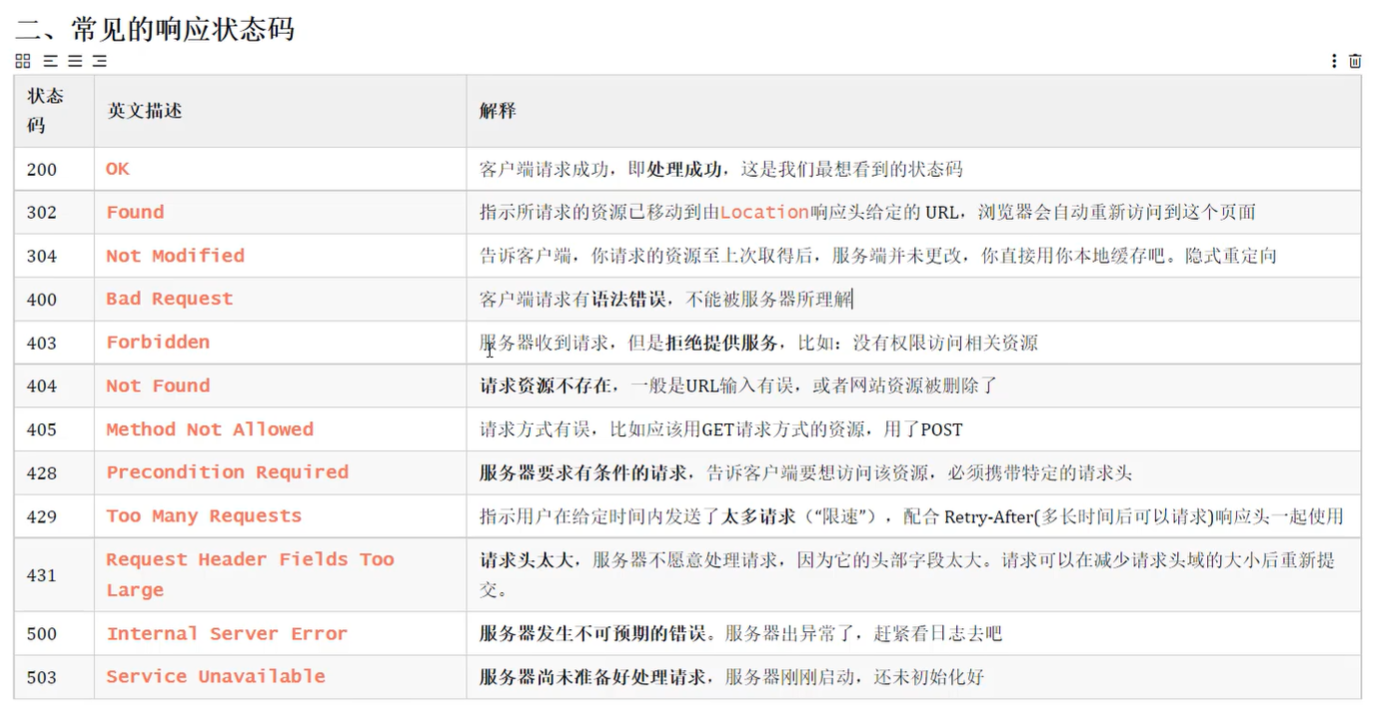
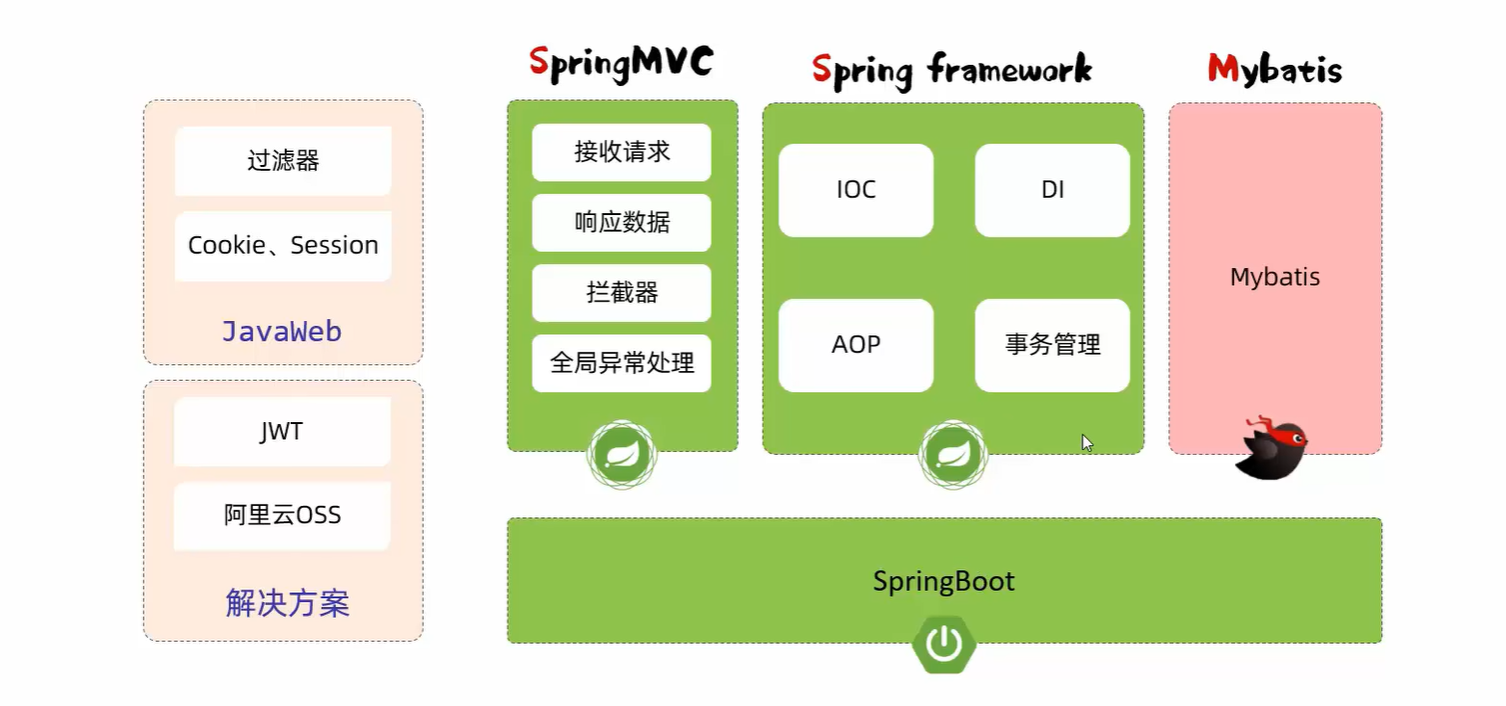
JavaWeb学习笔记
一. 前端开发 1. HTML HTML学习笔记
2. CSS CSS学习笔记
3. JavaScript JavaScript学习笔记
4. Vue A. Vue简介 Vue是一套前端框架 ,免除JS的DOM操作,简化书写
1 <script src ="js/vue.js" > </script >
1 2 3 4 5 6 7 8 <script>new Vue ({el : "#app" ,data : {message : "Hello Vue!"
1 2 3 4 <div id ="app" > <input type ="text" v-model ="message" > </div >
B. Vue常用指令
指令
作用
v-bind
为HTML标签绑定属性值,如设置href,css样式等
v-model
在表单元素上创建双向数据绑定
v-on
为HTML标签绑定事件
v-if/v-else-if/v-else
条件性的渲染某元素,判定为true时渲染,否则不渲染
v-show
根据条件展示某元素,区别在于切换的是display属性的值
v-for
列表渲染,遍历容器的元素或者对象的属性
v-bind :用来绑定 HTML 标签的属性,比如动态改变 href,src,class,style 等。
1 <a v-bind:href ="url" > 链接</a >
v-model :用于在表单元素上实现双向数据绑定,通常用于 input、textarea 或 select 元素。
1 <input v-model ="message" >
v-on :绑定事件处理程序,可以监听用户的交互操作,如点击、鼠标移入等。
1 <button v-on:click ="submitForm" > 提交</button >
v-if/v-else-if/v-else :用于条件渲染,如果条件为真,渲染元素,否则不渲染。
1 <p v-if ="isVisible" > 这是一个条件渲染的段落</p >
v-show :与 v-if 类似,不过 v-show 不会移除 DOM 元素,而是通过控制 display 样式来显示或隐藏元素。
1 <p v-show ="isVisible" > 这段内容根据条件展示</p >
v-for :用于列表渲染,遍历数组或对象。
1 2 3 <ul > <li v-for ="item in items" :key ="item.id" > {{ item.name }}</li > </ul >
C. Vue生命周期 Vue的生命周期指Vue对象创建和销毁的过程mounted: 挂载完成,Vue初始化成功,HTML页面渲染成功(发送请求到服务端,加载数据)
1 2 3 4 5 6 7 8 9 10 11 12 13 <script > new Vue ({ el : "#app" , data : { }, mounted ( console .log ("Vue挂载完毕,发送请求获取数据" ); }, methods : { }, }) </script >
5. Ajax A. 介绍 Asynchronous JavaScript And XML(异步的JavaScript和XML)作用
数据交换: 通过Ajax可以向服务器发送请求和接收服务器响应的数据
异步交互:可以在不重新加载整个页面的情况下,与服务器交换数据并更新部分页面的技术。如搜索联想功能
B. Axios 对原生的Ajax进行封装,简化书写,快速开发
引入Axios的JS文件
1 <script src ="js/axios-0.18.0.js" > </script >
使用Axios发送请求,并获取响应结果
axios.get(url [, config])
axios.delete(url [, config])
axios.post(url [, data[, config]])
axios.put(url [, data[, config]])
发送GET请求
1 2 3 axios.get("http://yapi.smart-xwork.cn/mock/169327/emp/list").then((result) => {
发送POST请求
1 2 3 axios.post("http://yapi.smart-xwork.cn/mock/169327/emp/deleteByld","id=1").then((result) => {
6. 前端工程化 A. YAPI(接口文档管理平台) YAPI官网
B. Vue项目创建 新建一个文件夹,在该文件夹中打开cmd,输入vue ui创建vue项目
C. Element Element官网
1. 快速入门
1 2 3 4 5 import ElementUI from 'element-ui' ;import 'element-ui/lib/theme-chalk/index.css' ;Vue .use (ElementUI );
2. 常用组件
Table表格表格
pagination分页分页
Dialog对话框对话框
Form表单表单
D. Vue路由 前端路由:URL中的hash(#号)与组件之间的对应关系
VueRouter:路由器类,根据路由请求在路由视图中动态渲染选中的组件<router-link>:请求链接组件,浏览器会解析成<a><router-view>:动态视图组件,用来渲染展示与路由路径对应的组件
E. 打包部署 nginx官网
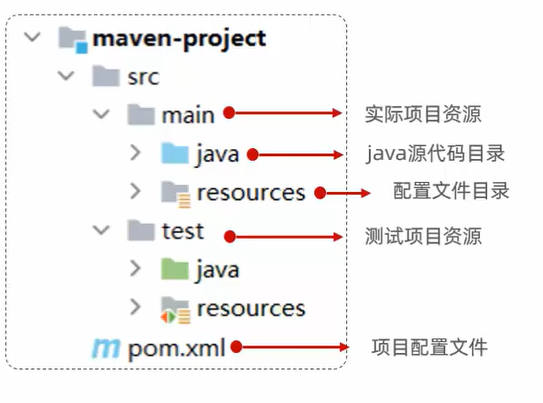
二. Maven 是管理和构建java项目的工具Maven官网
1. Maven介绍
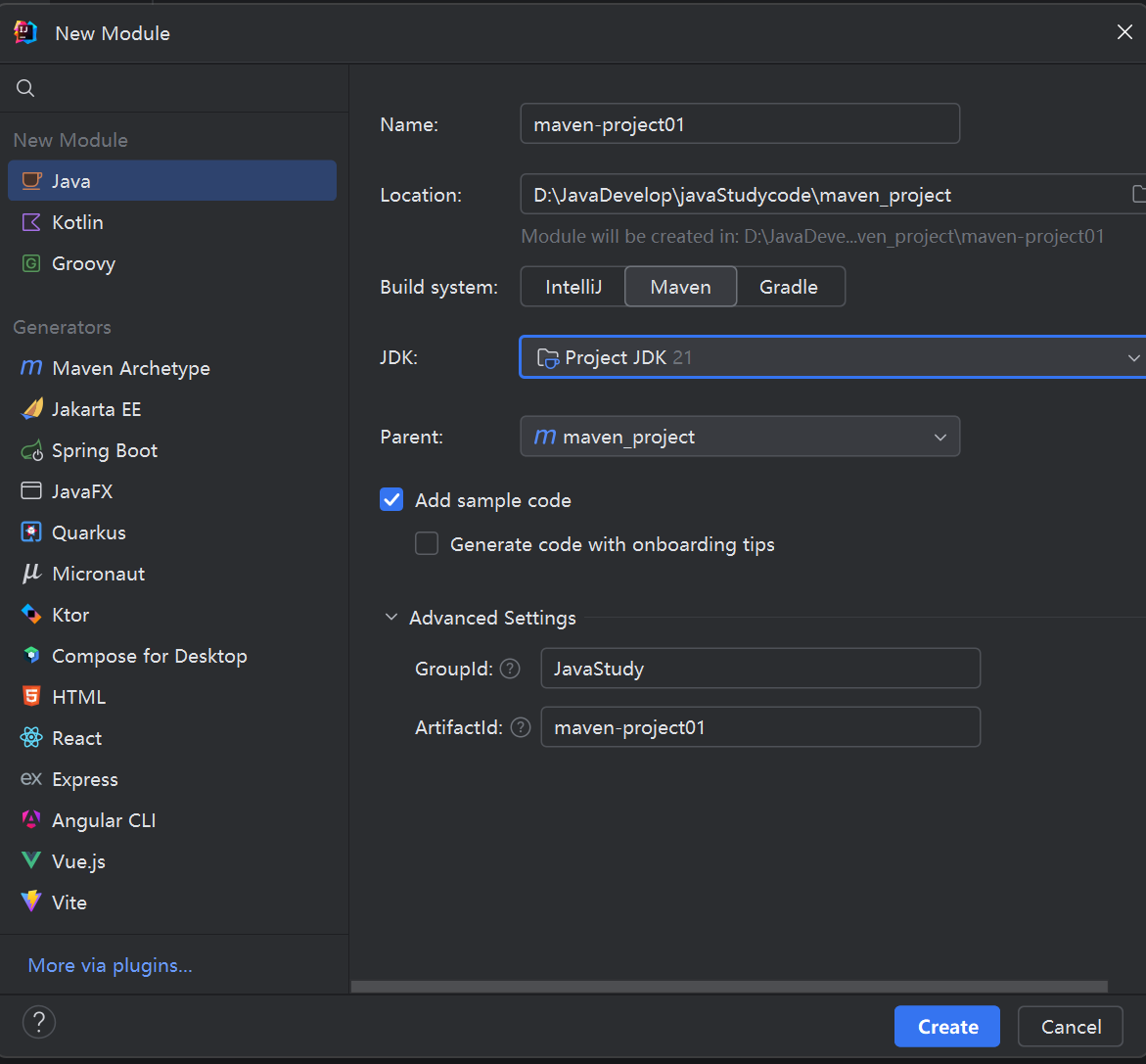
2. 在idea中创建Maven项目和导入Maven项目 创建
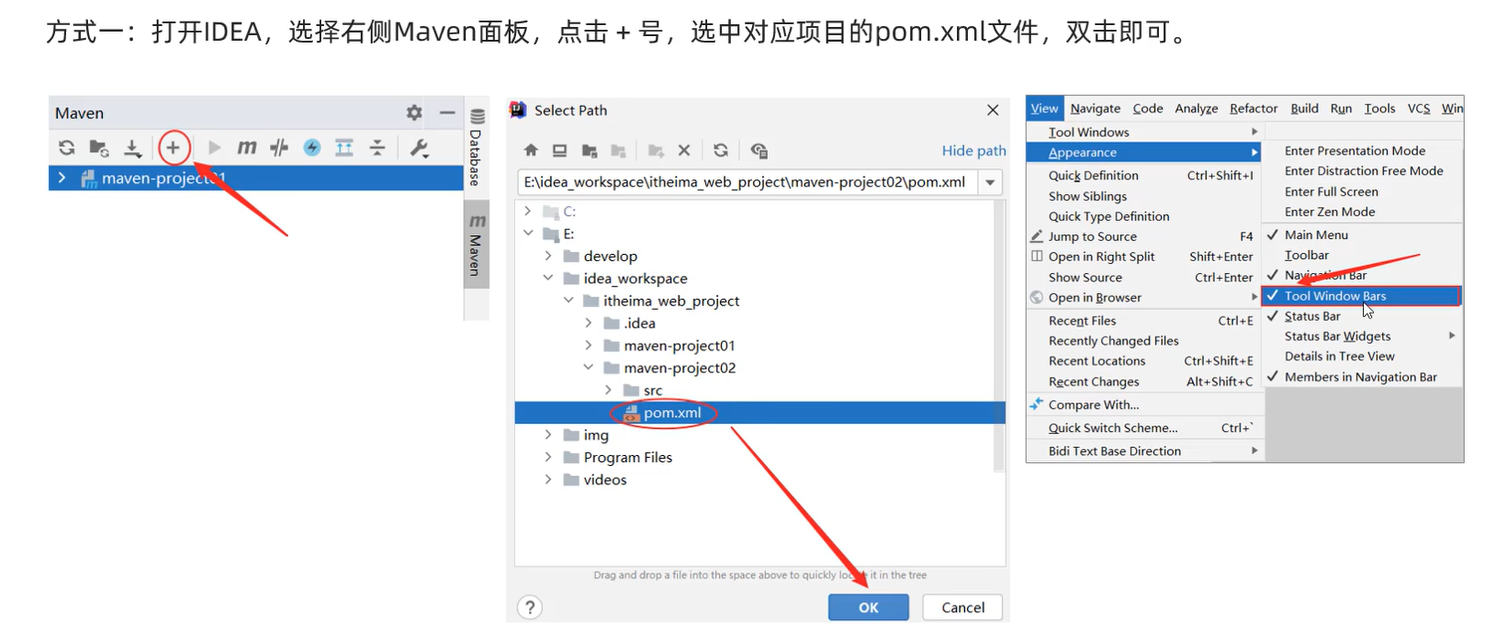
导入
3. 依赖管理 依赖:就指项目运行所需要的jar包,一个项目可以引入多个依赖
A. 依赖配置(导入jar包)
在pom.xml中编写<dependencies>标签
在<dependencies>标签中 使用<dependency>引入坐标
定义坐标的 groupld,artifactld, version
点击刷新按钮,引入最新加入的坐标
1 2 3 4 5 6 7 <dependencies > <dependency > <groupId > junit</groupId > <artifactId > junit</artifactId > <version > 4.13.2</version > </dependency > </dependencies >
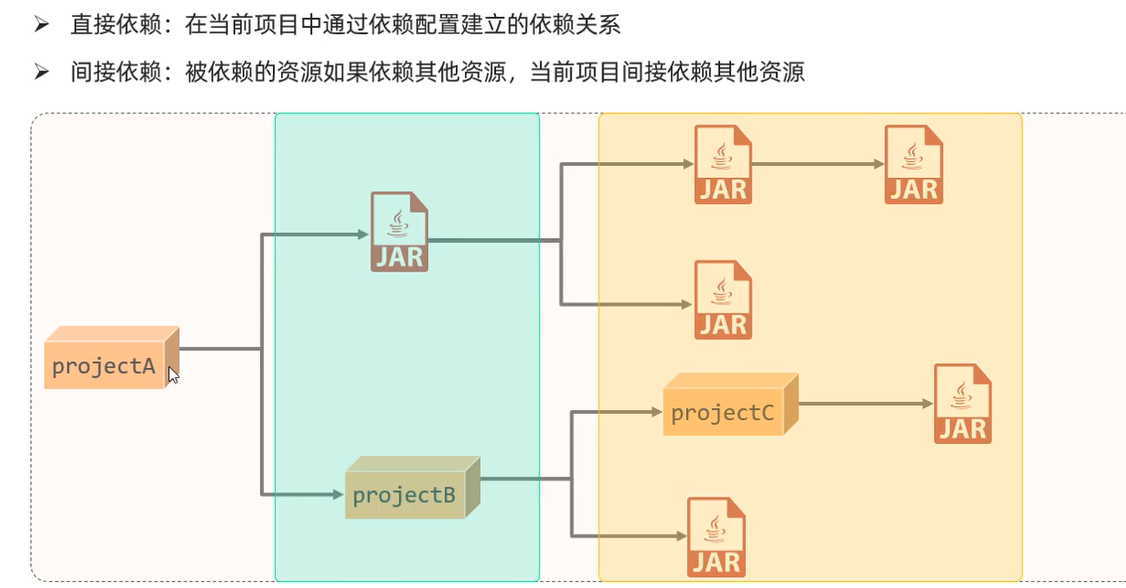
B. 依赖传递和排除依赖 依赖具有传递性
排除依赖 <exclusions></exclusions>标签
1 2 3 4 5 6 7 8 9 10 11 <dependency > <groupId > org.springframework</groupId > <artifactId > spring-web</artifactId > <version > 5.3.8</version > <exclusions > <exclusion > <groupId > org.springframework</groupId > <artifactId > spring-core</artifactId > </exclusion > </exclusions > </dependency >
C. 依赖范围 依赖的jar包,在默认情况下,可以在任何地方使用<scope></scope>设置其作用范围
scope值
主程序(main)
测试程序(test)
打包(运行)
示例
compile(默认)
Y
Y
Y
log4j
test
N
Y
N
junit
provided
Y
Y
N
servlet-api
runtime
N
Y
Y
jdbc驱动
D. 生命周期 Maven中有3套相互独立的生命周期:
clean:清理工作。
default:核心工作,如:编译、测试、打包、安装、部署等。
site:生成报告、发布站点等。
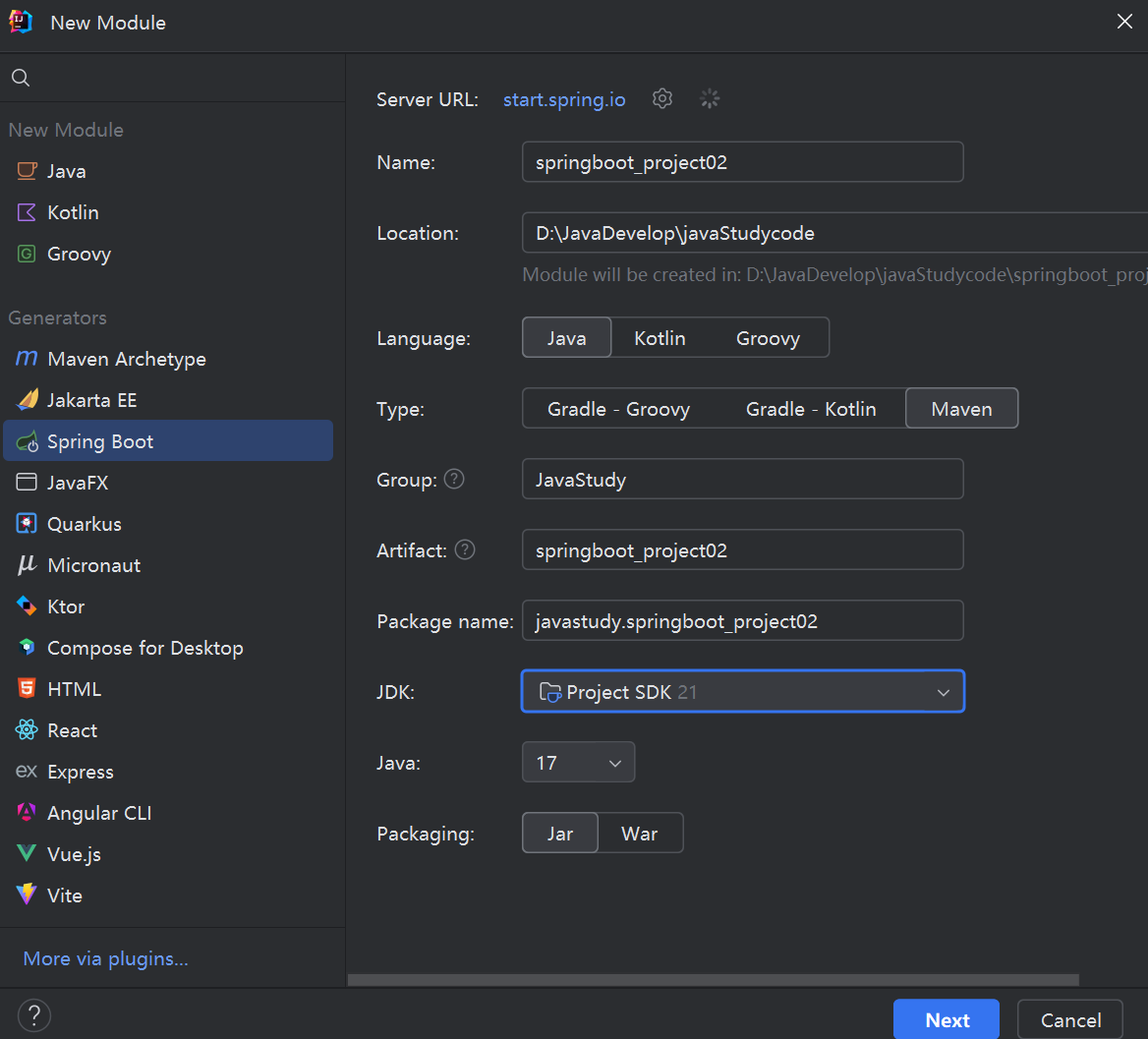
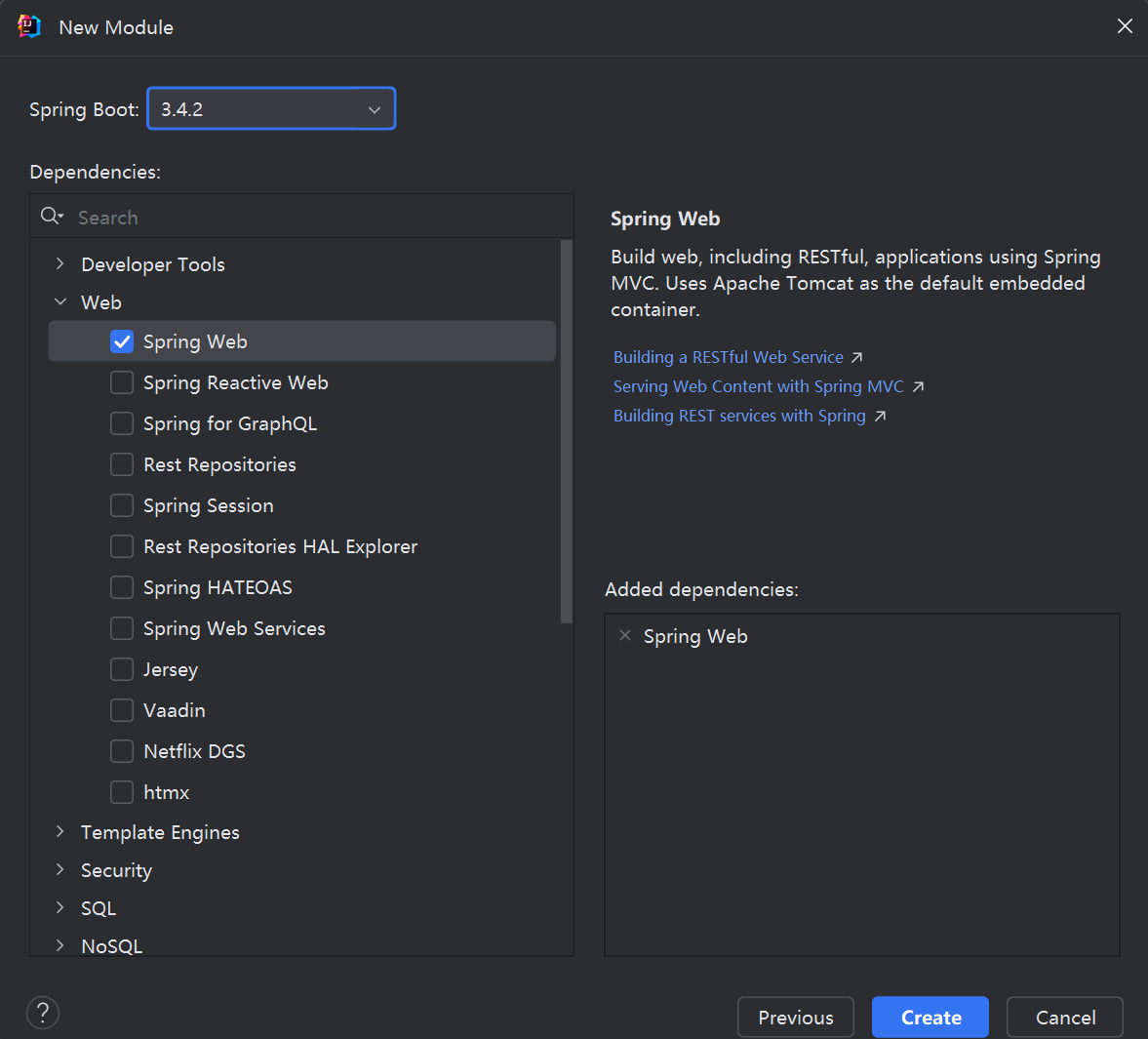
三. Web入门 1. SpringBootWeb入门
创建springboot工程,勾选spring web
创建请求处理类HelloController,添加请求处理方法hello,添加注释
1 2 3 4 5 6 7 8 @RestController public class HelloControll {@RequestMapping("/hello-world") public String hello () {"Hello World ~" );return "Hello World ~" ;
这里的启动类必须是请求处理类的父包
运行启动类,打开浏览器测试
2. HTTP协议 A. 介绍 Hyper Text Transfer Protocol(超文本传输协议)
基于TCP协议
基于请求-响应模型
是无状态的协议:每次请求-响应都是独立的
B. 请求协议
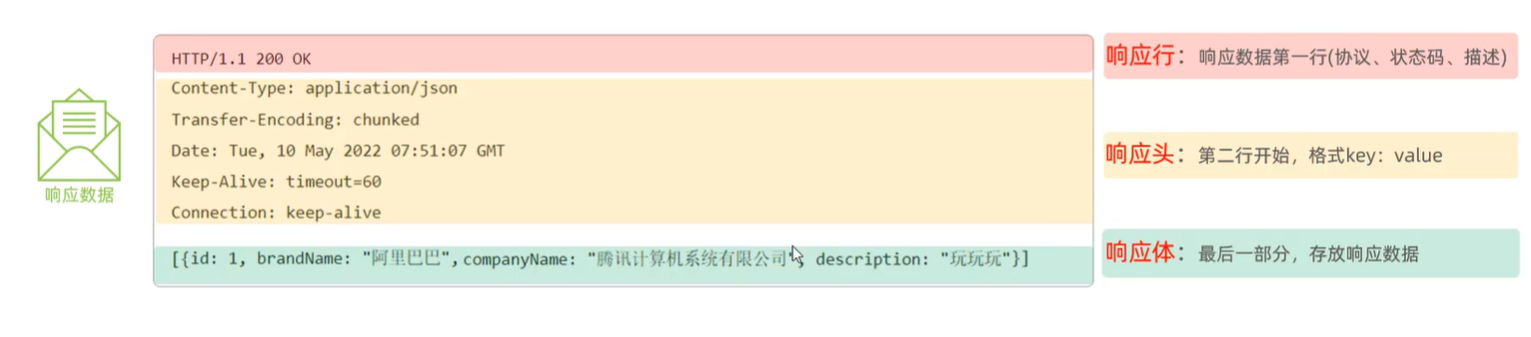
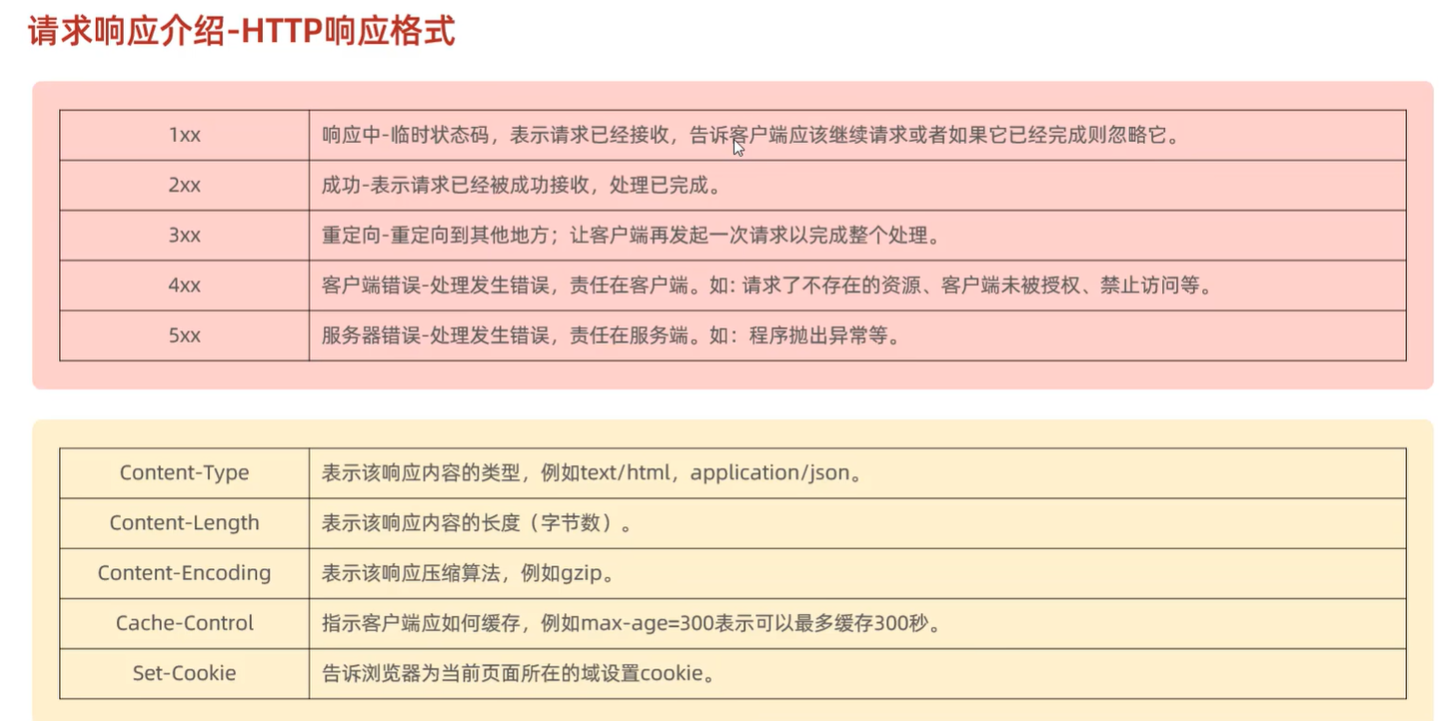
C. 响应协议
3. WEB服务器-Tomcat 一个轻量级的WEB服务器,是一个软件程序,对HTTP协议的操作进行封装,也称为web容器、servlet容器
4. 请求响应 A. 请求 1. 简单参数 SpringBoot方式:参数名与形参变量名相同,定义形参即可接收参数,会自动进行类型转换
1 2 3 4 5 @RequestMapping("/simpleParam") public String simpleParam (String name , Integer age) {" : " + age);return "OK" ;
@RequestParam注解
方法形参名称与请求参数名称不匹配,通过该注解完成映射
该注解的require属性默认是true,代表请求参数必须传递
2. 实体参数 简单实体对象 :请求参数名和形参对象属性名相同,定义POJO接收即可
1 2 3 4 5 @RequestMapping("/simplePojo") public String simplePojo (User user) {return "OK" ;
创建user类:
1 2 3 4 public class User {private String name;private Integer age;
postman中:GET: http://localhost:8080/simpleParam?name=abc&age=111
复杂实体对象 :请求参数名和形参对象属性名相同,按照对象层次结构关系即可接收嵌套POJO属性参数
1 2 3 4 5 6 7 8 9 10 public class User {private String name;private Integer age;private Address address;public class Address {private String province;private String city;
postman中:GET:http://localhost:8080/simpleParam?name=abc&age=111&address.province=北京&address.city=北京
3. 数组集合参数 数组参数 :请求参数名与形参数组名称相同且请求参数为多个,定义数组类型形参即可接收参数
1 2 3 4 5 @RequestMapping("/arrayParam") public String arrayParam (String[] hobby) {return "OK" ;
postman中:GET: http://localhost:8080/arrayParam?hobby=game&hobby=java
集合参数 :请求参数名与形参中数组变量名相同,通过@RequestParam绑定参数关系
1 2 3 4 5 @RequestMapping("/listParam") public String listParam (@RequestParam List<String> hobby) {return "OK" ;
postman中:GET: http://localhost:8080/listParam?hobby=game&hobby=java&hobby=sing
4. 日期参数 使用@DateTimeFormat注解完成日期参数格式转换
1 2 3 4 5 @RequestMapping("/dateParam") public String dateParam (@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss") LocalDateTime updateTime) {return "OK" ;
postman中:GET:http://localhost:8080/dateParam?updateTime=2025-1-1 13:14:05
5. json参数 JSON参数 :JSON数据键名与形参对象属性名相同,定义POJO类型形参即可接收参数,需要使用@RequestBody标识
1 2 3 4 5 @RequestMapping("/jsonParam") public String jsonParam (@RequestBody User user) {return "OK" ;
postman中:GET:http://localhost:8080/jsonParam
6. 路径参数 路径参数 :通过请求URL直接传递参数,使用{ .. }来标识该路径参数,需要使用@PathVariable获取路径参数
1 2 3 4 5 @RequestMapping("/path/{id}") public String pathParam (@PathVariable Integer id) {return "OK" ;
postman中:GET:http://localhost:8080/path/1
1 2 3 4 5 @RequestMapping("/path/{id}/{name}") public String pathParam2 (@PathVariable Integer id, @PathVariable String name) {" : " +name);return "OK" ;
postman中:GET:http://localhost:8080/path/1/abc
B. 响应 1. @ResponseBody
类型:方法注解、类注解
位置:Controller方法上/类上
作用:将方法返回值直接响应,如果返回值类型是实体对象/集合 ,将会转换为JSON格式 响应
说明:@RestController=@Controller+@ResponseBody;
2. 统一响应结果 Result(code,msg,data)
1 2 3 4 5 6 7 8 9 public class Result {private Integer code;private String msg;private Object data;
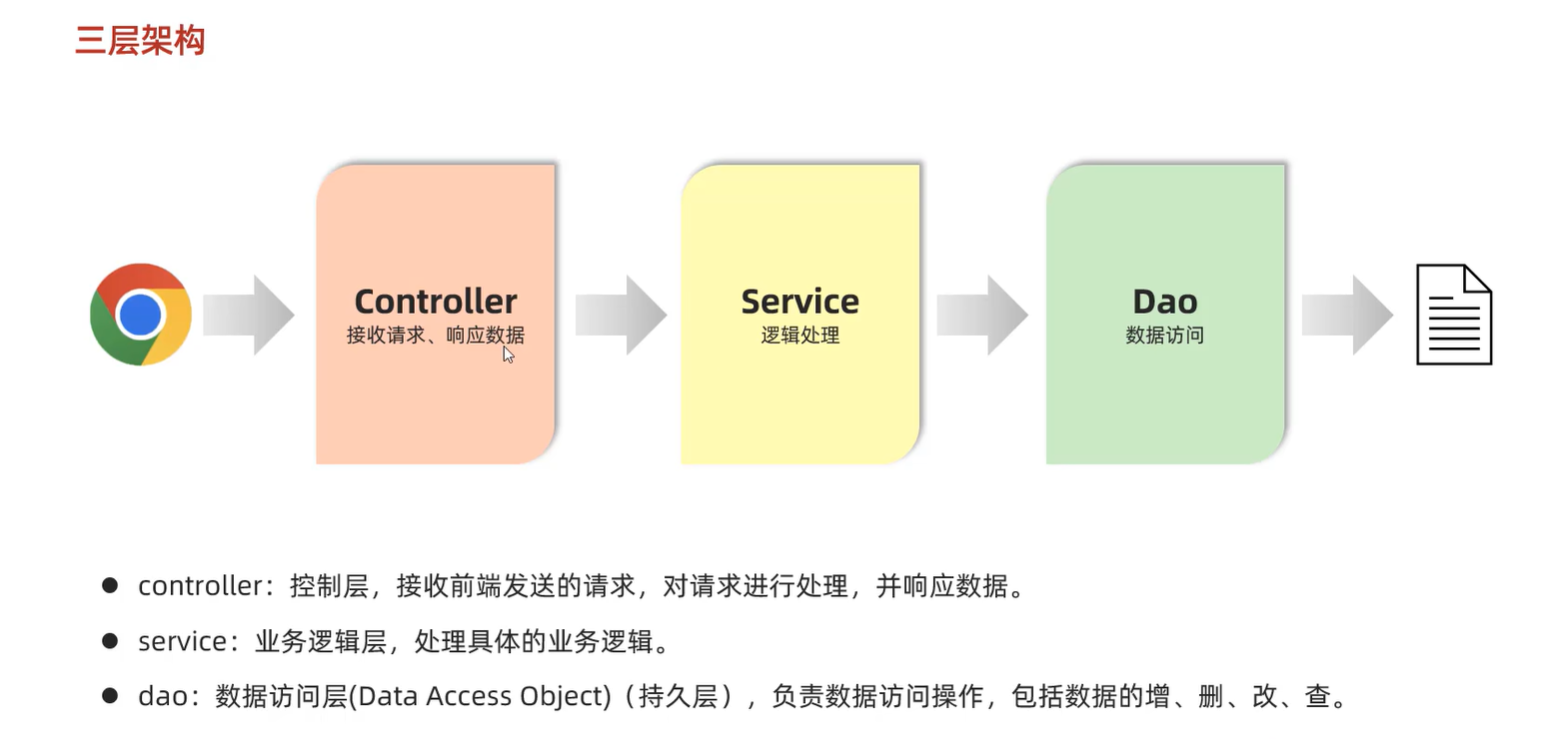
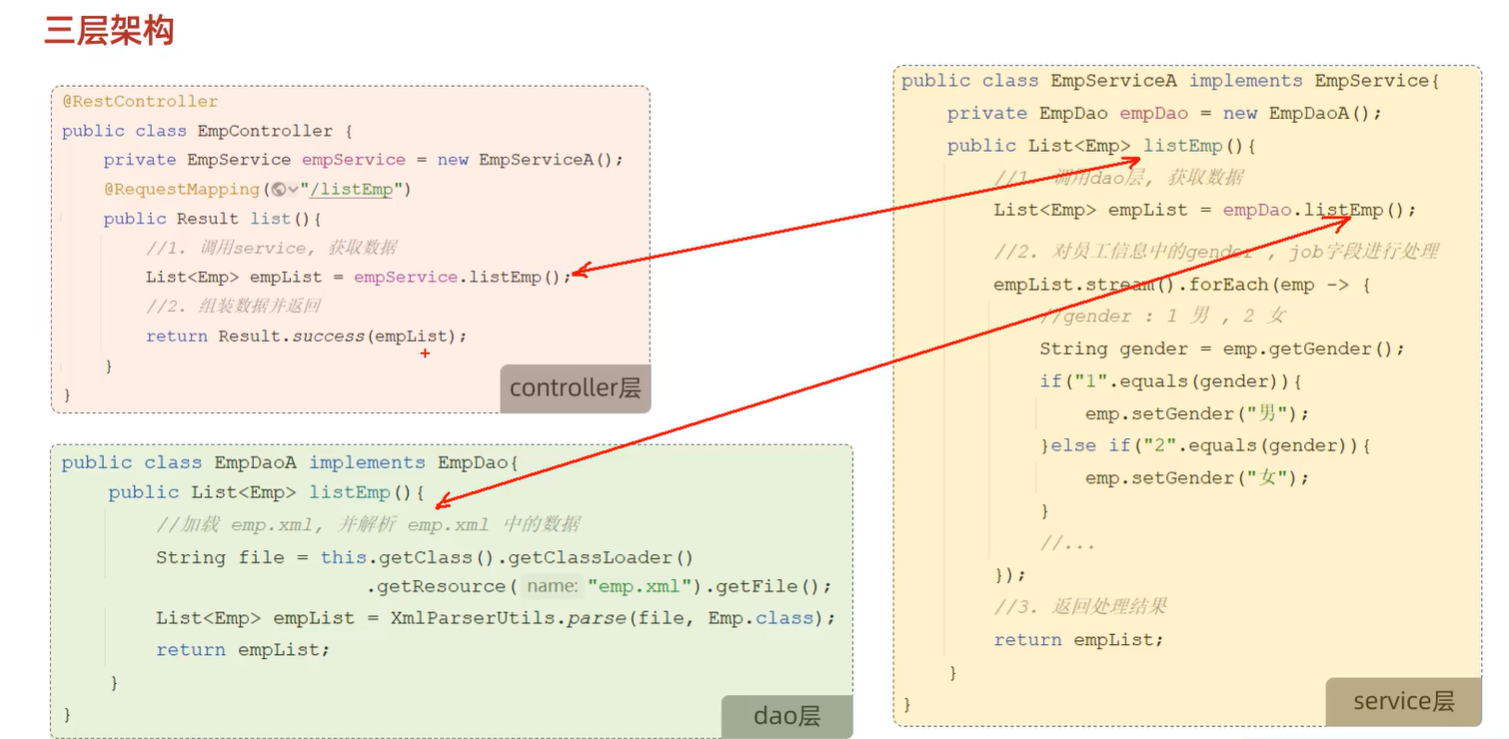
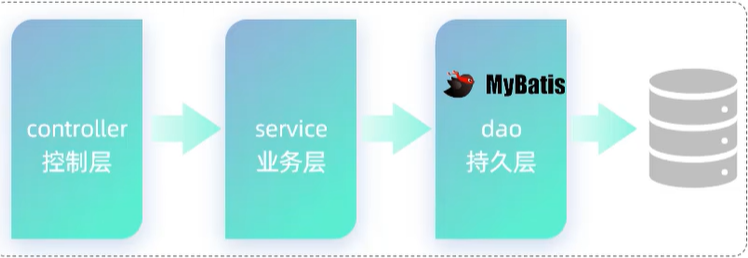
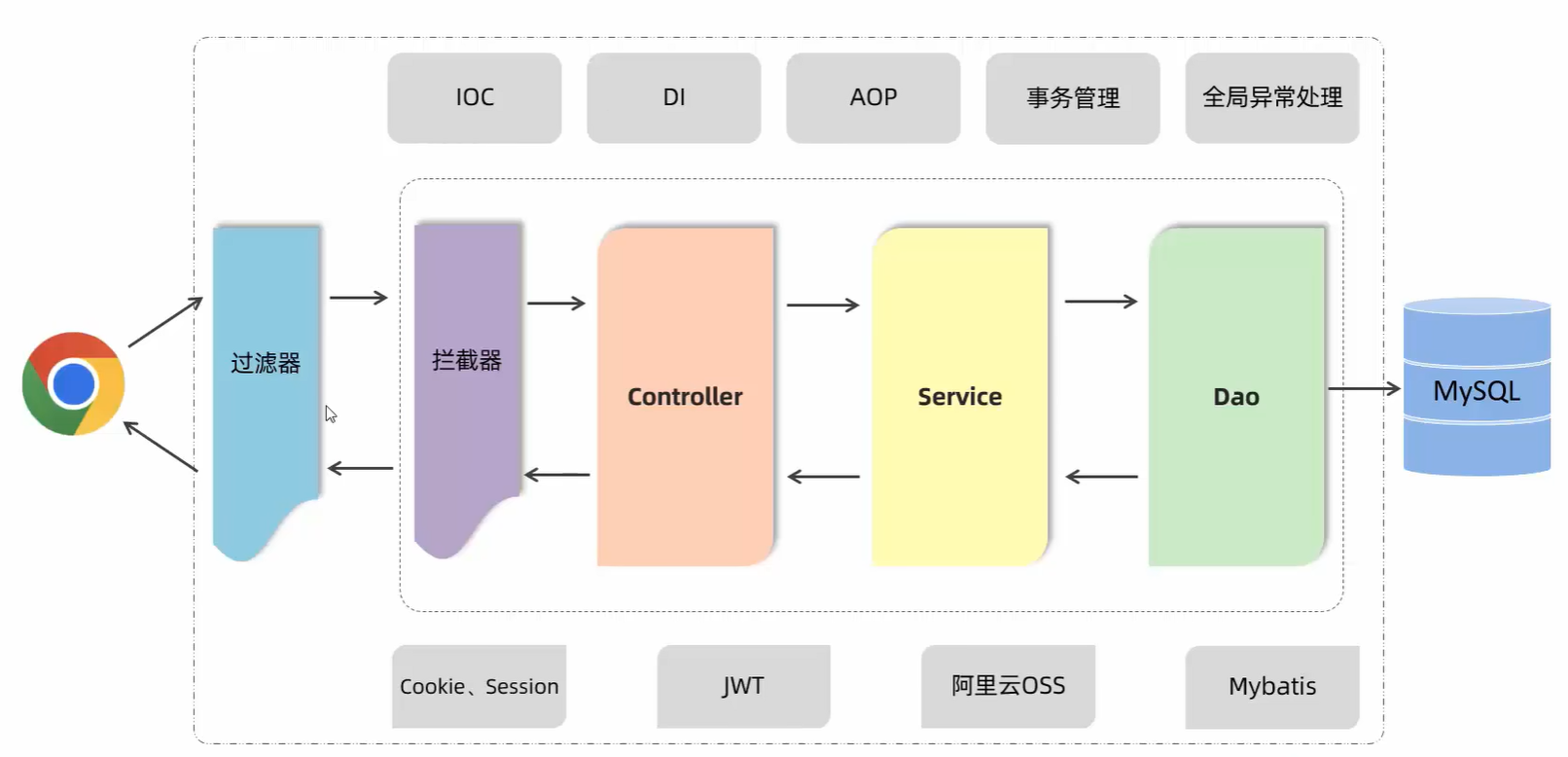
5. 分层解耦 别人的笔记
A. 三层架构
B. 解耦
内聚:软件中各个功能模块内部的功能联系。
耦合:衡量软件中各个层/模块之间的依赖、关联的程度。
高内聚低耦合
控制反转:Inversion Of Control,简称IOC。对象的创建控制权由程序自身转移到外部(容器) ,这种思想称为控制反转。
依赖注入:Dependency Injection,简称DI。容器为应用程序提供运行时,所依赖的资源 称之为依赖注入。
Bean对象:IOC容器中创建、管理的对象 ,称之为bean。
C. IOC控制反转 Bean的声明
注解
说明
位置
@Component
声明bean的基础注解
不属于以下三类时,用此注解
@Controller
@Component的衍生注解
标注在控制器类上
@Service
@Component的衍生注解
标注在业务类上
@Repository
@Component的衍生注解
标注在数据访问类上(由于与mybatis整合,用的少)
注意事项:
声明bean的时候,可以通过value属性指定bean的名字,如果没有指定,默认为类名首字母小写。
使用以上四个注解都可以声明bean,但是在springboot集成web开发中,声明控制器bean只能用@Controller。
@SpringBootApplication具有包扫描作用,默认扫描当前包及其子包
D. DI依赖注入
@Autowired:默认按照类型自动装配。
如果同类型的bean存在多个:
@Primary
@Autowired+@Qualifier(“bean的名称”)
@Resource(name=”bean的名称”)
@Resource 与 @Autowired区别
@Autowired 是spring框架提供的注解,而@Resource是JDK提供的注解。
@Autowired 默认是按照类型注入,而@Resource默认是按照名称注入。
四. MySQL数据库 1. 数据库概述 A. 数据库介绍
数据库:DataBase(DB),是存储和管理数据的仓库
数据库管理系统:DataBase Management System(DBMS),操纵和管理数据库的大型软件。
SQL: Structured Query Language,操作关系型数据库的编程语言,定义了一套操作关系型数据库统一标准。
mysql启动:net start mysqlnet stop mysqlmysql -u用户名 -p密码 /mysql -h数据库服务器IP地址 -P端口号mysql -uroot -p123456 / mysql -h192.168.150.101 -P3306 -uroot -p123456
B. MySQL数据模型和SQL简介 1. MySQL数据模型 关系型数据库:建立在关系模型基础上,由多张相互连接的二维表 组成的数据库
2. SQL简介
SQL语句可以单行或多行书写,以分号 结尾。
SQL语句可以使用空格/缩进来增强语句的可读性。
MySQL数据库的SQL语句不区分大小写 。
注释:-- 注释内容或#注释内容(MySQL特有)
分类
全称
说明
DDL
Data Definition Language
数据定义语言,用来定义数据库对象(数据库,表,字段)
DML
Data Manipulation Language
数据操作语言,用来对数据库表中的数据进行增删改
DQL
Data Query Language
数据查询语言,用来查询数据库中表的记录
DCL
Data Control Language
数据控制语言,用来创建数据库用户、控制数据库的访问权限
2. DDL语句 数据定义语言
A. 操作数据库
查询所有数据库:show databases;
查询当前数据库:select database();
使用数据库:use 数据库名;
创建数据库:create database [if not exists] 数据库名;
删除数据库:drop database[if exists] 数据库名;
B. 表操作-创建 1 2 3 4 5 create table 表名(1 字段类型[约束][comment 字段1 注释],
示例:
1 2 3 4 5 6 7 8 create table tb_userint comment 'ID,唯一标识' ,varchar (20 ) comment '用户名' ,varchar (10 ) comment '姓名' ,int comment '年龄' ,char (1 ) comment '性别' '用户表' ;
C. 约束
概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据。
目的:保证数据库中数据的正确性、有效性和完整性。
约束
描述
关键字
非空约束
限制该字段值不能为null
not null
唯一约束
保证字段的所有数据都是唯一、不重复的
unique
主键约束
主键是一行数据的唯一标识,要求非空且唯一
primary key
默认约束
保存数据时,如果未指定该字段值,则采用默认值
default
外键约束
让两张表的数据建立连接,保证数据的一致性和完整性
foreign key
1 2 3 4 5 6 7 8 create table tb_userint primary key comment 'ID,唯一标识' ,varchar (20 ) not null unique comment '用户名' ,varchar (10 ) not null comment '姓名' ,int comment '年龄' ,char (1 ) default '男' comment '性别' '用户表' ;
D. 数据类型 三大类数据类型:数值类型,字符串类型,日期类型
数值类型
类型
描述
存储大小
取值范围
TINYINT小整数
1字节
-128 到 127(有符号) / 0 到 255(无符号)
SMALLINT较小的整数
2字节
-32,768 到 32,767(有符号) / 0 到 65,535(无符号)
MEDIUMINT中等大小的整数
3字节
-8,388,608 到 8,388,607(有符号) / 0 到 16,777,215(无符号)
INT标准整数
4字节
-2,147,483,648 到 2,147,483,647(有符号) / 0 到 4,294,967,295(无符号)
BIGINT大整数
8字节
-9,223,372,036,854,775,808 到 9,223,372,036,854,775,807(有符号) / 0 到 18,446,744,073,709,551,615(无符号)
FLOAT单精度浮动点数
4字节
-3.402823466E+38 到 3.402823466E+38(可选精度)
DOUBLE双精度浮动点数
8字节
-1.7976931348623157E+308 到 1.7976931348623157E+308
DECIMAL精确的定点数(用于高精度运算)
根据定义大小
精确存储数字,指定精度和小数位数,例如 DECIMAL(10,2)
日期和时间类型
类型
描述
存储大小
取值范围
DATE存储日期(年-月-日)
3字节
‘1000-01-01’ 到 ‘9999-12-31’
TIME存储时间(时:分:秒)
3字节
‘-838:59:59’ 到 ‘838:59:59’
DATETIME存储日期和时间(年-月-日 时:分:秒)
8字节
‘1000-01-01 00:00:00’ 到 ‘9999-12-31 23:59:59’
TIMESTAMP存储日期和时间,自动记录插入/更新时的时间
4字节
‘1970-01-01 00:00:01’ 到 ‘2038-01-19 03:14:07’
YEAR存储年份(四位数)
1字节
1901 到 2155
字符串类型
类型
描述
存储大小
取值范围
CHAR(n)固定长度字符串
n 字节(固定长度)
存储 n 个字符(最大 255)
VARCHAR(n)可变长度字符串
n 字节(实际长度)
存储 n 个字符(最大 65,535)
TEXT长文本(适用于较大的文本数据)
2 字节 + 数据长度
最大 65,535 个字符
TINYTEXT极小文本(适用于较小的文本数据)
1 字节 + 数据长度
最大 255 个字符
MEDIUMTEXT中等大小文本
3 字节 + 数据长度
最大 16,777,215 个字符
LONGTEXT超大文本
4 字节 + 数据长度
最大 4,294,967,295 个字符
BLOB二进制大对象(用于存储二进制数据,如图片)
2 字节 + 数据长度
最大 65,535 字节(与 TEXT 类似)
TINYBLOB极小二进制对象
1 字节 + 数据长度
最大 255 字节
MEDIUMBLOB中等大小二进制对象
3 字节 + 数据长度
最大 16,777,215 字节
LONGBLOB超大二进制对象
4 字节 + 数据长度
最大 4,294,967,295 字节
E. 表结构-查询修改删除 一般都是用图形化页面工具查询
查询当前数据库所有表:show tables;
查询表结构:desc 表名;
查询建表语句:show create table 表名;
修改
添加字段:alter table 表名 add 字段名 类型(长度)[comment 注释][约束];
修改字段类型:alter table 表名 modify 字段名 新数据类型(长度);
修改字段名和字段类型:alter table 表名 change 旧字段名 新字段名 类型(长度)[comment注释][约束];
删除字段:alter table 表名 drop column 字段名;
修改表名:rename table 表名 to 新表名;
删除 drop table [if exists] 表名;
3. DML语句 数据操作语言,用来对数据库中表的数据记录进行增删改操作INSERT,修改UPDATE,删除DELETE
A. 添加-INSERT
指定字段添加数据:insert into 表名(字段名1,字段名2)values(值1,值2);
全部字段添加数据:insert into 表名 values(值1,值2,…);
批量添加数据(指定字段):insert into 表名(字段名1,字段名2)values(值1,值2),(值1,值2);
批量添加数据(全部字段):insert into 表名 values(值1,值2,…),(值1,值2, …. );
1 2 3 4 5 6 7 8 9 10 insert into tb_emp(username, name, gender, create_time, update_time) values ('wuji' , '张无忌' , 1 , now(), now());insert into tb_emp(id, username, password, name, gender, image, job, entrydate, create_time, update_time)values (null , 'zhirou' , '123' , '周芷若' , 2 , '1.jpg' , 1 , '2010-01-01' , now(), now());insert into tb_emp(username, name, gender, create_time, update_time)values ('weifuwang' , '韦一笑' , 1 , now(), now()),'fengzi' , '张三疯' , 1 , now(), now());
B. 修改-UPDATE 语法:update 表名 set 字段名1 = 值1 , 字段名2 = 值2 , .... [where 条件];
1 2 3 4 update tb_emp set name= '张三' ,update_time= now() where id= 1 ;update tb_emp set entrydate= '2010-01-01' ,update_time= now();
修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表的所有数据。
C. 删除-DELETE 语法:delete from 表名 [where 条件];
1 2 3 4 delete from tb_emp where id = 1 ;delete from tb_emp;
4. DQL语句 数据查询语言,用于查询数据库表中的记录
A. 语法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 SELECT FROM WHERE GROUP BY HAVING ORDER BY
B. 基本查询
1 select 字段1 , 字段2 , 字段3 from 表名;
1 select 字段1 [ as 别名1 ] , 字段2 [ as 别名2 ] from 表名;
1 select distinct 字段列表 from 表名;
案例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 select name,entrydate from tb_emp;select * from tb_emp;select name AS 姓名, entrydate AS 入职日期 from tb_emp;select name AS '姓 名' , entrydate AS '入职日期' from tb_emp;select name AS "姓名", entrydate AS "入职日期" from tb_emp;select distinct job from tb_emp;
C. 条件查询 语法:
1 select 字段列表 from 表名 where 条件列表 ;
比较运算符
功能
>
大于
>=
大于等于
<
小于
<=
小于等于
=
等于
<> 或 !=
不等于
between … and …
在某个范围之内(含最小、最大值)
in(…)
在in之后的列表中的值,多选一
like 占位符
模糊匹配(_匹配单个字符, %匹配任意个字符)
is null
是null
逻辑运算符
功能
and 或 &&
并且 (多个条件同时成立)
or 或
或者 (多个条件任意一个成立)
not 或 !
非 , 不是
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 select id, username, password, name, gender, image, job, entrydate, create_time, update_timefrom tb_empwhere name = '杨逍' ;select id, username, password, name, gender, image, job, entrydate, create_time, update_timefrom tb_empwhere id <= 5 ;select id, username, password, name, gender, image, job, entrydate, create_time, update_timefrom tb_empwhere job is null ;select id, username, password, name, gender, image, job, entrydate, create_time, update_timefrom tb_empwhere password != '123456' ;select id, username, password, name, gender, image, job, entrydate, create_time, update_timefrom tb_empwhere entrydate>= '2000-01-01' and entrydate<= '2010-01-01' ;select id, username, password, name, gender, image, job, entrydate, create_time, update_timefrom tb_empwhere entrydate between '2000-01-01' and '2010-01-01' ;select id, username, password, name, gender, image, job, entrydate, create_time, update_timefrom tb_empwhere job= 2 or job= 3 or job= 4 ;select id, username, password, name, gender, image, job, entrydate, create_time, update_timefrom tb_empwhere job in (2 ,3 ,4 );select id, username, password, name, gender, image, job, entrydate, create_time, update_timefrom tb_empwhere name like '__' ; select id, username, password, name, gender, image, job, entrydate, create_time, update_timefrom tb_empwhere name like '张%' ;
D. 聚合函数 之前我们做的查询都是横向查询,就是根据条件一行一行的进行判断,而使用聚合函数查询就是纵向查询,它是对一列的值进行计算,然后返回一个结果值。(将一列数据作为一个整体,进行纵向计算)
1 select 聚合函数(字段列表) from 表名 ;
聚合函数
功能
count
统计数量,按照列去统计有多少行的数据
max
最大值,计算指定列的最大值
min
最小值,计算指定列的最小值
avg
平均值,计算指定列的平均值
sum
求和,计算指定列的数值和,如果不是数值类型,那么计算结果为0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 select count (id) from tb_emp;select count (job) from tb_emp;select count (0 ) from tb_emp;select count ('A' ) from tb_emp;select count (* ) from tb_emp;select min (entrydate) from tb_emp;select max (entrydate) from tb_emp;select avg (id) from tb_emp;select sum (id) from tb_emp;
E. 分组查询
分组其实就是按列进行分类(指定列下相同的数据归为一类),然后可以对分类完的数据进行合并计算。
分组查询通常会使用聚合函数进行计算。
1 select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];
1 2 3 4 5 6 7 8 9 10 11 select gender, count (* )from tb_empgroup by gender; select job, count (* )from tb_empwhere entrydate <= '2015-01-01' group by job having count (* ) >= 2 ;
where与having区别(面试题)
执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
判断条件不同:where不能对聚合函数进行判断,而having可以。
执行顺序:where > 聚合函数 > having
F. 排序查询 有升序排序,也有降序排序。
1 2 3 4 5 select 字段列表 from 表名 where 条件列表] group by 分组字段] order by 字段1 排序方式1 , 字段2 排序方式2 … ;
排序方式:
1 2 3 4 select id, username, password, name, gender, image, job, entrydate, create_time, update_timefrom tb_emporder by entrydate ASC , update_time DESC ;
G. 分页查询 1 select 字段列表 from 表名 limit 起始索引, 查询记录数 ;
1 2 3 4 5 6 7 8 9 select id, username, password, name, gender, image, job, entrydate, create_time, update_timefrom tb_emp0 , 5 ; select id, username, password, name, gender, image, job, entrydate, create_time, update_timefrom tb_emp10 , 5 ;
注意事项:
5. 多表设计 一对多(多对一),多对多,一对一
A. 一对多 1. 设计多表 创建部门表和员工表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 create database db03;create table tb_deptint unsigned primary key auto_increment comment '主键ID' ,varchar (10 ) not null unique comment '部门名称' ,not null comment '创建时间' ,not null comment '修改时间' '部门表' ;create table tb_empint unsigned primary key auto_increment comment 'ID' ,varchar (20 ) not null unique comment '用户名' ,varchar (32 ) default '123456' comment '密码' ,varchar (10 ) not null comment '姓名' ,not null comment '性别, 说明: 1 男, 2 女' ,varchar (300 ) comment '图像' ,'职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管' ,date comment '入职时间' ,int unsigned comment '部门ID' , not null comment '创建时间' ,not null comment '修改时间' '员工表' ;
一对多关系实现:在数据库表中多的一方,添加字段,来关联属于一这方的主键。
2. 外键约束
让两张表的数据建立连接,保证数据的一致性和完整性 。
对应的关键字:foreign key
语法
1 2 3 4 5 6 7 8 9 create table 表名(constraint ] [外键名称] foreign key (外键字段名) references 主表 (主表列名) alter table 表名 add constraint 外键名称 foreign key (外键字段名) references 主表(主表列名);
通过SQL语句操作,为员工表的dept_id 建立外键约束,来关联部门表的主键。
1 2 3 alter table tb_emp add constraint fk_dept_id foreign key (dept_id) references tb_dept(id);
3. 物理外键和逻辑外键 物理外键概念:使用foreign key定义外键关联另外一张表。
影响增、删、改的效率(需要检查外键关系)。
仅用于单节点数据库,不适用与分布式、集群场景。
容易引发数据库的死锁问题,消耗性能。
逻辑外键概念:在业务层逻辑中,解决外键关联。
在现在的企业开发中,很少会使用物理外键,都是使用逻辑外键。 甚至在一些数据库开发规范中,会明确指出禁止使用物理外键 foreign key
B. 一对一 在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 create table tb_user(int unsigned primary key auto_increment comment 'ID' ,varchar (10 ) not null comment '姓名' ,not null comment '性别, 1 男 2 女' ,char (11 ) comment '手机号' ,varchar (10 ) comment '学历' '用户基本信息表' ;create table tb_user_card(int unsigned primary key auto_increment comment 'ID' ,varchar (10 ) not null comment '民族' ,date not null comment '生日' ,char (18 ) not null comment '身份证号' ,varchar (20 ) not null comment '签发机关' ,date not null comment '有效期限-开始' ,date comment '有效期限-结束' ,int unsigned not null unique comment '用户ID' ,constraint fk_user_id foreign key (user_id) references tb_user(id)'用户身份信息表' ;
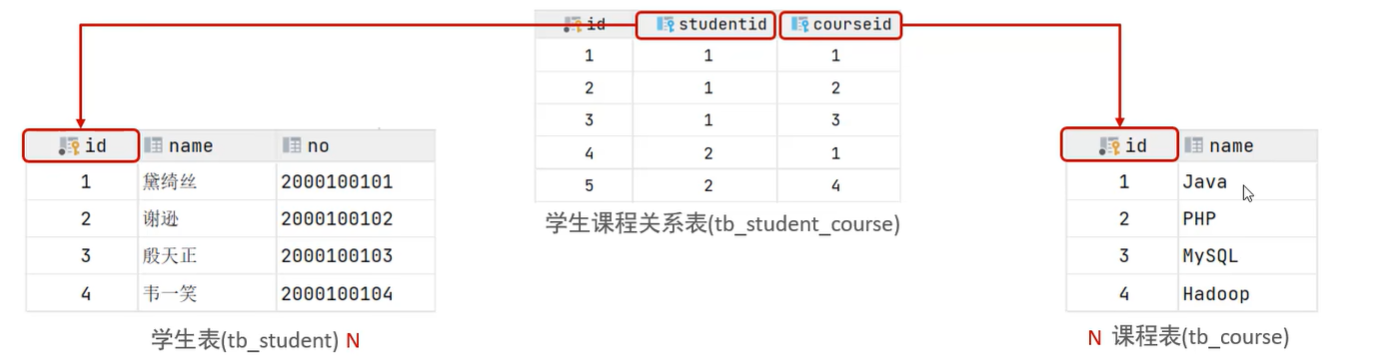
C. 多对多
学生和老师的关系,一个学生可以有多个授课老师,一个授课老师也可以有多个学生。
学生和课程的关系,一个学生可以选修多门课程,一个课程也可以供多个学生选修。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 create table tb_student(int auto_increment primary key comment '主键ID' ,varchar (10 ) comment '姓名' ,no varchar (10 ) comment '学号' '学生表' ;create table tb_course(int auto_increment primary key comment '主键ID' ,varchar (10 ) comment '课程名称' '课程表' ;create table tb_student_course(int auto_increment comment '主键' primary key ,int not null comment '学生ID' ,int not null comment '课程ID' ,constraint fk_courseid foreign key (course_id) references tb_course (id),constraint fk_studentid foreign key (student_id) references tb_student (id)'学生课程中间表' ;
6. 多表查询 指从多张表中查询数据
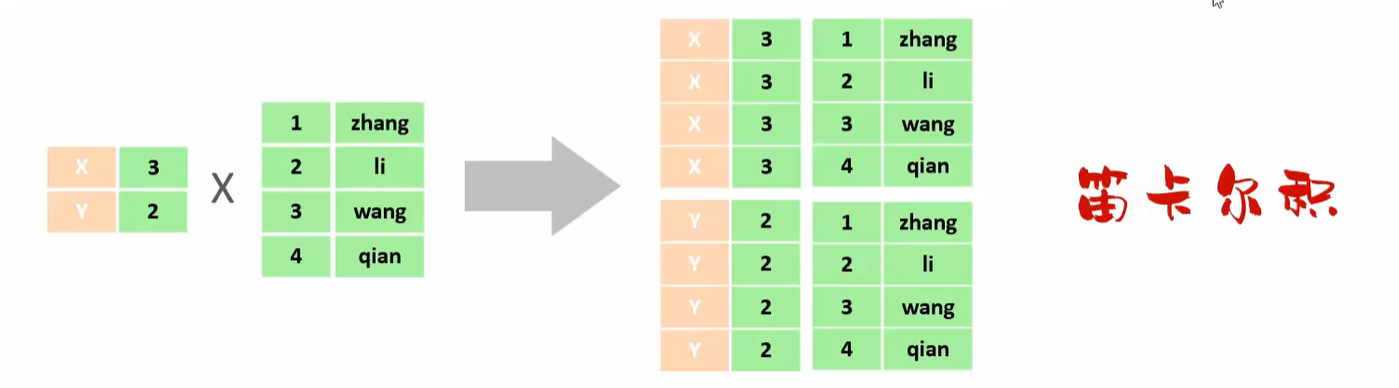
A. 笛卡尔积
B. 内连接查询 查询两表或多表中交集部分数据,分为隐式内连接和显式内连接
1 select 字段列表 from 表1 , 表2 where 条件 ... ;
1 select 字段列表 from 表1 [ inner ] join 表2 on 连接条件 ... ;
查询员工的姓名及所属的部门名称
1 2 3 4 5 6 7 8 9 select tb_emp.name , tb_dept.name from tb_emp , tb_dept where tb_emp.dept_id = tb_dept.id; select tb_emp.name , tb_dept.namefrom tb_emp inner join tb_depton tb_emp.dept_id = tb_dept.id;
C. 多表查询时给表起别名 tableA as 别名1 , tableB as 别名2 ;tableA 别名1 , tableB 别名2 ;
1 2 3 select emp.name , dept.namefrom tb_emp emp inner join tb_dept depton emp.dept_id = dept.id;
D. 外连接查询 外连接分为两种:左外连接 和 右外连接
左外连接相当于查询表1(左表)的所有数据,包含表1和表2交集部分
右外连接相当于查询表2(右表)的所有数据,包含表1和表2交集部分
左外连接语法
1 select 字段列表 from 表1 left [ outer ] join 表2 on 连接条件 ... ;
右外连接语法
1 select 字段列表 from 表1 right [ outer ] join 表2 on 连接条件 ... ;
案例:
1 2 3 4 5 6 7 8 9 10 11 12 select emp.name , dept.namefrom tb_emp AS emp left join tb_dept AS dept on emp.dept_id = dept.id;select dept.name , emp.namefrom tb_emp AS emp right join tb_dept AS depton emp.dept_id = dept.id;
E. 子查询(嵌套查询) 1 SELECT * FROM t1 WHERE column1 = (SELECT column1 FROM t2 ... );
分为
标量子查询(子查询结果为单个值[一行一列])
列子查询(子查询结果为一列,但可以是多行)
行子查询(子查询结果为一行,但可以是多列)
表子查询(子查询结果为多行多列[相当于子查询结果是一张表])
子查询可以书写的位置:where之后,from之后,select之后
1. 标量子查询 子查询返回的结果是单个值(数字、字符串、日期等)
1 2 3 4 5 6 7 select id from tb_dept where name = '教研部' ; select * from tb_emp where dept_id = 2 ;select * from tb_emp where dept_id = (select id from tb_dept where name = '教研部' );
2. 列子查询 子查询返回的结果是一列(可以是多行)
操作符
描述
IN
在指定的集合范围之内,多选一
NOT IN
不在指定的集合范围之内
1 2 3 4 5 6 7 select id from tb_dept where name = '教研部' or name = '咨询部' ; select * from tb_emp where dept_id in (3 ,2 );select * from tb_emp where dept_id in (select id from tb_dept where name = '教研部' or name = '咨询部' );
3. 行子查询 子查询返回的结果是一行(可以是多行)= 、<> 、IN 、NOT IN
1 2 3 4 5 6 7 select entrydate , job from tb_emp where name = '韦一笑' ; select * from tb_emp where (entrydate,job) = ('2007-01-01' ,2 );select * from tb_emp where (entrydate,job) = (select entrydate , job from tb_emp where name = '韦一笑' );
4. 表子查询 子查询返回的结果是多行多列,常作为临时表
查询入职日期是 “2006-01-01” 之后的员工信息 , 及其部门信息
1 2 3 select * from emp where entrydate > '2006-01-01' ;select e.* , d.* from (select * from emp where entrydate > '2006-01-01' ) e left join dept d on e.dept_id = d.id ;
7. 事务 A. 事务的介绍 事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
事务作用:保证在一个事务中多次操作数据库表中数据时,要么全都成功,要么全都失败。
B. 事务的操作
SQL语句
描述
start transaction; / begin ;
开启手动控制事务
commit;
提交事务
rollback;
回滚事务
1 2 3 4 5 6 7 8 9 10 11 12 13 start transaction ;delete from tb_dept where id = 1 ;delete from tb_emp where dept_id = 1 ;commit ;rollback ;
C. 事务的四大特性(ACID)
原子性(Atomicity):事务是不可分割的最小单元,要么全部成功,要么全部失败。
一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
8. 索引 A. 索引的介绍 索引是帮助数据库高效获取数据的数据结构,使用索引可以提高查询的效率
优点:
提高数据查询的效率,降低数据库的IO成本。通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗。
缺点:
索引会占用存储空间。
索引大大提高了查询效率,同时却也降低了insert、update、delete的效率。
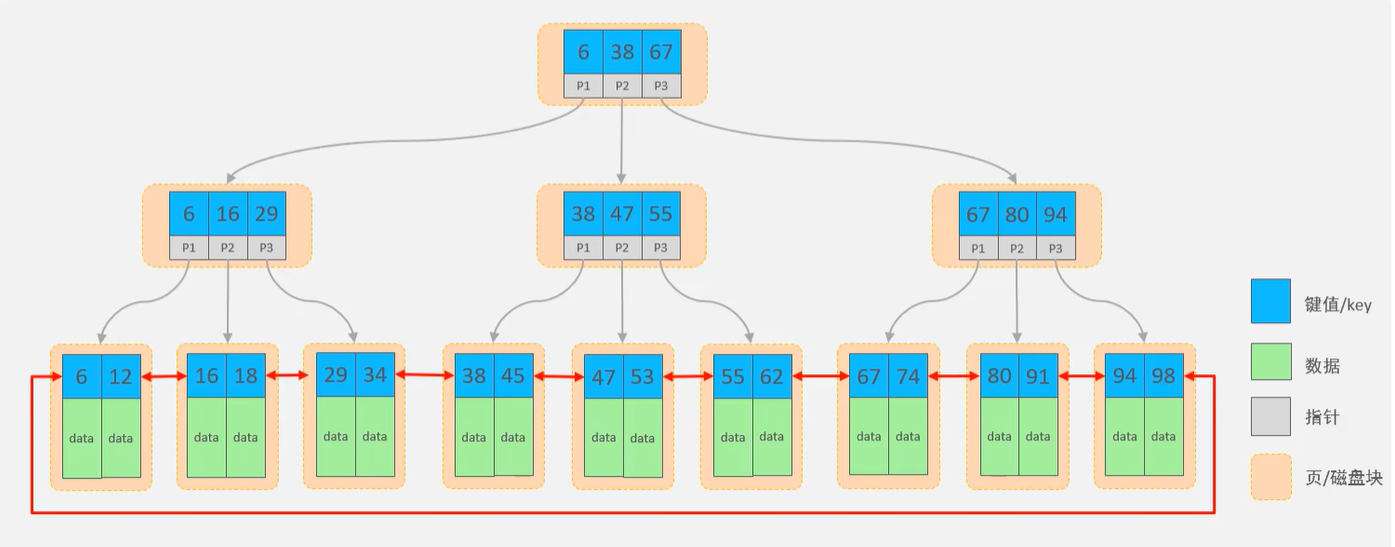
B. 索引的数据结构 MySQL中用B+树索引数据结构,B+Tree(多路平衡搜索树)
B+Tree结构:
每一个节点,可以存储多个key(有n个key,就有n个指针)
节点分为:叶子节点、非叶子节点
叶子节点,就是最后一层子节点,所有的数据都存储在叶子节点上
非叶子节点,不是树结构最下面的节点,用于索引数据,存储的的是:key+指针
为了提高范围查询效率,叶子节点形成了一个双向链表,便于数据的排序及区间范围查询
C. 语法
创建索引
1 create [ unique ] index 索引名 on 表名 (字段名,... ) ;
查看索引
删除索引
案例:
1 2 3 4 5 6 7 8 create index idx_emp_name on tb_emp(name);show index from tb_emp;drop index idx_emp_name on tb_emp;
五. MyBatis 1. MyBatis简介 MyBatis就是用Java程序操作数据库
application.properties
1 2 3 4 5 6 7 8 1234
Mapper接口(编写SQL语句)
1 2 3 4 5 @Mapper public interface UserMapper {@Select("select id, name, age, gender, phone from user") public List<User> list () ;
2. JDBC(了解) 就是使用Java语言操作关系型数据库的一套API
使用SpringBoot+Mybatis的方式操作数据库,能够提升开发效率、降低资源浪费
3. 数据库连接池 A. 数据库连接池介绍
数据库连接池是个容器,负责分配、管理数据库连接 (Connection)
允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个
释放空闲时间超过最大空闲时间的连接,来避免因为没有释放连接而引起的数据库连接遗漏
数据库连接池的好处:
B. 实现数据库连接池 官方(sun)提供了数据库连接池标准(javax.sql.DataSource接口)
1 public Connection getConnection () throws SQLException;
想把默认的数据库连接池切换为Druid数据库连接池
在pom.xml文件中引入依赖
1 2 3 4 5 6 <dependency > <groupId > com.alibaba</groupId > <artifactId > druid-spring-boot-starter</artifactId > <version > 1.2.8</version > </dependency >
在application.properties中引入数据库连接配置
1 2 3 4 spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver1234
4. lombok工具包 Lombok是一个实用的Java类库,可以通过简单的注解来简化和消除一些必须有但显得很臃肿的Java代码
注解
作用
@Getter/@Setter
为所有的属性提供get/set方法
@ToString
会给类自动生成易阅读的toString方法
@EqualsAndHashCode
根据类所拥有的非静态字段自动重写 equals 方法和 hashCode 方法
@Data 提供了更综合的生成代码功能(@Getter + @Setter + @ToString+@EqualsAndHashCode)
@NoArgsConstructo 为实体类生成无参的构造器方法
@AllArgsConstructor 为实体类生成除了static修饰的字段之外带有各参数的构造器方法
在pom.xml文件中引入依赖(lombok)
1 2 3 4 5 <dependency > <groupId > org.projectlombok</groupId > <artifactId > lombok</artifactId > </dependency >
5. Mybatis基础操作 A. 准备 准备工作
B. 删除 1. 功能实现 根据主键删除数据
接口方法
1 2 3 4 5 @Mapper public interface EmpMapper {@Delete("delete from emp where id = #{id}") public void delete (Integer id) ;
在单元测试类中通过@Autowired注解注入EmpMapper类型对象
1 2 3 4 5 6 7 8 9 10 11 @SpringBootTest class SpringbootMybatisCrudApplicationTests {@Autowired private EmpMapper empMapper;@Test public void testDel () {16 );
2. MyBatis的日志输出
打开application.properties文件
开启mybatis的日志,并指定输出到控制台mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
3. 预编译SQL
在项目开发中,建议使用#{},生成预编译SQL,防止SQL注入安全。
C. 新增 1. 功能实现
接口方法
1 2 3 4 5 6 7 @Mapper public interface EmpMapper {@Insert("insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) values (#{username}, #{name}, #{gender}, #{image}, #{job}, #{entrydate}, #{deptId}, #{createTime}, #{updateTime})") public void insert (Emp emp) ;
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @SpringBootTest class SpringbootMybatisCrudApplicationTests {@Autowired private EmpMapper empMapper;@Test public void testInsert () {Emp emp = new Emp ();"tom" );"汤姆" );"1.jpg" );short )1 );short )1 );2000 ,1 ,1 ));1 );
2. 主键返回 在数据添加成功后,需要获取插入数据库数据的主键Options注解
1 @Options(useGeneratedKeys = true,keyProperty = "id")
代码实现:
1 2 3 4 5 6 7 @Mapper public interface EmpMapper {@Options(useGeneratedKeys = true,keyProperty = "id") @Insert("insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) values (#{username}, #{name}, #{gender}, #{image}, #{job}, #{entrydate}, #{deptId}, #{createTime}, #{updateTime})") public void insert (Emp emp) ;
D. 更新(修改)
接口方法:
1 2 3 4 5 6 7 8 9 @Mapper public interface EmpMapper {@Update("update emp set username=#{username}, name=#{name}, gender=#{gender}, image=#{image}, job=#{job}, entrydate=#{entrydate}, dept_id=#{deptId}, update_time=#{updateTime} where id=#{id}") public void update (Emp emp) ;
测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @SpringBootTest class SpringbootMybatisCrudApplicationTests {@Autowired private EmpMapper empMapper;@Test public void testUpdate () {Emp emp = new Emp ();23 );"songdaxia" );null );"老宋" );"2.jpg" );short )1 );short )2 );2012 ,1 ,1 ));null );2 );
E. 查询 1. 根据ID查询
接口方法:
1 2 3 4 5 @Mapper public interface EmpMapper {@Select("select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time from emp where id=#{id}") public Emp getById (Integer id) ;
测试类:
1 2 3 4 5 6 7 8 9 10 11 @SpringBootTest class SpringbootMybatisCrudApplicationTests {@Autowired private EmpMapper empMapper;@Test public void testGetById () {Emp emp = empMapper.getById(1 );
而在测试的过程中,我们会发现有几个字段(deptId、createTime、updateTime)是没有数据值的
2. 数据封装
实体类属性名和数据库表查询返回的字段名一致,mybatis会自动封装。
如果实体类属性名和数据库表查询返回的字段名不一致,不能自动封装。
起别名:在SQL语句中,对不一样的列名起别名,别名和实体类属性名一样。
1 2 @Select("select id, username, password, name, gender, image, job, entrydate, dept_id deptld, create_time createTime, update_time updateTime from emp where id = #{id} ") public Emp getByld (Integer id) ;
手动结果映射:通过@Results及@Result进行手动结果映射。
1 2 3 4 5 6 @Select("select * from emp where id = #{id}") @Results({ @Result(column ="dept_id", property = "deptld"), @Result(column ="create_time", property = "createTime"), @Result(column ="update_time", property = "updateTime")}) public Emp getByld (Integer id) ;
开启驼峰命名(推荐):如果字段名与属性名符合驼峰命名规则,mybatis会自动通过驼峰命名规则映射
1 2 case =true
3. 条件查询 解决SQL注入风险,使用MySQL提供的字符串拼接函数:concat('%' , '关键字' , '%')
1 2 3 4 5 6 7 8 9 @Mapper public interface EmpMapper {@Select("select * from emp " + "where name like concat('%',#{name},'%') " + "and gender = #{gender} " + "and entrydate between #{begin} and #{end} " + "order by update_time desc") public List<Emp> list (String name, Short gender, LocalDate begin, LocalDate end) ;
6. XML映射文件 Mybatis的开发有两种方式:
注解
XML
在Mybatis中使用XML映射文件方式开发,需要符合一定的规范:
XML映射文件的名称与Mapper接口名称一致,并且将XML映射文件和Mapper接口放置在相同包下(同包同名)
XML映射文件的namespace属性为Mapper接口全限定名一致
XML映射文件中sql语句的id与Mapper接口中的方法名一致,并保持返回类型一致
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "https://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace ="com.itheima.mapper.EmpMapper" > <select id ="list" resultType ="com.itheima.pojo.Emp" > </select > </mapper >
MybatisX是一款基于IDEA的快速开发Mybatis的插件
7. MyBatis动态SQL SQL语句会随着用户的输入或外部条件的变化而变化,我们称为:动态SQL
A. <if>
<if>用于判断条件是否成立。使用test属性进行条件判断,如果条件为true,则拼接SQL<where>:只会在子元素有内容的情况下才插入where子句,而且会自动去除子句的开头的AND或OR<set>:动态地在行首插入 SET 关键字,并会删掉额外的逗号。(用在update语句中)
1 2 3 <if test ="条件表达式" > </if >
1 2 3 4 5 6 7 <select id ="list" resultType ="com.itheima.pojo.Emp" > </select >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 <select id ="list" resultType ="com.itheima.pojo.Emp" > <where > <if test ="name != null" > </if > <if test ="gender != null" > </if > <if test ="begin != null and end != null" > </if > </where > </select >
测试:
1 2 3 4 5 6 7 8 @Test public void testList () {null , (short )1 , null , null );for (Emp emp : list){
B. foreach 员工删除功能(既支持删除单条记录,又支持批量删除)<foreach>遍历deleteByIds方法中传递的参数ids集合
1 2 3 <foreach collection ="集合名称" item ="集合遍历出来的元素/项" separator ="每一次遍历使用的分隔符" open ="遍历开始前拼接的片段" close ="遍历结束后拼接的片段" > </foreach >
1 2 3 4 5 6 <delete id ="deleteByIds" > <foreach collection ="ids" item ="id" separator ="," open ="(" close =")" > </foreach > </delete >
C. sql&include 我们可以对重复的代码片段进行抽取,将其通过<sql>标签封装到一个SQL片段,然后再通过<include>标签进行引用。
<sql>:定义可重用的SQL片段<include>:通过属性refid,指定包含的SQL片段
SQL片段: 抽取重复的代码
1 2 3 <sql id ="commonSelect" > </sql >
通过<include>标签在原来抽取的地方进行引用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <select id ="list" resultType ="com.itheima.pojo.Emp" > <include refid ="commonSelect" /> <where > <if test ="name != null" > </if > <if test ="gender != null" > </if > <if test ="begin != null and end != null" > </if > </where > </select >
六. 事务管理 1. 事务回顾 事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体,一起向数据库提交或者是撤销操作请求。所以这组操作要么同时成功,要么同时失败 。
事务的操作主要有三步:
开启事务(一组操作开始前,开启事务):start transaction / begin;
提交事务(这组操作全部成功后,提交事务):commit ;
回滚事务(中间任何一个操作出现异常,回滚事务):rollback ;
2. Spring事务管理 Transactional注解方法执行完毕之后提交事务 。如果在这个方法执行的过程当中出现了异常,就会进行事务的回滚操作
@Transactional注解:我们一般会在业务层当中来控制事务 ,因为在业务层当中,一个业务功能可能会包含多个数据访问的操作。在业务层来控制事务,我们就可以将多个数据访问操作控制在一个事务范围内。
@Transactional注解书写位置:
方法:当前方法交给spring进行事务管理
类:当前类中所有的方法都交由spring进行事务管理
接口:接口下所有的实现类当中所有的方法都交给spring 进行事务管理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Slf4j @Service public class DeptServiceImpl implements DeptService {@Autowired private DeptMapper deptMapper;@Autowired private EmpMapper empMapper;@Override @Transactional public void delete (Integer id) {int i = 1 /0 ;
可以在application.yml配置文件中开启事务管理日志,这样就可以在控制看到和事务相关的日志信息了
1 2 3 4 logging: level: org.springframework.jdbc.support.JdbcTransactionManager: debug
3. rollbackFor(异常回滚) 在Spring的事务管理中,默认只有运行时异常 RuntimeException才会回滚。如果还需要回滚指定类型的异常,可以通过rollbackFor属性来指定。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Slf4j @Service public class DeptServiceImpl implements DeptService {@Autowired private DeptMapper deptMapper;@Autowired private EmpMapper empMapper;@Override @Transactional(rollbackFor=Exception.class) public void delete (Integer id) {int num = id/0 ;
4. propagation A. 事务传播行为 就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行事务控制。
1 2 3 4 @Transactional (propagation = Propagation.REQUIREDpublic void b () {
常用属性值
含义
REQUIRED
【默认值】需要事务,有则加入,无则创建新事务
REQUIRES_NEW
需要新事务,无论有无,总是创建新事务
REQUIRED :大部分情况下都是用该传播行为
REQUIRES_NEW :当我们不希望事务之间相互影响时,可以使用该传播行为。比如:下订单前需要记录日志,不论订单保存成功与否,都需要保证日志记录能够记录成功。
七. AOP 1. AOP基础 A. AOP介绍 面向特定方法编程
AOP常见的应用场景如下:
AOP面向切面编程的一些优势:
代码无侵入:没有修改原始的业务方法,就已经对原始的业务方法进行了功能的增强或者是功能的改变
减少了重复代码
提高开发效率
维护方便
B. AOP核心概念
连接点:JoinPoint,可以被AOP控制的方法(暗含方法执行时的相关信息)
通知:Advice,指哪些重复的逻辑,也就是共性功能(最终体现为一个方法)
切入点:PointCut,匹配连接点的条件,通知仅会在切入点方法执行时被应用
切面:Aspect,描述通知与切入点的对应关系(通知+切入点)
目标对象:Target,通知所应用的对象
Spring的AOP底层是基于动态代理技术来实现的,也就是说在程序运行的时候,会自动的基于动态代理技术为目标对象生成一个对应的代理对象。在代理对象当中就会对目标对象当中的原始方法进行功能的增强。
2. AOP进阶 A. 通知类型 Spring中AOP的通知类型:
@Around:环绕通知,此注解标注的通知方法在目标方法前、后都被执行
@Before:前置通知,此注解标注的通知方法在目标方法前被执行
@After :后置通知,此注解标注的通知方法在目标方法后被执行,无论是否有异常都会执行
@AfterReturning : 返回后通知,此注解标注的通知方法在目标方法后被执行,有异常不会执行
@AfterThrowing : 异常后通知,此注解标注的通知方法发生异常后执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 @Slf4j @Component @Aspect public class MyAspect1 {@Pointcut("execution(* com.itheima.service.*.*(..))") private void pt () {@Before("pt()") public void before (JoinPoint joinPoint) {"before ..." );@Around("pt()") public Object around (ProceedingJoinPoint proceedingJoinPoint) throws Throwable {"around before ..." );Object result = proceedingJoinPoint.proceed();"around after ..." );return result;@After("pt()") public void after (JoinPoint joinPoint) {"after ..." );@AfterReturning("pt()") public void afterReturning (JoinPoint joinPoint) {"afterReturning ..." );@AfterThrowing("pt()") public void afterThrowing (JoinPoint joinPoint) {"afterThrowing ..." );
B. 通知顺序
不同的切面类当中,默认情况下通知的执行顺序是与切面类的类名字母排序是有关系的
可以在切面类上面加上@Order注解,来控制不同的切面类通知的执行顺序
C. 切入点表达式 主要用来决定项目中的哪些方法需要加入通知
1. execution execution主要根据方法的返回值、包名、类名、方法名、方法参数等信息来匹配,语法为:execution(访问修饰符? 返回值 包名.类名.?方法名(方法参数) throws 异常?)(带?的可以省略)
示例:
1 2 @Before("execution(void com.itheima.service.impl.DeptServiceImpl.delete(java.lang.Integer))") public void before (JoinPoint joinPoint) {}
可以使用通配符描述切入点
*:单个独立的任意符号,可以通配任意返回值、包名、类名、方法名、任意类型的一个参数,也可以通配包、类、方法名的一部分.. :多个连续的任意符号,可以通配任意层级的包,或任意类型、任意个数的参数
2. @annotation 用于匹配标识有特定注解的方法@annotation(com.itheima.anno.Log)
1 2 3 4 @Before("@annotation(com.itheima.anno.Log)") public void before () {"before.." ) ;
D. 连接点 在Spring中用JoinPoint抽象了连接点,用它可以获得方法执行时的相关信息,如目标类名、方法名、方法参数等。
对于@Around通知,获取连接点信息只能使用ProceedingJoinPoint类型
对于其他四种通知,获取连接点信息只能使用JoinPoint,它是ProceedingJoinPoint的父类型
八. Springboot原理篇 1. 配置优先级 SpringBoot项目当中支持的三类配置文件和两种配置方法:
application.properties
application.yml
application.yaml
Java系统属性配置 (格式: -Dkey=value)(-Dserver.port=9000)
命令行参数 (格式:–key=value)(–server.port=10010)
配置优先级排名(从高到低):
命令行参数
Java系统属性配置
properties配置文件
yml配置文件(常用)
yaml配置文件
2. Bean管理 A. 获取Bean 默认情况下,SpringBoot项目在启动的时候会自动的创建IOC容器(也称为Spring容器),并且在启动的过程当中会自动的将bean对象都创建好,存放在IOC容器当中。应用程序在运行时需要依赖什么bean对象,就直接进行依赖注入就可以了。
根据name获取beanObject getBean(String name)
根据类型获取bean<T> T getBean(Class<T> requiredType)
根据name获取bean(带类型转换)<T> T getBean(String name, Class<T> requiredType)
B. Bean作用域
在Spring中支持五种作用域,后三种在web环境才生效:
作用域
说明
singleton
容器内同名称的bean只有一个实例(单例)(默认)
prototype
每次使用该bean时会创建新的实例(非单例)
可以借助Spring中的@Scope注解来进行配置作用域
1 2 3 4 @Scope("prototype") @RestController @RequestMapping("/depts") public class DeptController {}
C. 第三方bean 如果要管理的bean对象来自于第三方(不是自定义的),是无法用@Component 及衍生注解声明bean的,就需要用到@Bean注解。
在启动类上添加@Bean标识的方法
1 2 3 4 5 6 7 8 9 10 11 12 @SpringBootApplication public class SpringbootWebConfig2Application {public static void main (String[] args) {@Bean public SAXReader saxReader () {return new SAXReader ();
在配置类中定义@Bean标识的方法
1 2 3 4 5 6 7 8 9 10 @Configuration public class CommonConfig {@Bean public SAXReader reader (DeptService deptService) {return new SAXReader ();
3. SpringBoot原理 A. 起步依赖 原理就是maven的依赖传递
B. 自动配置 1. 自动配置的概述 SpringBoot的自动配置就是当Spring容器启动后,一些配置类、bean对象就自动存入到了IOC容器中,不需要我们手动去声明,从而简化了开发,省去了繁琐的配置操作。
2. 自动配置的原理 方案一: @ComponentScan组件扫描
1 2 3 4 @SpringBootApplication @ComponentScan({"com.itheima","com.example"}) public class SpringbootWebConfig2Application {
方案二:@Import导入.使用@Import导入的类会被Spring加载到IOC容器中
导入普通类,交给IOC管理
导入配置类
导入ImportSelector接口实现类
@EnableXxxx注解,封装@Import注解
@Conditional注解 :
作用:按照一定的条件进行判断,在满足给定条件后才会注册对应的bean对象到Spring的IOC容器中。
位置:方法、类
@Conditional本身是一个父注解,派生出大量的子注解:
@ConditionalOnClass:判断环境中有对应字节码文件,才注册bean到IOC容器。
@ConditionalOnMissingBean:判断环境中没有对应的bean(类型或名称),才注册bean到IOC容器。
@ConditionalOnProperty:判断配置文件中有对应属性和值,才注册bean到IOC容器。
1 2 3 4 5 6 7 8 9 10 11 @Bean @ConditionalOnClass(name="io.jsonwebtoken.Jwts") public HeaderParser headerParser () { ... }@Bean @ConditionalOnMissingBean public HeaderParser headerParser () { ... }@Bean @ConditionalOnProperty(name="name",havingValue="itheima") public HeaderParser headerParser () { ... }
4. WEB后端开发总结
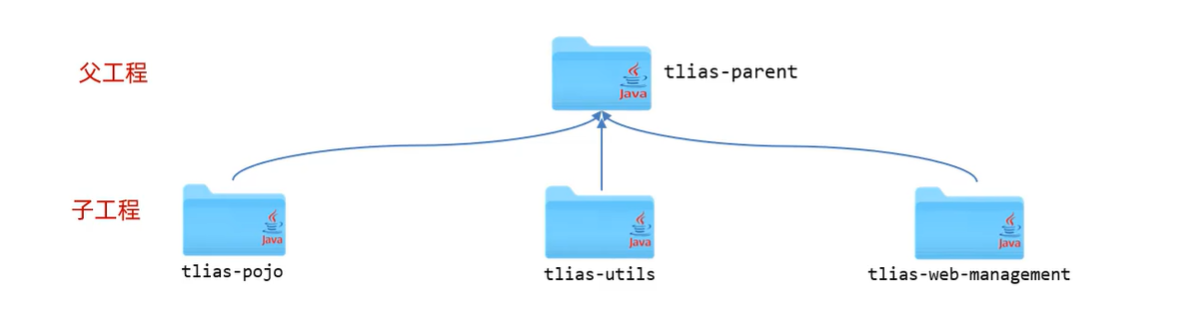
九. Maven高级 1. 分模块设计与开发 将项目按照功能拆分为若干个子模块,方便项目的管理维护、扩展,方便模块间的相互调用、资源共享
2. 继承与聚合 A. 继承 1. 继承的介绍
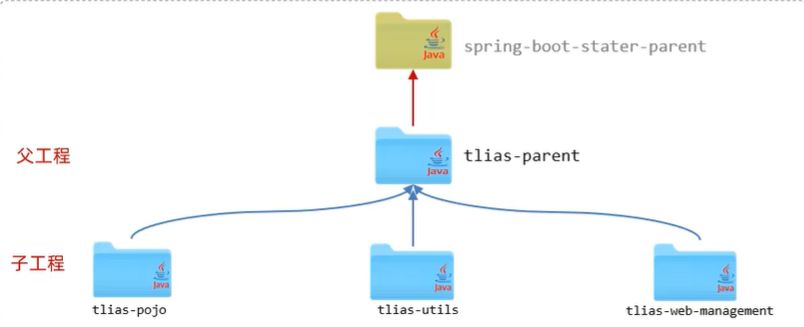
概念:继承描述的是两个工程间的关系,与java中的继承相似,子工程可以继承父工程中的配置信息,常见于依赖关系的继承。
作用:简化依赖配置、统一管理依赖
实现 :<parent> ..</parent>
2. 继承关系实现
创建maven模块tlias-parent,该工程为父工程,设置打包方式pom(默认jar)。
在子工程的pom.xml文件中,配置继承关系。
在父工程中配置各个工程共有的依赖(子工程会自动继承父工程的依赖)。
3. 版本锁定 在maven中,可以在父工程的pom文件中通过<dependencyManagement>来统一管理依赖版本。
在父工程中:
1 2 3 4 5 6 7 8 9 10 <dependencyManagement > <dependencies > <dependency > <groupId > io.jsonwebtoken</groupId > <artifactId > jjwt</artifactId > <version > 0.9.1</version > </dependency > </dependencies > </dependencyManagement >
<dependencyManagement>与<dependencies>的区别是什么?
<dependencies>是直接依赖,在父工程配置了依赖,子工程会直接继承下来。<dependencyManagement>是统一管理依赖版本,不会直接依赖,还需要在子工程中引入所需依赖(无需指定版本)
B. 聚合
父工程(聚合工程)
1 2 3 4 5 6 <modules > <module > .. /tlias-pojo</module > <module > .. /tlias-utils</module > <module > .. /tlias-web-management</module > </modules >
C. 继承与聚合的关联
作用
聚合用于快速构建项目
继承用于简化依赖配置、统一管理依赖
相同点:
聚合与继承的pom.xml文件打包方式均为pom,可以将两种关系制作到同一个pom文件中
聚合与继承均属于设计型模块,并无实际的模块内容
不同点:
聚合是在聚合工程中配置关系,聚合可以感知到参与聚合的模块有哪些
继承是在子模块中配置关系,父模块无法感知哪些子模块继承了自己
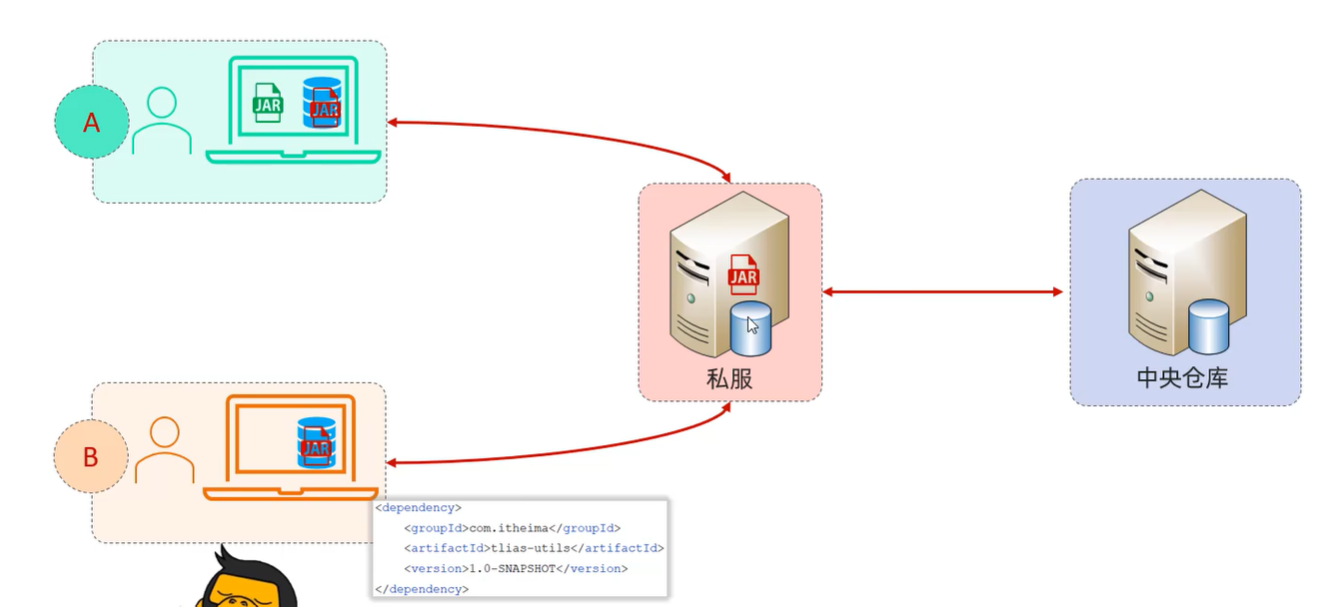
3. 私服 私服是一种特殊的远程仓库,它是架设在局域网内的仓库服务,用来代理位于外部的中央仓库,用于解决团队内部的资源共享与资源同步问题。
依赖查找顺序:
END