪则返回readable
- 此过程中用户进程阻塞
阶段二:
- 用户进程找到就绪的socket
- 依次调用recvfrom读取数据
- 内核将数据拷贝到用户空间
- 用户进程处理数据
IO多路复用常见方式的有:
select
poll
epoll
其中select和pool相当于是当被监听的数据准备好之后,他会把你监听的FD整个数据都发给你,你需要到整个FD中去找,哪些是处理好了的,需要通过遍历的方式,所以性能也并不是那么好
而epoll,则相当于内核准备好了之后,他会把准备好的数据,直接发给你,咱们就省去了遍历的动作。
2.5 IO多路复用的三种方式
2.5.1 select方式
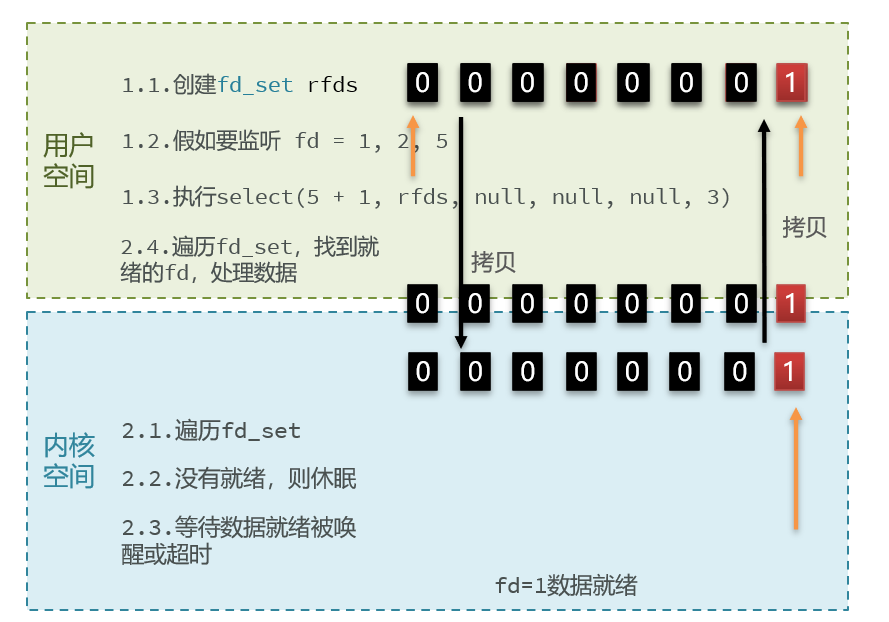
select模式存在的问题:
- 需要将整个fd_set从用户空间拷贝到内核空间,select结束还要再次拷贝回用户空间
- select无法得知具体是哪个fd就绪,需要遍历整个fd_set
- fd_set监听的fd数量不能超过1024
2.5.2 poll模式
poll模式对select模式做了简单改进,但性能提升不明显
IO流程:
- 创建pollfd数组,向其中添加关注的fd信息,数组大小自定义
- 调用poll函数,将pollfd数组拷贝到内核空间,转链表存储,无上限
- 内核遍历fd,判断是否就绪
- 数据就绪或超时后,拷贝pollfd数组到用户空间,返回就绪fd数量n
- 用户进程判断n是否大于0,大于0则遍历pollfd数组,找到就绪的fd
与select对比:
- select模式中的fd_set大小固定为1024,而pollfd在内核中采用链表,理论上无上限
- 监听FD越多,每次遍历消耗时间也越久,性能反而会下降
2.5.3 epoll函数
epoll模式是对select和poll的改进,它提供了三个函数:
- 红黑树-> 记录的事要监听的FD
- 一个是链表->一个链表,记录的是就绪的FD
- 紧接着调用epoll_ctl操作,将要监听的数据添加到红黑树上去,并且给每个fd设置一个监听函数,这个函数会在fd数据就绪时触发,就是准备好了,现在就把fd把数据添加到list_head中去
- 调用epoll_wait函数
- 就去等待,在用户态创建一个空的events数组,当就绪之后,我们的回调函数会把数据添加到list_head中去,当调用这个函数的时候,会去检查list_head,当然这个过程需要参考配置的等待时间,可以等一定时间,也可以一直等, 如果在此过程中,检查到了list_head中有数据会将数据添加到链表中,此时将数据放入到events数组中,并且返回对应的操作的数量,用户态的此时收到响应后,从events中拿到对应准备好的数据的节点,再去调用方法去拿数据。
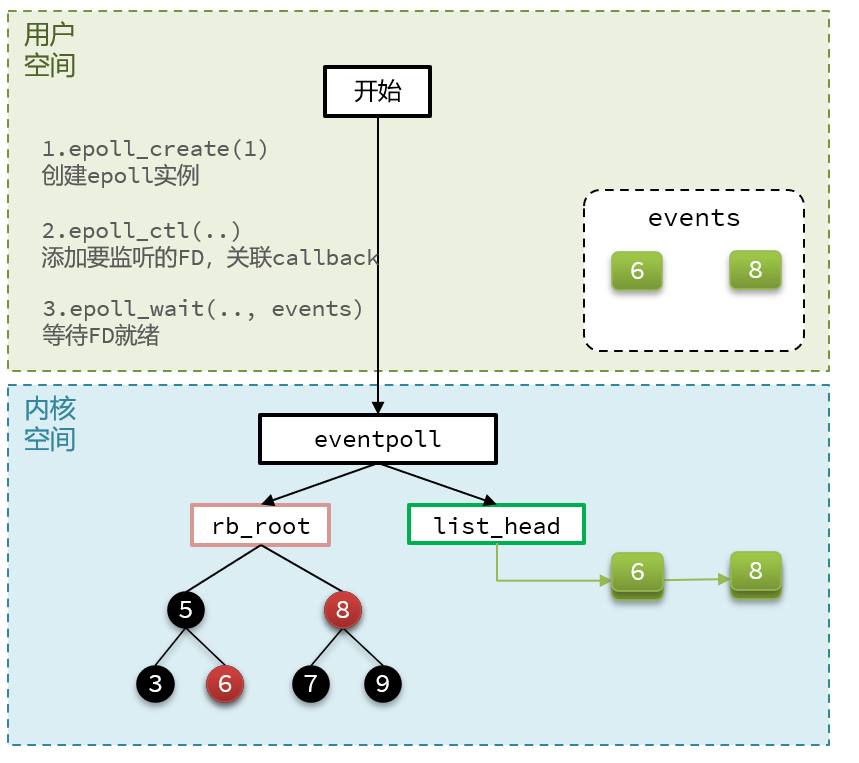
2.5.4 总结
select模式存在的三个问题:
- 能监听的FD最大不超过1024
- 每次select都需要把所有要监听的FD都拷贝到内核空间
- 每次都要遍历所有FD来判断就绪状态
poll模式的问题:
- poll利用链表解决了select中监听FD上限的问题,但依然要遍历所有FD,如果监听较多,性能会下降
epoll模式中如何解决这些问题的?
- 基于epoll实例中的红黑树保存要监听的FD,理论上无上限,而且增删改查效率都非常高
- 每个FD只需要执行一次epoll_ctl添加到红黑树,以后每次epol_wait无需传递任何参数,无需重复拷贝FD到内核空间
- 利用ep_poll_callback机制来监听FD状态,无需遍历所有FD,因此性能不会随监听的FD数量增多而下降
2.6 IO多路复用-epoll
2.6.1 时间通知机制
当FD有数据可读时,我们调用epoll_wait(或者select、poll)可以得到通知。但是事件通知的模式有两种:
- LevelTriggered:简称LT,也叫做水平触发。只要某个FD中有数据可读,每次调用epoll_wait都会得到通知。
- EdgeTriggered:简称ET,也叫做边沿触发。只有在某个FD有状态变化时,调用epoll_wait才会被通知。
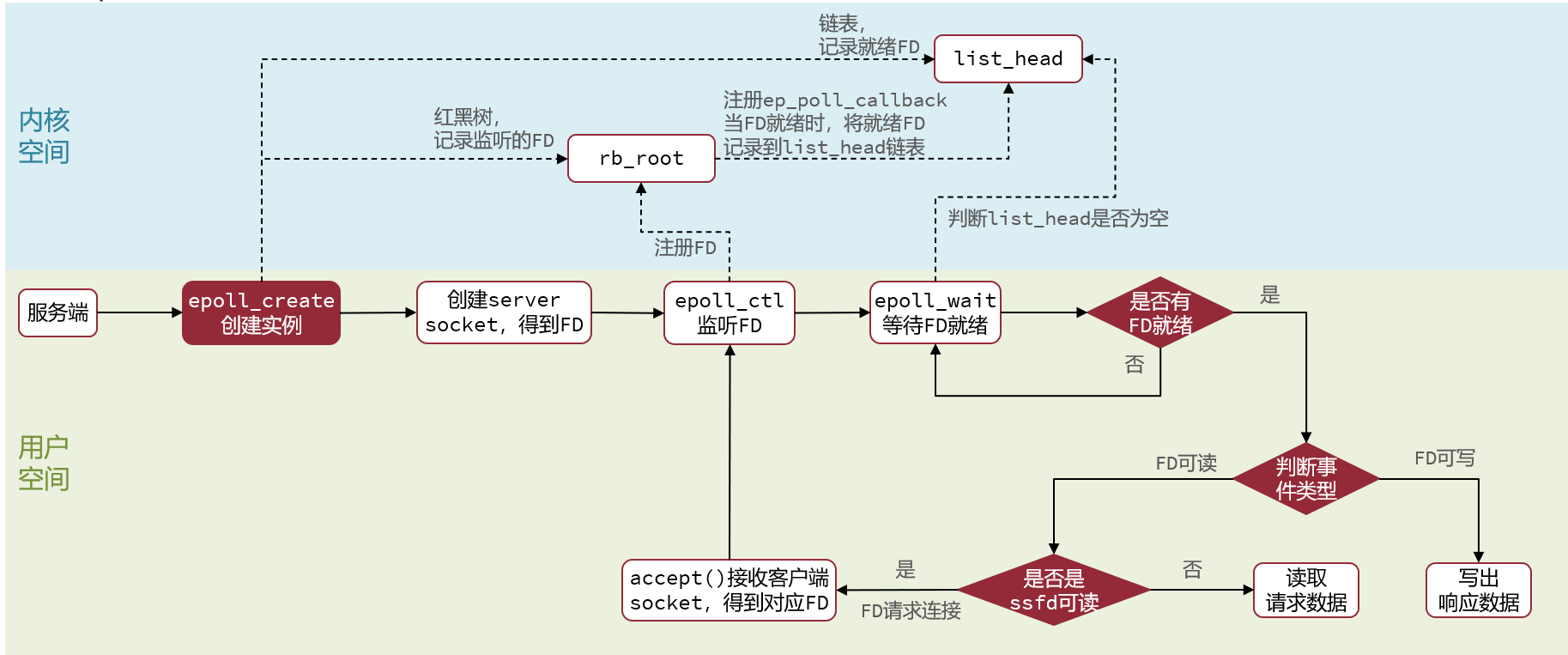
2.6.2 基于epoll的服务器端流程
基于epoll模式的web服务的基本流程如图:
2.7 信号驱动IO
信号驱动IO是与内核建立SIGIO的信号关联并设置回调,当内核有FD就绪时,会发出SIGIO信号通知用户,期间用户应用可以执行其它业务,无需阻塞等待。
阶段一:
- 用户进程调用sigaction,注册信号处理函数
- 内核返回成功,开始监听FD
- 用户进程不阻塞等待,可以执行其它业务
- 当内核数据就绪后,回调用户进程的SIGIO处理函数
阶段二:
- 收到SIGIO回调信号
- 调用recvfrom,读取
- 内核将数据拷贝到用户空间
- 用户进程处理数据
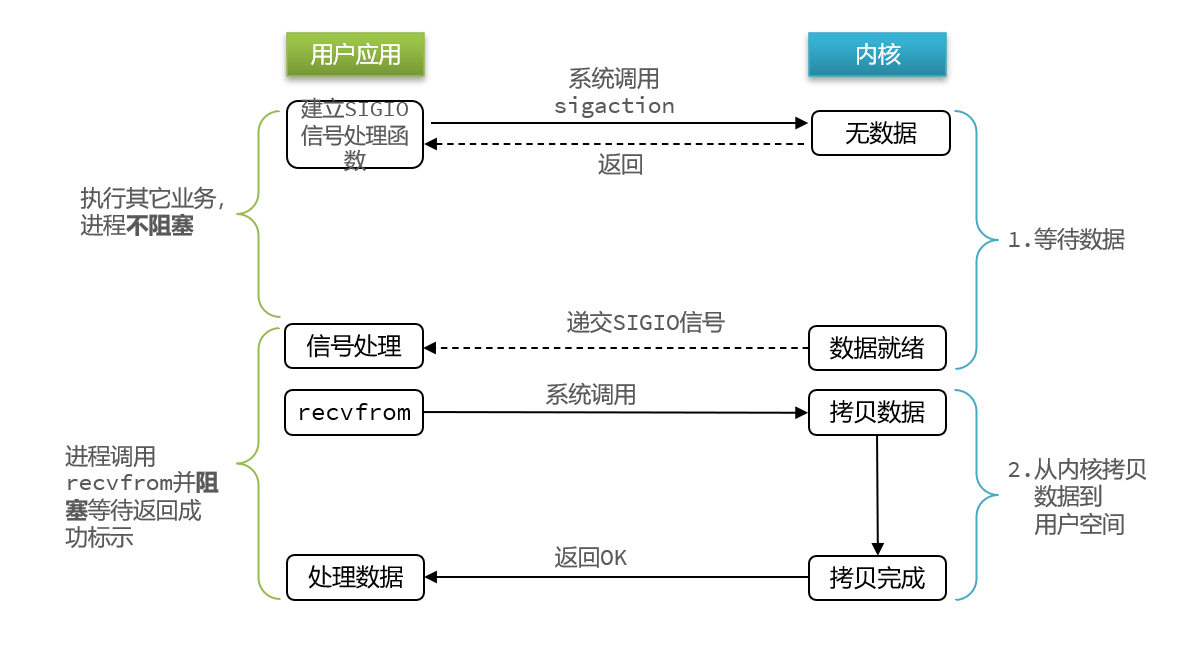
- 缺点:当有大量IO操作时,信号较多,SIGIO处理函数不能及时处理可能导致信号队列溢出,而且内核空间与用户空间的频繁信号交互性能也较低。
2.8 异步IO
异步IO的整个过程都是非阻塞的,用户进程调用完异步API后就可以去做其它事情,内核等待数据就绪并拷贝到用户空间后才会递交信号,通知用户进程。
- 异步IO模型中,用户进程在两个阶段都是非阻塞状态。
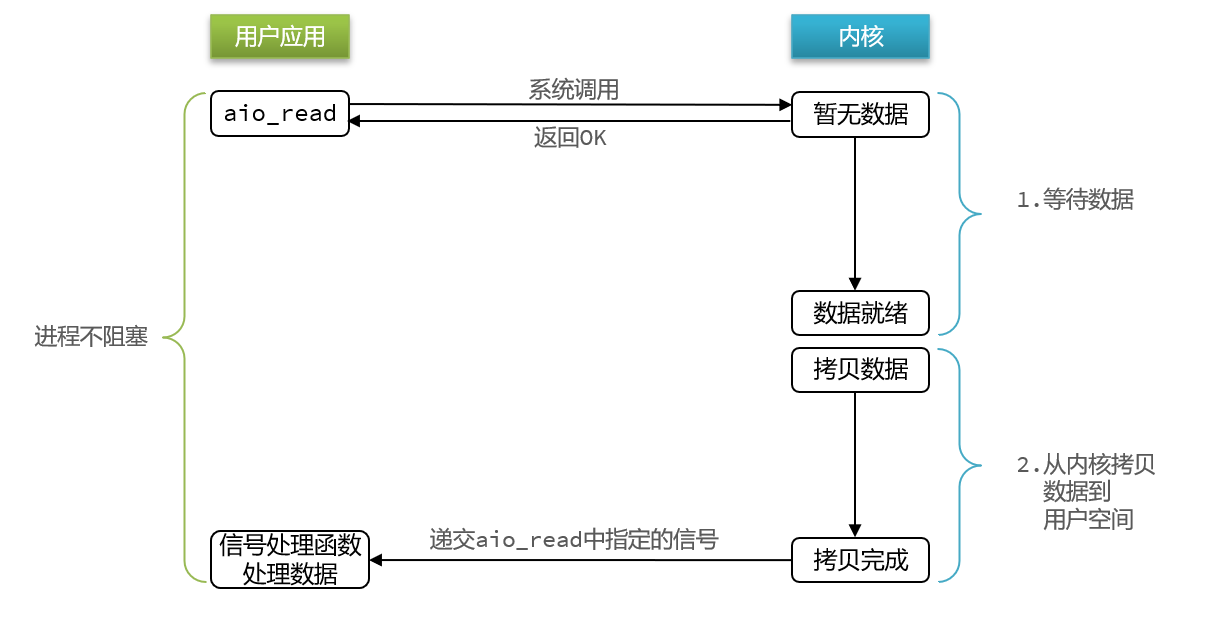
2.9 五种IO模型对比
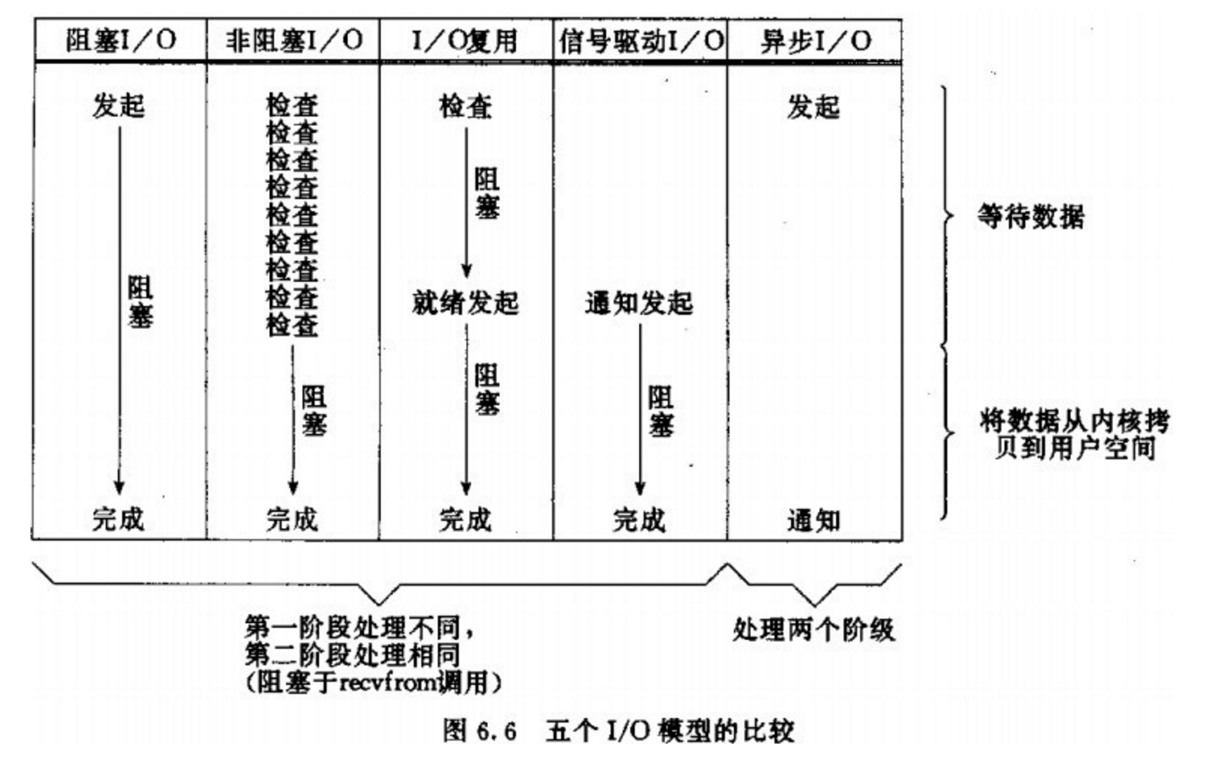
2.10 Redis网络模型
2.10.1 Redis是单线程的吗?为什么使用单线程
Redis到底是单线程还是多线程?
- 如果仅仅聊Redis的核心业务部分(命令处理),答案是单线程
- 如果是聊整个Redis,那么答案就是多线程
在Redis版本迭代过程中,在两个重要的时间节点上引入了多线程的支持:
- Redis v4.0:引入多线程异步处理一些耗时较旧的任务,例如异步删除命令unlink
- Redis v6.0:在核心网络模型中引入 多线程,进一步提高对于多核CPU的利用率
为什么Redis要选择单线程?
- 抛开持久化不谈,Redis是纯 内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度,因此多线程并不会带来巨大的性能提升。
- 多线程会导致过多的上下文切换,带来不必要的开销
- 引入多线程会面临线程安全问题,必然要引入线程锁这样的安全手段,实现复杂度增高,而且性能也会大打折扣
2.10.2 Redis单线程和多线程网络模型变更
Redis通过IO多路复用来提高网络性能,并且支持各种不同的多路复用实现,并且将这些实现进行封装, 提供了统一的高性能事件库API库 AE
Redis 6.0版本中引入了多线程,目的是为了提高IO读写效率。因此在解析客户端命令、写响应结果时采用了多线程。核心的命令执行、IO多路复用模块依然是由主线程执行。
3. 通信协议
3.1 RESP协议
Redis是一个CS架构的软件,通信一般分两步:
- 客户端(client)向服务端(server)发送一条命令
- 服务端解析并执行命令,返回响应结果给客户端
因此客户端发送命令的格式、服务端响应结果的格式必须有一个规范,这个规范就是通信协议。
- 而在Redis中采用的是RESP(Redis Serialization Protocol)协议:
RESP协议的数据类型
在RESP中,通过首字节的字符来区分不同数据类型,常用的数据类型包括5种:
- 单行字符串:首字节是 ‘+’ ,后面跟上单行字符串,以CRLF( “\r\n” )结尾。例如返回”OK”: “+OK\r\n”
- 错误(Errors):首字节是 ‘-’ ,与单行字符串格式一样,只是字符串是异常信息,例如:”-Error message\r\n”
- 数值:首字节是 ‘:’ ,后面跟上数字格式的字符串,以CRLF结尾。例如:”:10\r\n”
- 多行字符串:首字节是 ‘$’ ,表示二进制安全的字符串,最大支持512MB:
- 如果大小为0,则代表空字符串:”$0\r\n\r\n”
- 如果大小为-1,则代表不存在:”$-1\r\n”
- 数组:首字节是 ‘*’,后面跟上数组元素个数,再跟上元素,元素数据类型不限:
3.2 基于Socket自定义Redis的客户端
Redis支持TCP通信,因此我们可以使用Socket来模拟客户端,与Redis服务端建立连接:
1 | |
4. Redis内存回收
Redis之所以性能强,最主要的原因就是基于内存存储。然而单节点的Redis其内存大小不宜过大,会影响持久化或主从同步性能。
当内存使用达到上限时,就无法存储更多数据了。为了解决这个问题,Redis提供了一些策略实现内存回收:
- 内存过期策略
- 内存淘汰策略
4.1 内存过期策略
在学习Redis缓存的时候我们说过,可以通过expire命令给Redis的key设置TTL(存活时间):
- 可以发现,当key的TTL到期以后,再次访问name返回的是nil,说明这个key已经不存在了,对应的内存也得到释放。从而起到内存回收的目的。
Redis本身是一个典型的key-value内存存储数据库,因此所有的key、value都保存在之前学习过的Dict结构中。不过在其database结构体中,有两个Dict:一个用来记录key-value;另一个用来记录key-TTL。
1 | |
Redis是如何知道一个key是否过期呢?
- 利用两个Dict分别记录key-value对及key-ttl对
是不是TTL到期就立即删除了呢?
惰性删除
惰性删除:顾明思议并不是在TTL到期后就立刻删除,而是在访问一个key的时候,检查该key的存活时间,如果已经过期才执行删除。
周期删除
周期删除:顾明思议是通过一个定时任务,周期性的抽样部分过期的key,然后执行删除。执行周期有两种:
- Redis服务初始化函数initServer()中设置定时任务,按照server.hz的频率来执行过期key清理,模式为SLOW
- Redis的每个事件循环前会调用beforeSleep()函数,执行过期key清理,模式为FAST
SLOW模式规则:
- 执行频率受server.hz影响,默认为10,即每秒执行10次,每个执行周期100ms。
- 执行清理耗时不超过一次执行周期的25%.默认slow模式耗时不超过25ms
- 逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期
- 如果没达到时间上限(25ms)并且过期key比例大于10%,再进行一次抽样,否则结束
FAST模式规则(过期key比例小于10%不执行 ):
- 执行频率受beforeSleep()调用频率影响,但两次FAST模式间隔不低于2ms
- 执行清理耗时不超过1ms
- 逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期
如果没达到时间上限(1ms)并且过期key比例大于10%,再进行一次抽样,否则结束
总结
RedisKey的TTL记录方式:
- 在RedisDB中通过一个Dict记录每个Key的TTL时间
过期key的删除策略:
- 惰性清理:每次查找key时判断是否过期,如果过期则删除
- 定期清理:定期抽样部分key,判断是否过期,如果过期则删除。
定期清理的两种模式:
- SLOW模式执行频率默认为10,每次不超过25ms
- FAST模式执行频率不固定,但两次间隔不低于2ms,每次耗时不超过1ms
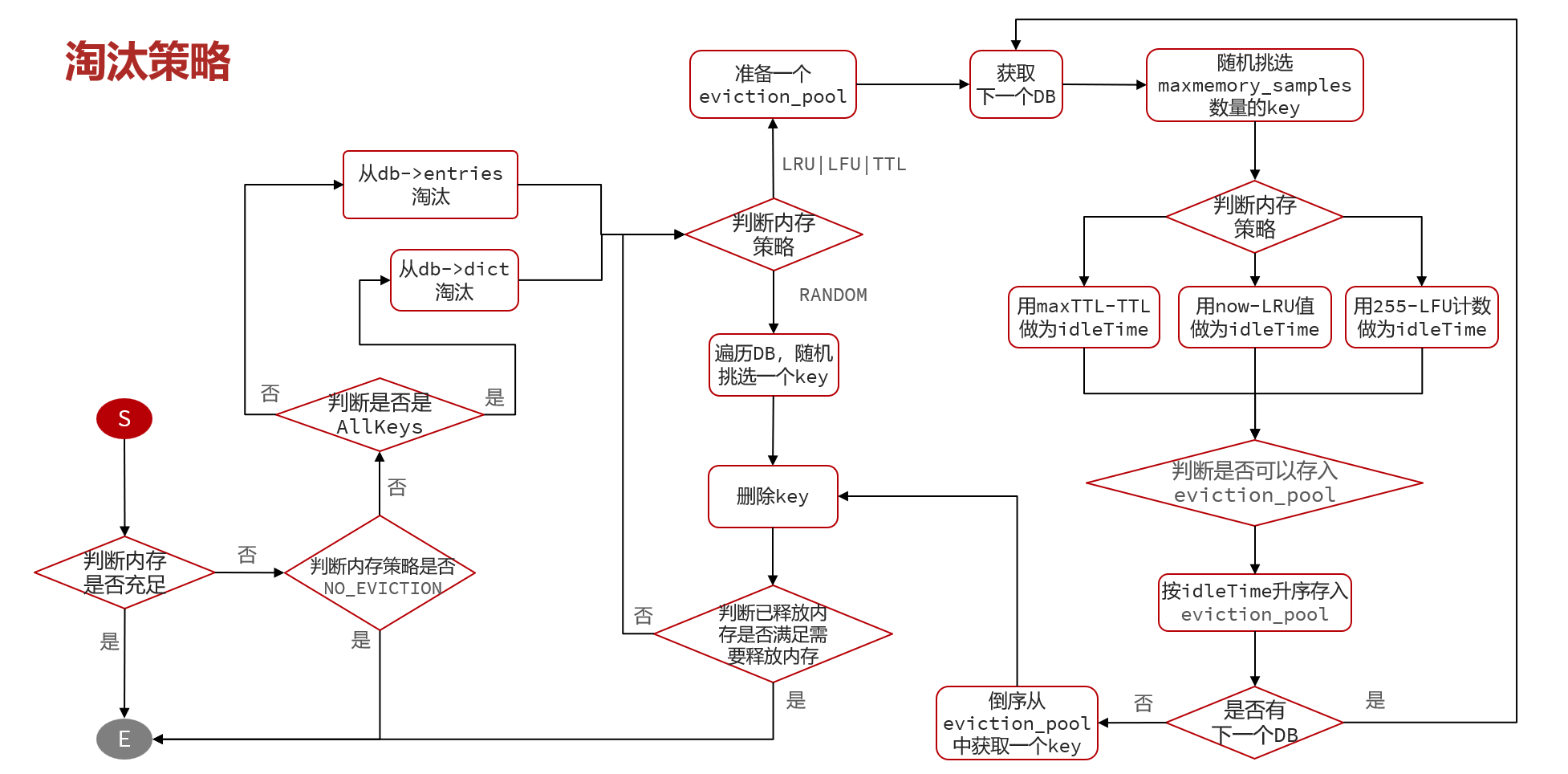
4.2 内存淘汰策略
内存淘汰:就是当Redis内存使用达到设置的上限时,主动挑选部分key删除以释放更多内存的流程。
Redis会在处理客户端命令的方法processCommand()中尝试做内存淘汰
Redis支持8种不同策略来选择要删除的key:
- noeviction: 不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。
- volatile-ttl: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
- allkeys-random:对全体key ,随机进行淘汰。也就是直接从db->dict中随机挑选
- volatile-random:对设置了TTL的key ,随机进行淘汰。也就是从db->expires中随机挑选。
- allkeys-lru: 对全体key,基于LRU算法进行淘汰
- volatile-lru: 对设置了TTL的key,基于LRU算法进行淘汰
- allkeys-lfu: 对全体key,基于LFU算法进行淘汰
- volatile-lfu: 对设置了TTL的key,基于LFI算法进行淘汰
比较容易混淆的有两个:
- LRU(Least Recently Used),最少最近使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
- LFU(Least Frequently Used),最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。
Redis的数据都会被封装为RedisObject结构:
1 | |
LFU的访问次数之所以叫做逻辑访问次数,是因为并不是每次key被访问都计数,而是通过运算:
- 生成0~1之间的随机数R
- 计算 (旧次数 * lfu_log_factor + 1),记录为P
- 如果 R < P ,则计数器 + 1,且最大不超过255
- 访问次数会随时间衰减,距离上一次访问时间每隔 lfu_decay_time 分钟,计数器 -1
五. 黑马点评简历
项目亮点:
- 采用 Redis 对高频访问的商户信息进行缓存,降低了数据库查询的压力,解决了缓存穿透、雪崩、击穿问题
- 通过 ThreadLocal 保存已登录用户信息,请求处理完后移除,避免内存泄露与资源浪费
- 利用 Redisson 分布式锁解决集群环境下的并发安全问题,结合乐观锁机制防止秒杀超卖问题
- 基于 Redis 实现分布式 Session 共享,使用拦截器实现用户的登录校验和权限刷新
- 实现基于推模式的 Feed 流功能,采用滚动分页,用户发布笔记时实时推送至粉丝消息队列
- 借助 Redis 的 ZSet 实现点赞排行榜,利用 Set 数据结构支持用户关注与共同关注功能
项目亮点详解
1. 采用 Redis 对高频访问的商户信息进行缓存,降低了数据库查询的压力,解决了缓存穿透、雪崩、击穿问题
1.1 缓存和内存的区别?
| 项目 | 缓存(Cache) | 内存(Memory,也叫主存,RAM) |
|---|---|---|
| 定义 | CPU与内存之间的高速缓存,用于存放近期使用的热点数据 | 计算机的主内存,用于存储当前运行中的程序和数据 |
| 作用 | 提高CPU访问数据的速度,减少对内存的访问频率 | 提供运行程序时所需的数据空间 |
- Redis 是一种常用的缓存技术:用来缓存热点数据、页面、Session 等,减轻数据库压力(基于内存,访问速度非常快)
1.2 使用Redis添加商户缓存的流程
- 查询数据库之前先查询缓存,如果缓存数据存在,则直接从缓存中返回,如果缓存数据不存在,再查询数据库,然后将数据存入redis
1 | |
1.3 如何保证数据库和缓存的一致性?
如果更新了数据库,导致数据库中的数据内容和当前缓存中保留的以前的内容不一致。如何保证一致性?
- 数据库是新的,缓存是旧的 —— 数据脏读
- 先更新数据库
- 再删除缓存
- 下次请求读缓存 -> 发现没了 -> 读数据库 -> 再写入缓存
如何保证缓存与数据库的操作的同时成功或失败?
- 单体系统,将缓存与数据库操作放在一个事务
- 分布式系统,利用TCC等分布式事务方案
1.4 如何解决缓存穿透?
- 缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库
常见的解决方案有两种:
- 缓存空对象
- 布隆过滤器
如何使用布隆过滤器解决缓存穿透问题?
用布隆过滤器提前记录 所有合法的 key(比如用户 ID、商品 ID)
- 请求进来先查布隆过滤器
- 如果布隆过滤器里都没有,那就直接拦截,不用查 Redis、数据库了。
布隆过滤器通过记录所有“合法 key”,在访问缓存前快速拦截掉非法请求,从而解决缓存穿透问题
布隆过滤:布隆过滤器其实采用的是哈希思想来解决这个问题,通过一个庞大的二进制数组,走哈希思想去判断当前这个要查询的这个数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时redis中的数据过期了,但是数据库中一定存在这个数据,在数据库中查询出来这个数据后,再将其放入到redis中,
假设布隆过滤器判断这个数据不存在,则直接返回
这种方式优点在于节约内存空间,存在误判,误判原因在于:布隆过滤器走的是哈希思想,只要哈希思想,就可能存在哈希冲突
- 有一定误判率:可能会误判为存在,但不会误判为不存在
1.5 如何解决缓存雪崩?
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
- 给不同的Key的TTL添加随机值(同一时段,给不同key设置不同的TTL)
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略(微服务)
- 给业务添加多级缓存
这里我采用多级缓存的方式解决缓存雪崩问题
多级缓存 = 本地缓存(如 Caffeine) + 分布式缓存(如 Redis)
使用流程大致如下:
- 首先从一级缓存(caffeine-本地应用内)中查找数据;
- 如果没有的话,则从二级缓存(redis-内存)中查找数据;
- 如果还是没有的话,再从数据库(数据库-磁盘)中查找数据;
1.6 如何解决缓存击穿?
某个热点 key 在瞬间失效,大量并发请求同时访问这个 key,缓存没命中,导致并发打到数据库。
这里我用的是互斥锁的方式解决缓存击穿
常见的解决方案有:
- 互斥锁: 当缓存失效时,第一个线程获取锁并查询数据库,其它线程等待。
- 设置永不过期 + 后台定时异步更新缓存(当热点key的数量少,占用内存少的时候)
- 逻辑过期
设置永不过期 + 后台定时异步更新缓存
- 你不让缓存自然过期,而是用 主动刷新 来维持数据一致性
- 不会失效,自然也不会击穿
逻辑过期
- 我们把过期时间设置在 redis的value中,注意:这个过期时间并不会直接作用于redis,而是我们后续通过逻辑去处理
- 假设线程1去查询缓存,然后从value中判断出来当前的数据已经过期了,此时线程1去获得互斥锁,那么其他线程会进行阻塞
- 获得了锁的线程他会开启一个 线程去进行 以前的重构数据的逻辑,直到新开的线程完成这个逻辑后,才释放锁, 而线程1直接进行返回
- 假设现在线程3过来访问,由于线程线程2持有着锁,所以线程3无法获得锁,线程3也直接返回数据
- 只有等到新开的线程2把重建数据构建完后,其他线程才能走返回正确的数据。
2. 通过 ThreadLocal 保存已登录用户信息,请求处理完后移除,避免内存泄露与资源浪费
2.1 为什么不使用session存储用户信息,而是使用ThreadLocal存放用户信息?
- Session 依赖服务端状态,不适合分布式场景(Session共享问题)
- HttpSession 是服务端状态,会话信息默认保存在服务端内存中(如 Tomcat 内部)。
- 在分布式部署时,如果没有做 Session 共享(如使用 Redis Session),用户可能每次请求会打到不同的服务节点,导致 Session 丢失。
- 如果遇到高并发,多人同时登录系统时,会出现session混乱
- ThreadLocal 为每个线程维护一个独立副本,天然线程隔离,避免并发访问带来的数据安全问题
- 我们可以借助这个ThreadLocal来存储登录用户的信息,在一个请求中,所有调用的方法都在同一个线程中去处理,这样就实现了在任何地方都可以获取到用户信息了。
- 放到 ThreadLocal 就可以不用每次都查 Redis。如果你把这个 UserDTO 存到 ThreadLocal 中,那么在这一请求生命周期内,后续任何地方就可以直接从 ThreadLocal 取出用户信息,而不用重复从 Redis 查询或多层传参。
2.2 完整的用户登录 + 拦截器鉴权 + ThreadLocal 用户上下文管理
1 | |
- 定义用户实体:
UserDTO(用于存储登录用户的简化信息) - 定义工具类
UserHolder操作ThreadLocal(存放,获取,删除用户信息)
1 | |
- 登录拦截器:判断是否需要拦截(ThreadLocal中是否有用户)
- 访问接口时将用户信息放入ThreadLocal
- 访问结束时候删除ThreadLocal中信息(线程放入线程池并不一定会销毁)
1 | |
- 配置拦截器,让拦截器生效(拦截需要登录的接口)
1 | |
2.3 为什么请求处理完后要移除 ThreadLocal 的值?
目的:避免内存泄漏与资源浪费
原因:
- ThreadLocalMap 的 key 是弱引用,value 是强引用
- 当 ThreadLocal 实例(key)被 GC 回收后,如果没有手动 remove(),它对应的 value 会“悬挂”在内存中,而 ThreadLocalMap 是挂在 Thread 对象上的,线程不死,value 就不会释放,造成内存泄漏。
- 线程池复用线程:线程池导致线程长期存活,加剧泄漏问题
- 如果你在线程中使用了 ThreadLocal 但没调用 remove(),上一个请求的数据就可能被下一个请求复用的线程误用,造成数据泄漏和安全风险。
- ThreadLocal 的 key 是弱引用,若不及时调用 remove() 清除绑定数据,可能因线程池复用导致内存泄漏与用户数据错乱,尤其在高并发系统中危害更明显。
2.4 ThreadLocal原理(重点)
3. 利用 Redisson 分布式锁解决集群环境下的并发安全问题,结合乐观锁机制防止秒杀超卖问题
3.1 什么是集群环境下的并发安全问题?
- 一人一单:秒杀业务要求同一个优惠券,一个用户只能下一单
- 集群环境下的一人一单:
- 通过加锁可以解决在单机情况下的一人一单安全问题,但是在集群模式下就不行了
- 每个tomcat都有一个属于自己的jvm,每个JVM都有各自的锁监视器,导致不同JVM的锁在不同的锁监视器中
- 在集群模式下,加锁只是对该 JVM 给当前这台服务器的请求的加锁,而集群是多台服务器,所以要使用分布式锁,满足集群模式下多进程可见并且互斥的锁。
3.2 什么是分布式锁?
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁。
- 分布式锁的核心思想就是让大家都使用同一把锁,只要大家使用的是同一把锁,那么我们就能锁住线程,不让线程进行,让程序串行执行,这就是分布式锁的核心思路
3.3 Redisson分布式锁的原理和使用
Redisson 是一个 Java 客户端框架,基于 Redis 实现了分布式锁、分布式集合、分布式对象等高阶功能
Redisson 分布式锁的原理:
- 加锁原理:Redisson 使用 Redis 的
SET key value NX PX命令加锁- key 是锁名,value 是唯一标识(UUID+线程ID)
- 设置 30 秒过期时间(默认值,可配置)
- 看门狗机制(Watchdog)
- 如果使用 lock() 加锁(不带超时时间),Redisson 会启动一个后台定时任务,每隔 10 秒自动续期,将锁的过期时间续为 30 秒;
- 如果你主动设置了锁的过期时间,比如 lock(10, TimeUnit.SECONDS),则不会自动续期,10 秒后自动释放;
- 解锁原理
- Redisson 会验证当前线程是否是锁的拥有者(根据 UUID+线程ID 判断)
- 是的话执行 Lua 脚本删除锁,防止误删其他线程的锁(原子操作)
- 支持多种模式
- 公平锁:排队机制,先来先得(适用于高并发下公平访问资源的场景)
- 可重入锁:同一个线程可以多次获取同一把锁
使用Redission的分布式锁:
1 | |
3.4 为什么会出现超卖?
主要是在高并发场景下并发控制不当造成的,下面是一个典型流程:
- 多个用户同时查询库存(比如查到当前库存为 5)
- 多个用户几乎同时发起下单请求
- 系统来不及“同步更新”库存,导致多个请求都成功了 ➜ 库存变负数
卖出去的数量超过了实际库存。
3.5 什么是乐观锁?
悲观锁:
- 认为线程安全问题一定会发生,因此在操作数据之前先获取锁,确保线程串行执行。
- 例如Synchronized、Lock都属于悲观锁
乐观锁(CAS):
- 认为线程安全问题不一定会发生,因此不加锁,只是在更新数据时去判断有没有其它线程对数据做了修改。
- 如果没有修改则认为是安全的,自己才更新数据。
- 如果已经被其它线程修改说明发生了安全问题,此时可以重试或异常
3.6 如何使用乐观锁(CAS)解决超卖问题?
只要我扣减库存时的库存和之前我查询到的库存是一样的,就意味着没有人在中间修改过库存,那么此时就是安全的
我们的乐观锁需要变一下,改成stock大于0 即可
- 只要库存大于0,就可以买,不会超卖
1 | |
4. 使用 Redis 解决了在集群模式下的 Session 共享问题,使用拦截器实现用户的登录校验和权限刷新
4.1 什么是Session共享问题?
多台 Tomct 并不共享 session 存储空间,当请求切换到不同 tomcat 服务时导致数据丢失的问题。
每个tomcat中都有一份属于自己的session,假设用户第一次访问第一台tomcat,并且把自己的信息存放到第一台服务器的session中,但是第二次这个用户访问到了第二台tomcat,那么在第二台服务器上,肯定没有第一台服务器存放的session,所以此时 整个登录拦截功能就会出现问题
我们能如何解决这个问题呢?早期的方案是session拷贝,就是说虽然每个tomcat上都有不同的session,但是每当任意一台服务器的session修改时,都会同步给其他的Tomcat服务器的session,这样的话,就可以实现session的共享了
后来采用的方案都是基于redis来完成,我们把session换成redis,redis数据本身就是共享的,就可以避免session共享的问题了
4.2 如何在登录过程中用Redis代替Session的?
登录流程:
- 发送短信验证码:将验证码保存到Redis里面,而不是session
- 登录过程:根据手机号查询用户信息,不存在则新建,最后将用户数据保存到redis(作为值),并且生成token作为redis的key
- 校验登录状态:当我们校验用户是否登录时,会去携带着token进行访问,从redis中取出token对应的value,判断是否存在这个数据,如果没有则拦截,如果存在则将其保存到threadLocal中,并且放行。
4.3 还有其他解决方法吗?
- 基于 Cookie 的 Token 机制,不再使用服务器端保存 Session,而是通过客户端保存 Token(如 JWT)。
- Token 包含用户的认证信息(如用户 ID、权限等),并通过签名验证其完整性和真实性。
- 每次请求,客户端将 Token 放在 Cookie 或 HTTP 头中发送到服务,进行验证
4.4 如何使用拦截器实现用户的登录校验和权限刷新?
问题所在:
- 原始方案确实可以使用对应路径的拦截,同时刷新登录token令牌的存活时间,但是现在这个拦截器他只是拦截需要被拦截的路径
- 假设当前用户访问了一些不需要拦截的路径,那么这个拦截器就不会生效,所以此时令牌刷新的动作实际上就不会执行,所以这个方案他是存在问题的
实现方案:
- 我们可以添加一个拦截器
- 在第一个拦截器中拦截所有的路径,把第二个拦截器做的事情放入到第一个拦截器中,同时刷新令牌
- 因为第一个拦截器有了ThreadLocal的数据,所以此时第二个拦截器只需要判断拦截器中的user对象是否存在即可,完成整体刷新功能。
- 第一层拦截器是做全局处理,例如获取 Token,查询 Redis 中的用户信息,刷新 Token 有效期等通用操作。
- 第二层拦截器专注于验证用户登录的逻辑,如果路径需要登录,但用户未登录,则直接拦截请求。作用是拦截未登录的用户
好处:
- 职责分离:这种分层设计让每个拦截器的职责更加单一,代码更加清晰、易于维护
- 提升性能
5. 实现基于推模式的 Feed 流功能,采用滚动分页,用户发布笔记时实时推送至粉丝消息队列
5.1 什么是推模式的Feed流?
- 关注推送也叫做Feed流,直译为投喂。为用户持续的提供“沉浸式”的体验,通过无限下拉刷新获取新的信息
Feed流产品有两种常见模式
- Timeline:不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注。例如朋友圈
- 智能排序:利用智能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣信息来吸引用户(抖音)
Timeline的三种模式
跳转到共同推送查看
- 拉模式
- 推模式:也叫写扩散
- 推拉结合
推模式的Feed流
- 当张三写了一个内容,此时会主动的把张三写的内容发送到他的粉丝收件箱中去,假设此时李四再来读取,就不用再去临时拉取了(像朋友圈的方式)
- 用户发布笔记时实时推送至粉丝消息队列
5.2 为什么要使用滚动分页?
Feed流中的数据会不断更新,所以数据的角标也在变化,因此不能采用传统的分页模式。
- 如何实现Feed流的分页功能是一个复杂的问题,如果采用MyBatis中的分页插件是不能满足分页功能的,因为Feed流是一个动态的,数据会不断更新,因此数据的角标会不停更新,当我们需要查询第5-10条的数据时,可能又保存了一个新的数据到数据库,从而导致我们分页查找的数据存在与上一次查询的数据重复的问题
5.3 如何实现滚动分页?
滚动分页就是每次查询过数据库后,我们需要记录这一次查询结果的最后一条数据,下一次查询时,从这个位置开始去读取数据
- 每次查询完成后,我们要分析出查询出数据的最小时间戳,这个值会作为下一次查询的条件
- 我们需要找到与上一次查询相同的查询个数作为偏移量,下次查询时,跳过这些查询过的数据,拿到我们需要的数据
- 综上:我们的请求参数中就需要携带 lastId:上一次查询的最小时间戳 和偏移量这两个参数
6. 借助 Redis 的 ZSet 实现点赞排行榜,利用 Set 数据结构支持用户关注与共同关注功能
6.1 为什么使用ZSet实现点赞排行榜?
在探店笔记的详情页面,应该把给该笔记点赞的人显示出来,比如最早点赞的TOP5,形成点赞排行榜
- 点赞功能:使用set集合,因为点赞是不能重复的
- 点赞排行榜功能:使用sortedSet(ZSet),因为需要采用一个可以排序的set集合
ZSet:保存用户ID为键,用户点赞时间作为score进行排序
1 | |
查询top5的点赞用户: zrange key 0 4
6.2 如何利用Set实现用户关注和共同关注?
用户关注:是User之间的关系,是博主与粉丝的关系,数据库中有一张tb_follow表来表示
- 表的主键是当前用户ID,有一个FollowedID表示关注的用户ID
共同关注:在博主个人页面展示出当前用户与博主的共同关注呢
- 使用set集合,在set集合中,有交集并集补集的api
- 我们可以把两人的关注的人分别放入到一个set集合中,然后再通过api去查看这两个set集合中的交集数据。